







目录
2.新建一个labelme2voc.py,将如下代码复制进去。
3.新建一个labels.txt文件,将你要标注的标签填入,如果不晓得咋整就把如下代码复制进去。
1.在labelme安装目录下找到json_to_dataset.py文件
3.用第1步的方法找到labelme_json_to_dataset.exe文件
4.4标注好的文件在D:\ProgramData\Anaconda3\envs\labelm\Scripts文件夹里面
准备工作:
1.安装anaconda
先去清华镜像网站下载anaconda并将其安装anaconda,安装在d盘下的program目录下面。
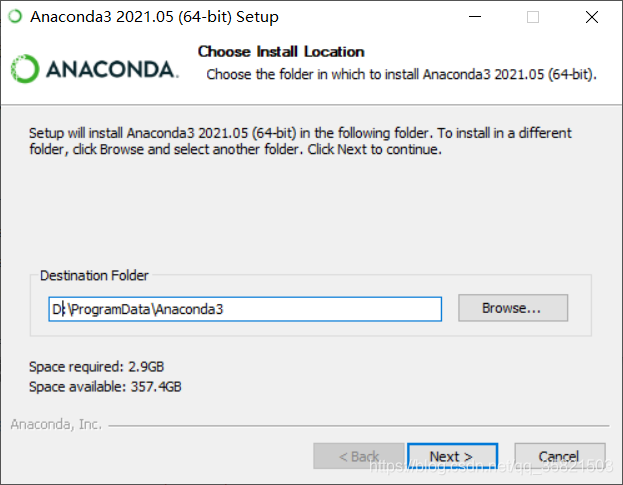
然后必须要勾选添加环境变量,不然安装好后要手动添加。
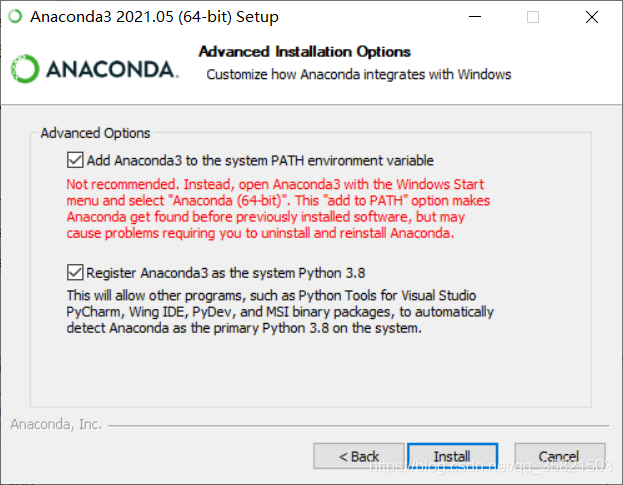
2.安装labelme
2.1创建labelme的环境
打开anaconda powershell prompt,输入python -V查看python的版本,从下图可以看到本人的python是3.8版本。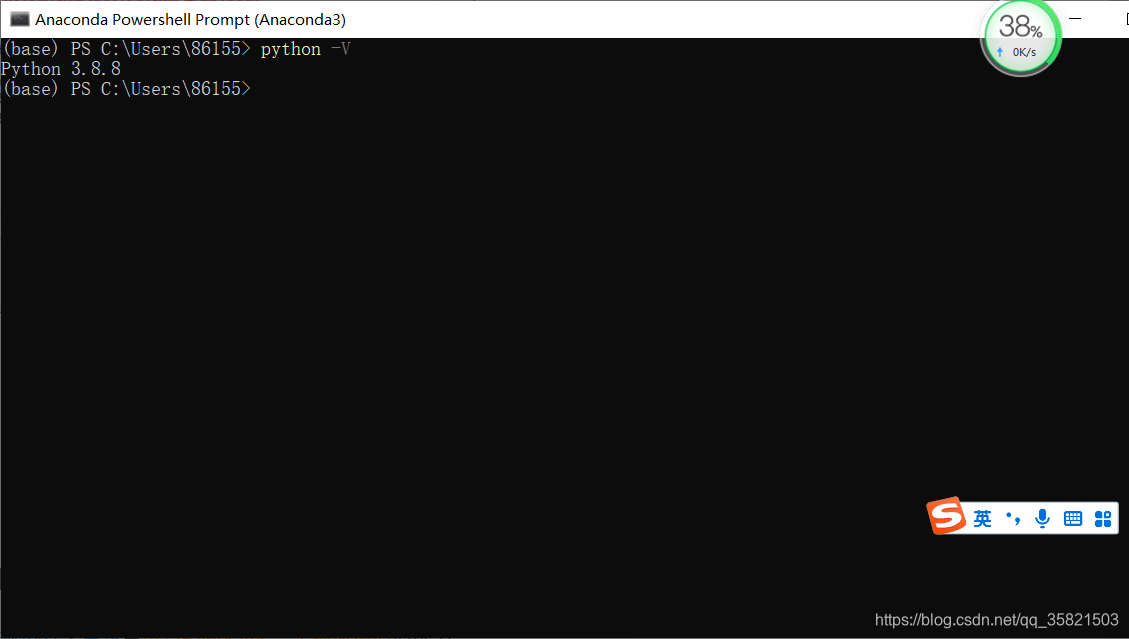
