







论文:https://dl.acm.org/doi/pdf/10.1145/3503250
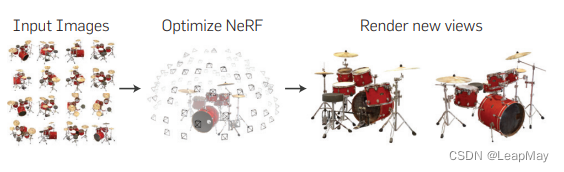
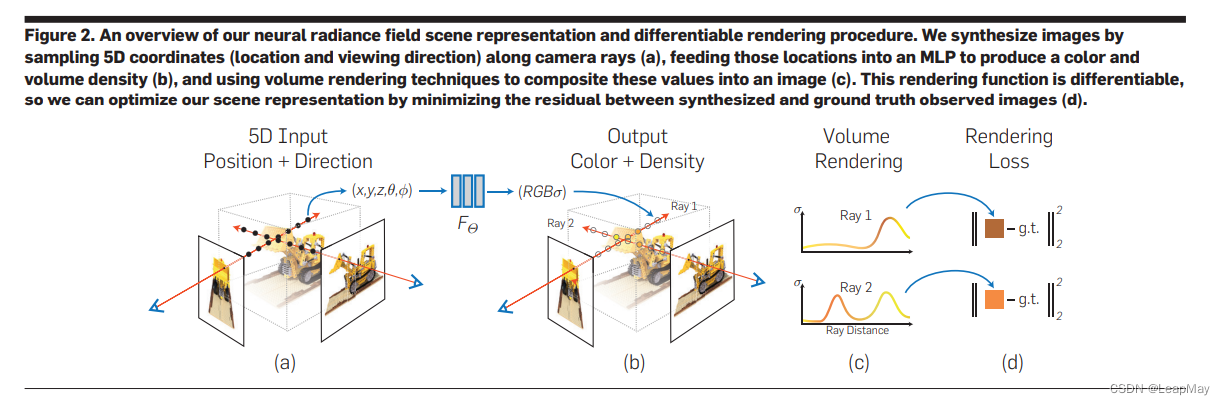
项目速览:
config //存放不同数据集训练的参数
download_example_data.sh //下载数据集
load_blender.py
load_deepvoxel.py
load_LINEMOD.py
load_llff.py
//加载预处理不同格式的数据集,会在run_nerf.py中得到调用;
run_nerf.py //网络训练和渲染,主函数是程序的入口,从当中的train()函数开始运行。
run_nerf_helpers.py //构造一些run_nerf.py需要的组件函数
1.数据加载
(1)数据集格式和内容
LLFF(Layered Light Field Flow)数据集: LLFF数据集是用于视角一致性和深度学习重建的数据集。它包含通过拍摄相机移动的图像序列和深度图像。每个场景的图像序列捕捉了不同视角下的场景外观,而深度图像提供了场景的几何信息。LLFF数据集提供了相机参数、图像序列和深度图像,可以用于训练和评估视角一致性和深度估计算法。
Blender数据集: Blender数据集是使用Blender软件生成的数据集,其中包含虚拟场景的三维模型、材质、相机参数以及渲染的图像。这些数据可以用于训练和评估三维重建、渲染、视觉SLAM等算法。
LINEMOD数据集: LINEMOD(LINEmod Object Detection)数据集是用于物体检测和位姿估计的数据集。它包含多个物体的RGB图像和相应的标注信息,例如物体的二维边界框和位姿。LINEMOD数据集用于训练和评估物体检测和位姿估计算法,旨在解决物体在复杂背景下的检测和定位问题。
DeepVoxel数据集: DeepVoxel数据集是用于稠密三维重建的数据集。它包含了真实场景的RGB图像和深度图像,可以用于训练和评估三维重建算法,例如基于体素表示的方法。DeepVoxel数据集提供了场景的多视图图像和深度信息,可用于生成高质量的三维重建结果。
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
从load_llff_data 中取出的pose 是一个(20,3,5)的list。20代表一共有20张image,3×5是每一个image 的pose matrix
hwf = poses[0,:3,-1] // 取出前三行最后一列元素(红色部分)
poses = poses[:,:3,:4] // 取出pose里的平移和旋转部分
....中间代码略去.......
