







目录
一、概述
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
二、线性可分支持向量机
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?其实很简单,在二维空间中就是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。我们看一个简单的二维空间的例子,O代表正类,X代表负类,样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条,我们所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。
通俗解释:找到一个条线(w和b),使得离该线最近的点能够最远
2.1 SVM要解决的问题
要解决的问题:
- 什么样的决策边界才是最好的呢?支持向量机
- 特征数据本身如果就很难分,怎么办呢?
- 计算复杂度怎么样?能实际应用吗?

决策边界:选出来离雷区最远的(雷区就是边界上的点,要Large Margin)

2.2 距离计算

SVM中关键的就是离线最近的点能够最远,所以我们要求的是线(这个栗子是平面)到点的距离
假设空间中3点,X,X1,X11 因为X1,X11在同一个平面上,可以得到
![]()
![]()
距离distance是垂直这个平面的,可以得出:

就可以得出:
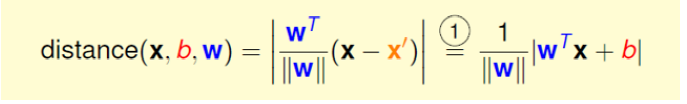
2.3 优化的目标
数据集:(X1,Y1)(X2,Y2)…(Xn,Yn)
Y为样本的类别:当X为正例时候Y = +1 当X为负例时候Y = -1
决策方程:![]()
(这里不是x,而是Φ(x),原因是核变换。具体原因会在第三大点讲到,先把Φ(x)当做x,用心看下去,你会豁然开朗。)
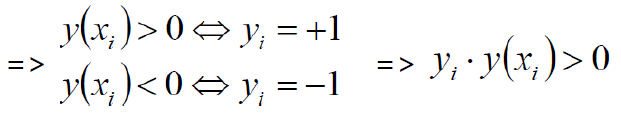

![]()
2.4 目标函数
放缩变换:对于决策方程(w,b)可以通过放缩使得其结果值|Y|>= 1

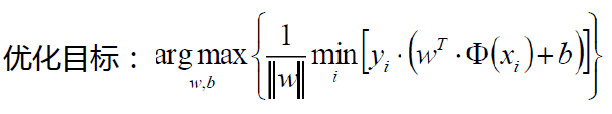
找到一个条线(w和b),使得离该线最近的点能够最远

当前目标:
常规套路:将求解极大值问题转换成极小值问题
最后目标函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