然后输入指令:conda create --name=labelme python=3.8
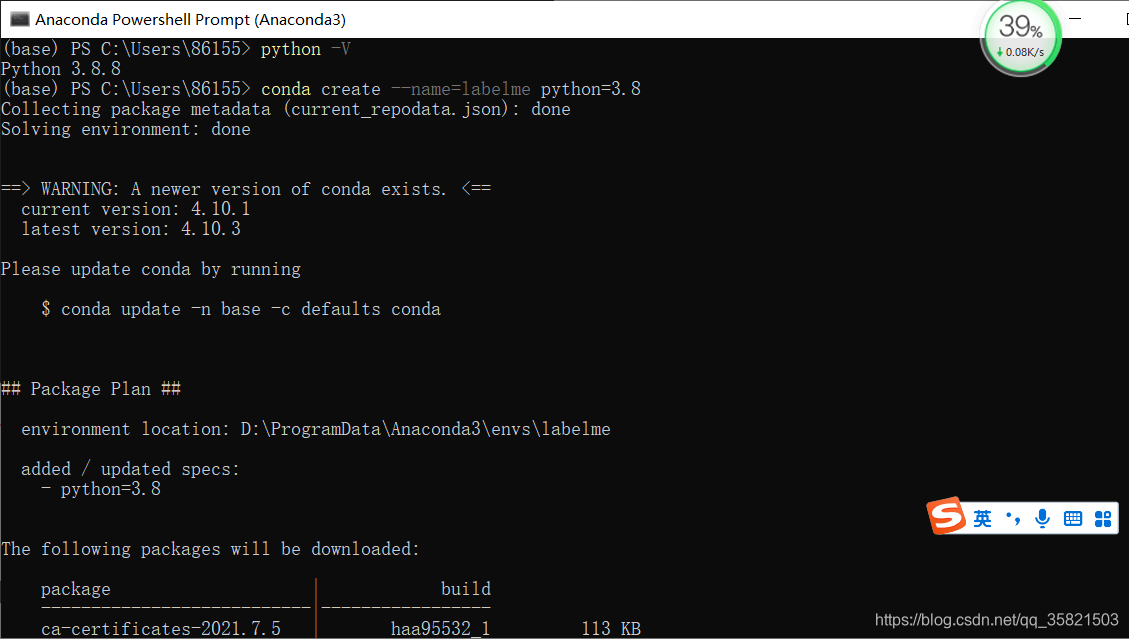
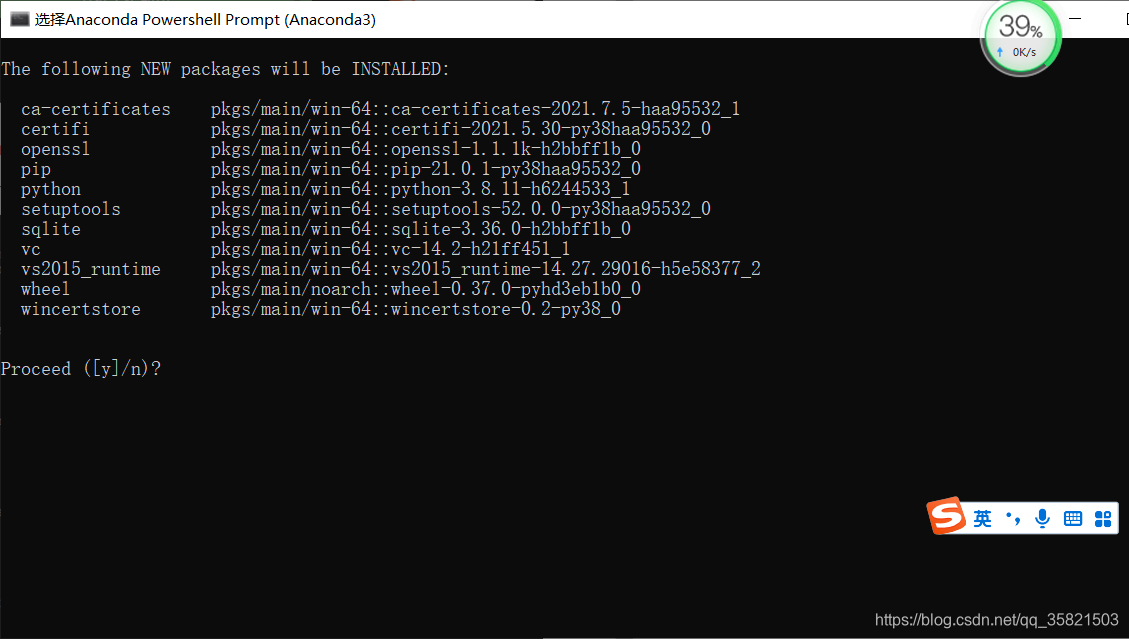
输入y 后,会自己下载了。
方法一:
1.将文件存入china文件夹下的taiwan文件夹中。
2.新建一个labelme2voc.py,将如下代码复制进去。
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
label=lbl,
img=imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()3.新建一个labels.txt文件,将你要标注的标签填入,如果不晓得咋整就把如下代码复制进去。
__ignore__
_background_
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