H, W, focal = hwf // 分别赋予 Hieight、Width、focal
关于poses_bounds.npy 解释:这个文件存储这一个numpy 的数组:N×17,N 是图像的数量,17 个元素将会被转化为 3*5 的矩阵和两个深度值:视角 到 场景的最近和最远距离。
blender 数据集 lego 的读取
介绍代码中的一个参数:arg.white_bkgd:
在Blender 的数据集图像有四个通道RGBA,其中A表示的是alpha通道,一般情况下就是两个取值【0,1】,当alpha=0 表示该处的pixel是透明的;当alpha=1 表示该处的pixel是不透明的。 而 white_bkgd 这个参数就是负责将透明像素的部分转化为白色的背景,转化的代码部分如下:
if args.white_bkgd:
images = images[...,:3]*images[...,-1:] + (1.-images[...,-1:])
代码的解读:
images是Normalize到【0,1】之间的图像,当alpha=0(也就是 images[…,-1:] = 0 ),那么images的像素将设置为1(纯白色);当alpha=1的时候,那么images的像素的就是本来的RGB通道对应的颜色。
llff
blender
LINEMOD
DeepVoxel
该数据集包含四个具有简单几何结构的朗伯对象(Lambertian objects)。视图为512×512像素,每个对象从上半球(the upper hemisphere)采样的视点渲染(479个作为输入,1000用于测试)。
nerf_synthetic
其中包含八个对象的路径跟踪图像(pathtraced images),这些对象具有复杂的几何结构和逼真的非朗伯材质(non-Lambertian materials)。六个从上半球上采样的视点渲染,两个从整个球体上采样的点渲染。Nerf渲染每个场景的100个视图作为输入,200个视图用于测试,所有视图均为800×800像素。
def train():
# 添加参数并解析参数
parser = config_parser()
args = parser.parse_args()
# 声明内参矩阵K
# Load data
K = None
# 由这里调用了load_blender_data函数加载数据,在load_blender.py中给出了该函数的定义
if args.dataset_type == 'llff':
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
hwf = poses[0,:3,-1]
poses = poses[:,:3,:4]
print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)
if not isinstance(i_test, list):
i_test = [i_test]
if args.llffhold > 0:
print('Auto LLFF holdout,', args.llffhold)
i_test = np.arange(images.shape[0])[::args.llffhold]
i_val = i_test
i_train = np.array([i for i in np.arange(int(images.shape[0])) if
(i not in i_test and i not in i_val)])
print('DEFINING BOUNDS')
if args.no_ndc:
near = np.ndarray.min(bds) * .9
far = np.ndarray.max(bds) * 1.
else:
near = 0.
far = 1.
print('NEAR FAR', near, far)
elif args.dataset_type == 'blender':
images, poses, render_poses, hwf, i_split = load_blender_data(args.datadir, args.half_res, args.testskip)
print('Loaded blender', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test = i_split
near = 2.
far = 6.
if args.white_bkgd:
images = images[...,:3]*images[...,-1:] + (1.-images[...,-1:])
else:
images = images[...,:3]
elif args.dataset_type == 'LINEMOD':
images, poses, render_poses, hwf, K, i_split, near, far = load_LINEMOD_data(args.datadir, args.half_res, args.testskip)
print(f'Loaded LINEMOD, images shape: {images.shape}, hwf: {hwf}, K: {K}')
print(f'[CHECK HERE] near: {near}, far: {far}.')
i_train, i_val, i_test = i_split
if args.white_bkgd:
images = images[...,:3]*images[...,-1:] + (1.-images[...,-1:])
else:
images = images[...,:3]
elif args.dataset_type == 'deepvoxels':
images, poses, render_poses, hwf, i_split = load_dv_data(scene=args.shape,
basedir=args.datadir,
testskip=args.testskip)
print('Loaded deepvoxels', images.shape, render_poses.shape, hwf, args.datadir)
i_train, i_val, i_test = i_split
hemi_R = np.mean(np.linalg.norm(poses[:,:3,-1], axis=-1))
near = hemi_R-1.
far = hemi_R+1.
else:
print('Unknown dataset type', args.dataset_type, 'exiting')
return
Nerf 网络的搭建:
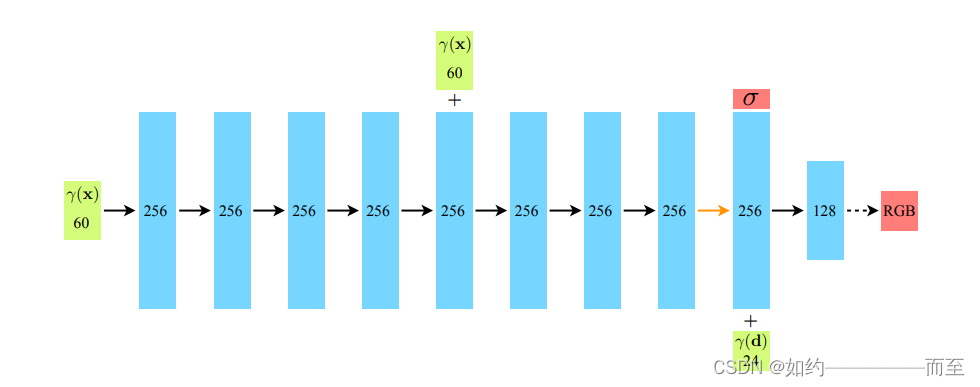
input: layer = 0,Position Encoding 后的长度为 63 的vector
layer =9 时,将第8层的输出(channel=256)和 direction 进行Postion Encoding 之后(channel=27)进行concat
Output: 第8层的 density 为 alpha 的输出 和第10层的 rgb 3channel 的输出
netdepth = 8 , netwidth = 256 , input_ch = 63,是指position输入的维度(position encoding 之后的编码),skip = 4, 是因为在论文中 第5层出现了 skip connection.
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
Nerf 的 网络构建代码如下:
















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