potted plant
sheep
sofa
train
foot
eyes
head
tv/monitor
然后文件结构就变成了这个样子:
4.激活labelme的环境
输入指令:conda activate labelme,最前面的(base),变成了(labelme)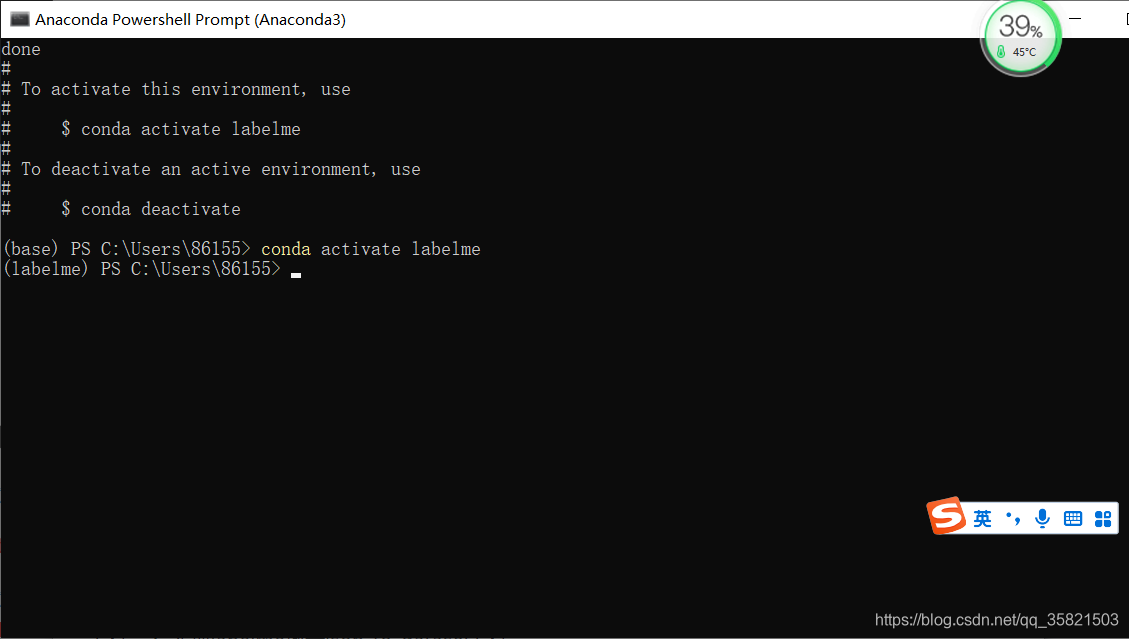
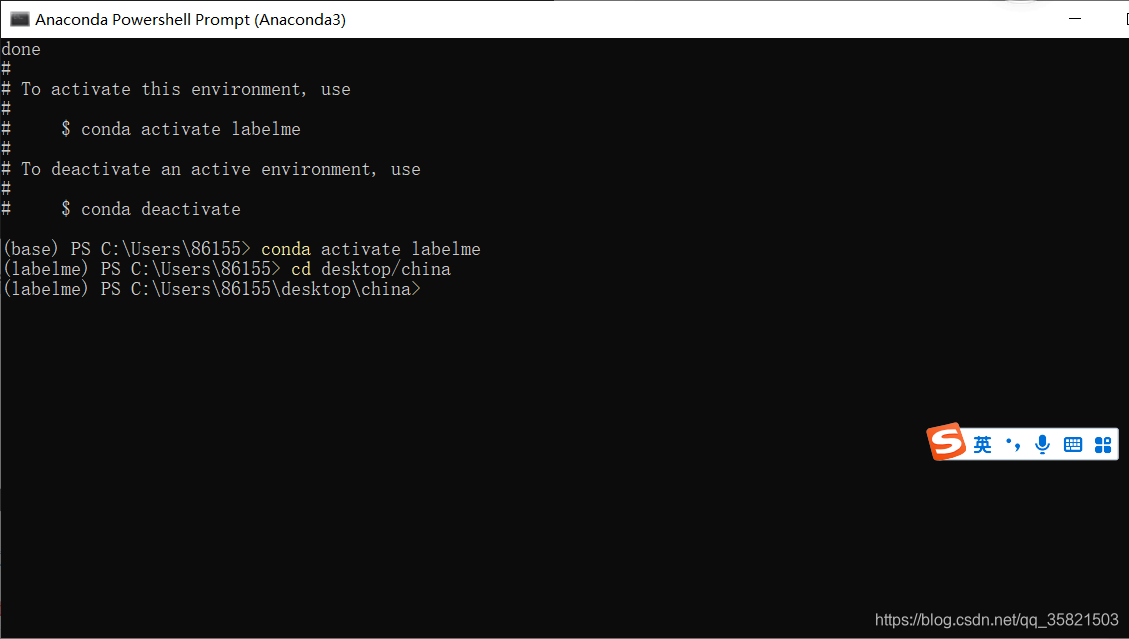
5.切换路径至你的图片的存储路径:
cd desktop/china
6.打开labelme,且打开taiwan文件夹开始标注:
labelme taiwan --labels labels.txt --nodata --validatelabel exact --config '{shift_auto_shape_color: -2}'
7.传入.json文件路径,执行转换
./labelme2voc.py taiwan guizhou --labels labels.txt
其中taiwan是装图片的文件夹,guizhou是放标注的文件夹,config后面和-2前面都有空格
8.标注好的文件就在guizhou这个文件夹里面了
方法二:
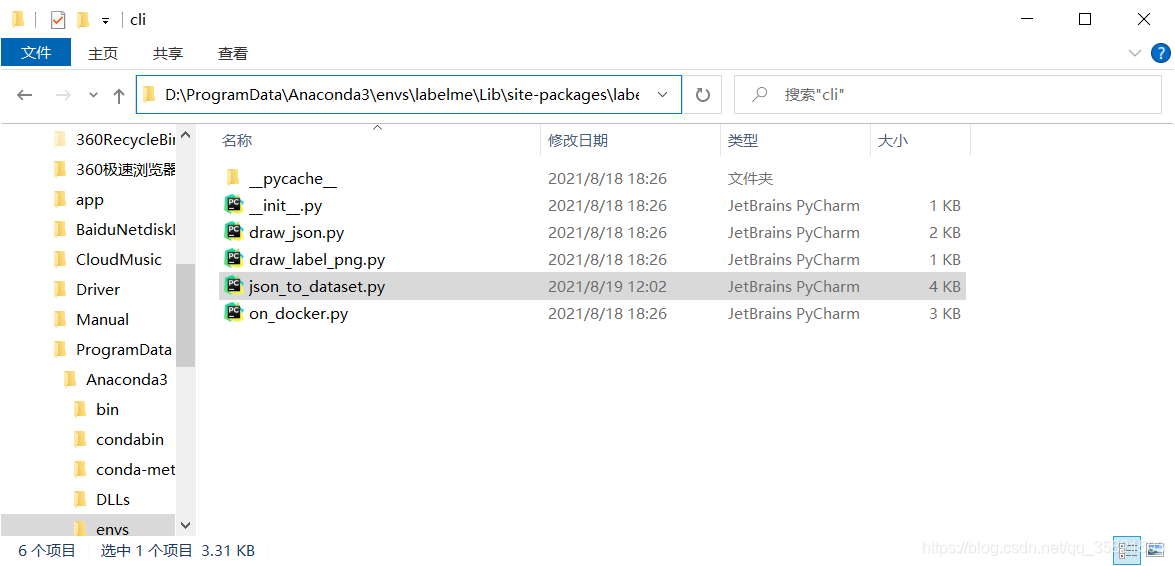
1.在labelme安装目录下找到json_to_dataset.py文件
情况一:anaconda的安装环境是默认的安装目录且没有给labelme一个虚拟环境情况下:
C:\ProgramData\Anaconda3\Lib\site-packages\labelme\cli
情况二:anaconda的安装环境是默认的安装目录但是给labelme创建了一个虚拟环境情况下:C:\ProgramData\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli
情况三:anaconda的安装环境不是默认的安装目录且没有给labelme一个虚拟环境情况下:
你安装的anocanda的地方\Anaconda3\Lib\site-packages\labelme\cli
情况四:anaconda的安装环境不是默认的安装目录但是给labelme创建了一个虚拟环境情况下:
需要找到ananonda安装目录下的envs文件夹中的虚拟环境文件,本人的就是:
D:\ProgramData\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli
2.修改json_to_dataset.py文件
将json_to_dataset.py文件里的所以代码替换为以下代码
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
count = os.listdir(json_file)
for i in range(0, len(count)):
path = os.path.join(json_file, count[i])
if os.path.isfile(path):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(count[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(count[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
#PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
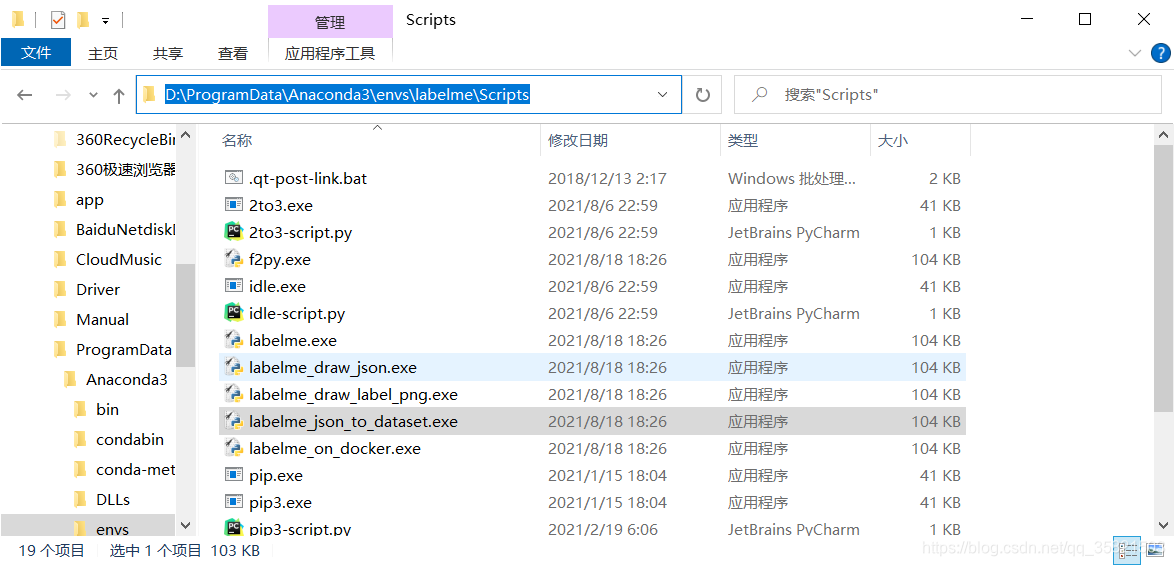
3.用第1步的方法找到labelme_json_to_dataset.exe文件
情况一:anaconda的安装环境是默认的安装目录且没有给labelme一个虚拟环境情况下:
C:\ProgramData\Anaconda3\labelme\Scripts
情况二:anaconda的安装环境是默认的安装目录但是给labelme创建了一个虚拟环境情况下:C:\ProgramData\Anaconda3\envs\labelme\Scripts
情况三:anaconda的安装环境不是默认的安装目录且没有给labelme一个虚拟环境情况下:
你安装的anocanda的地方\Anaconda3\labelme\Scripts打开anaconda prompt,激活虚拟环境
情况四:anaconda的安装环境不是默认的安装目录但是给labelme创建了一个虚拟环境情况下:
需要找到ananonda安装目录下的envs文件夹中的虚拟环境文件,本人的就是:
D:\ProgramData\Anaconda3\envs\labelm\Scripts
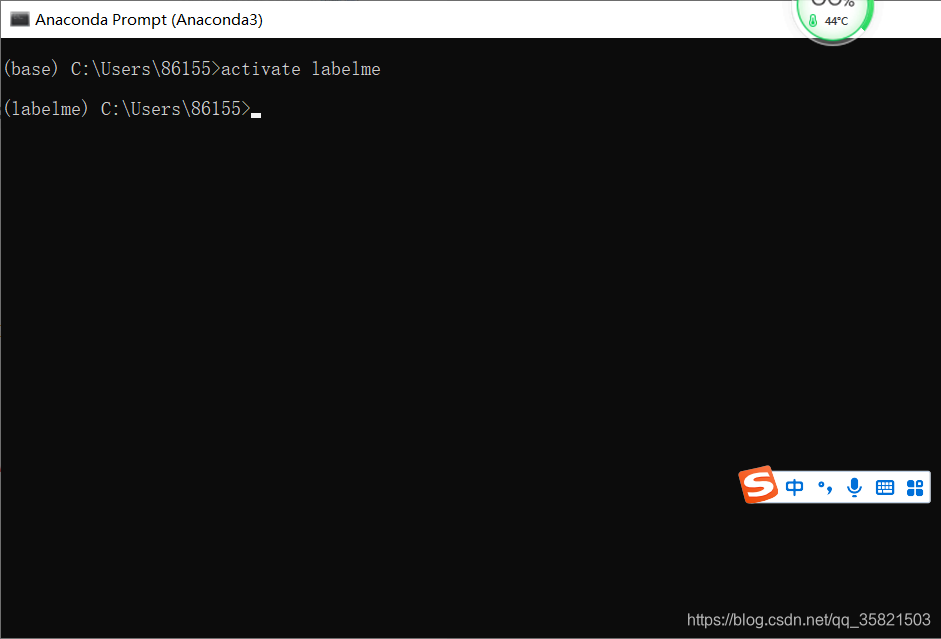
4.打开anaconda prompt,输入以下指令
4.1.如果有虚拟环境的进入(激活)虚拟环境:
输入命令:
activate labelme
4.2切换路径至步骤3的目录地址
4.2.1因为本人的anaconda安装在了D盘所以得先将路径从C盘切换到D盘(如果你的anaconda安装在c盘这步就不需要):
输入命令:
d:
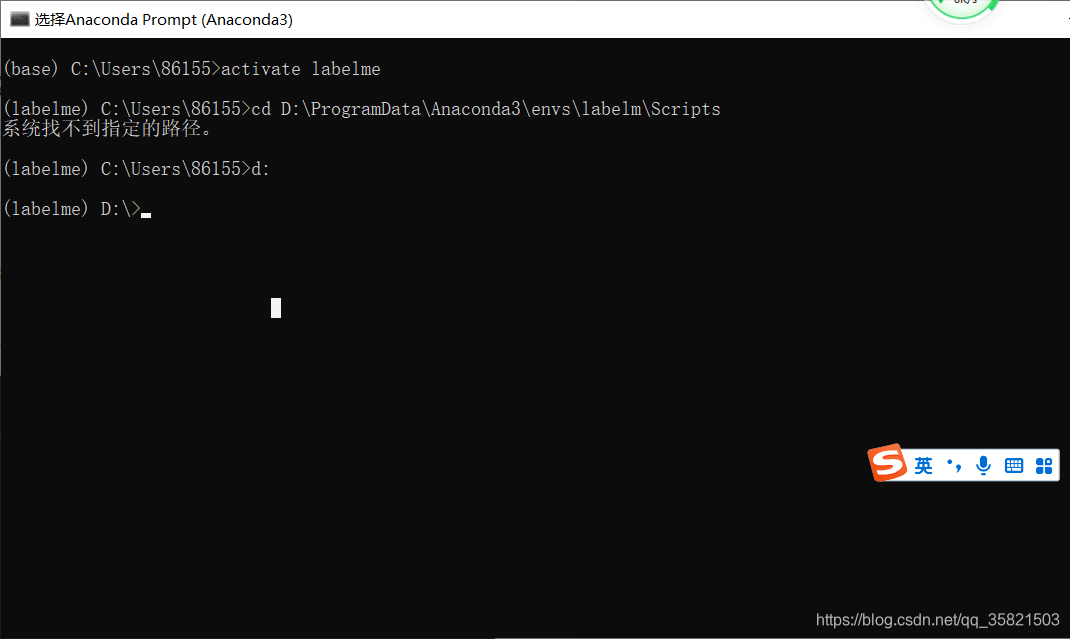
注意:如果你的anaconda不是安装在c盘你执行4.2.1的命令,而是直接执行4.2.3的命令,那你就会出现下面的错误:
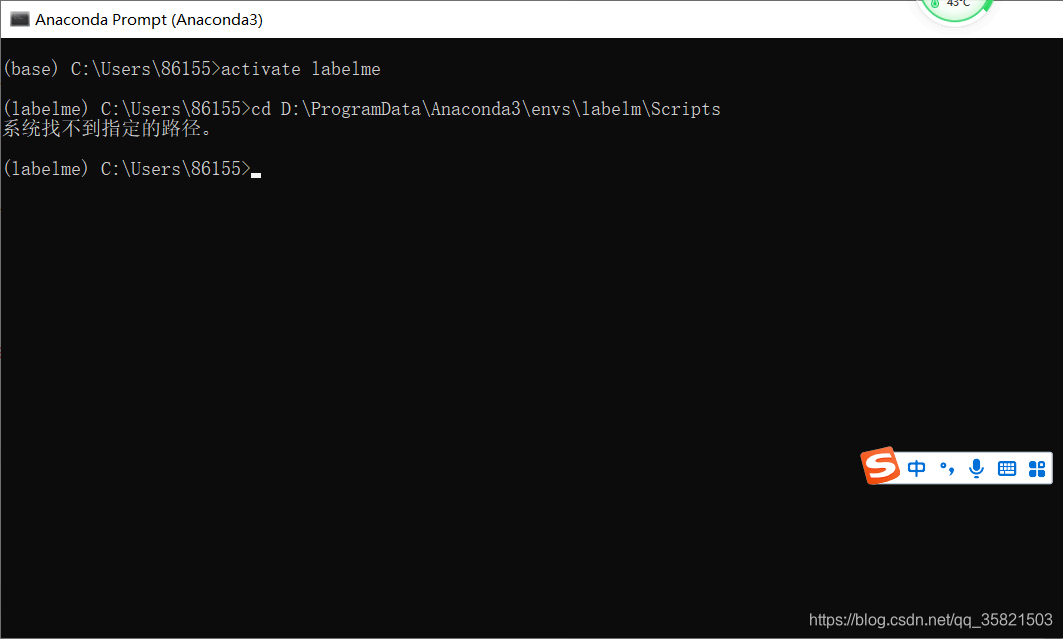
4.2.2本人的步骤3的路径是D:\ProgramData\Anaconda3\envs\labelm\Scripts
所以,我的命令是:
cd D:\ProgramData\Anaconda3\envs\labelm\Scripts
注意:此处直接复制就报错,必须要cd 自己打,然后复制路径进去才对
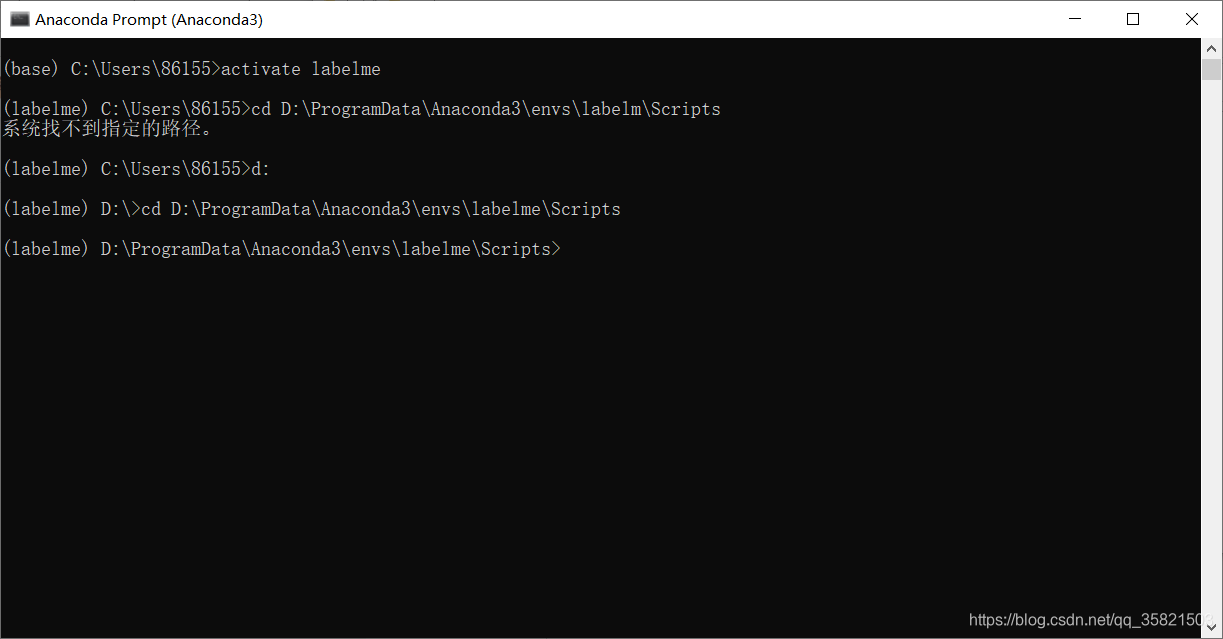
4.3传入.json文件路径,执行转换
注意:此处的.json文件必须是将所有需要转化的json文件保存在一个只有json文件的目录下,不可以像下图这种是不对的。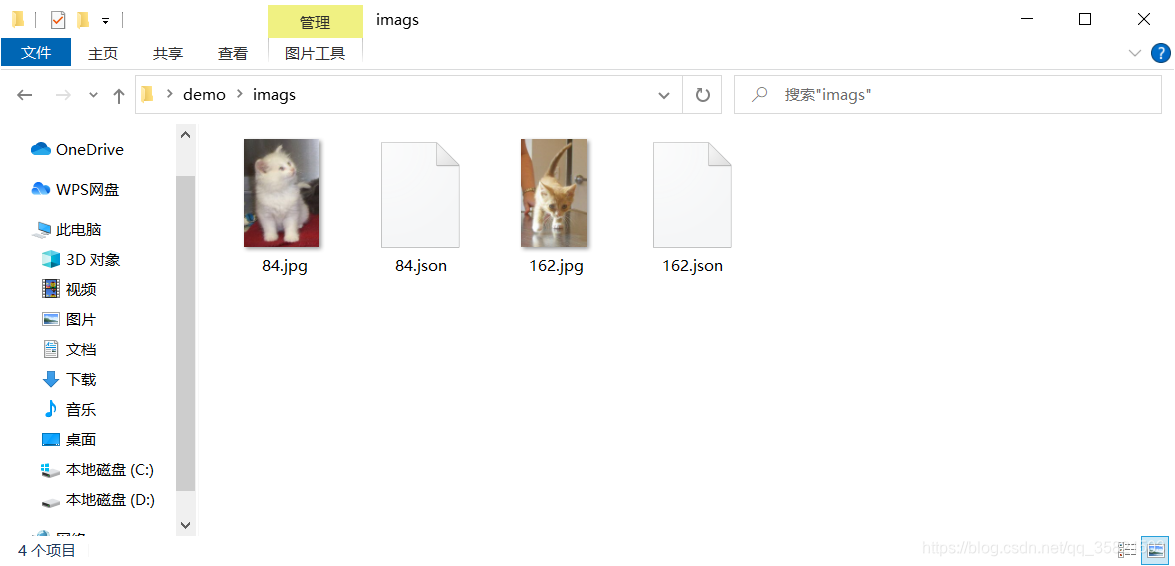
下图这种才可以: 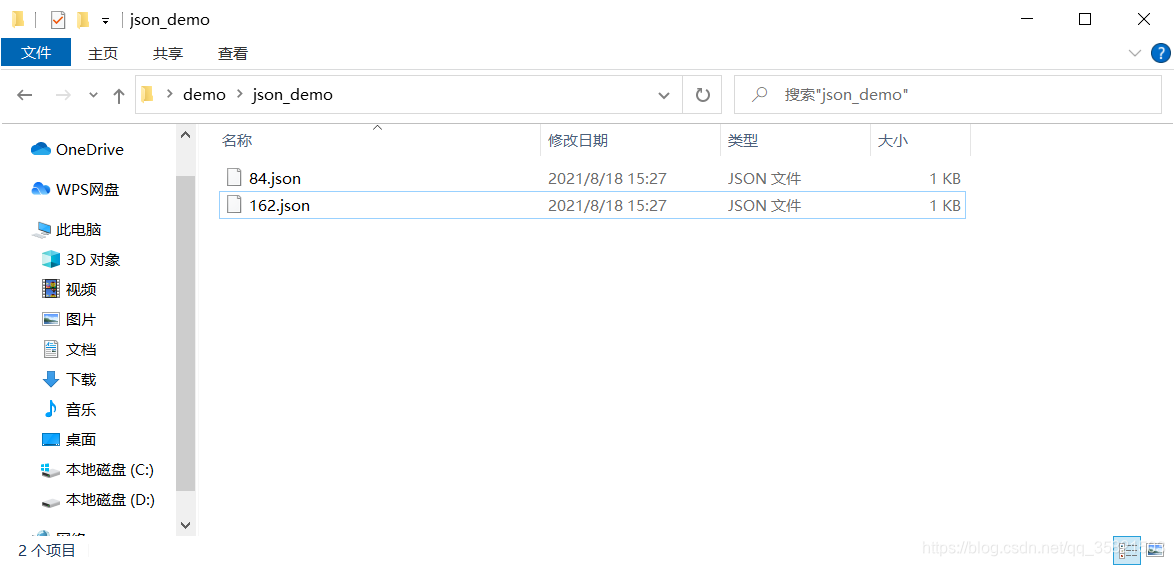
然后输入命令:
labelme_json_to_dataset.exe +你放的json文件的目录
本人的是:
labelme_json_to_dataset.exe D:\demo\json

















 6398
6398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









