








采集flume:taildir source kafka channel:减少了sink,提高了效率
消费flume:kafka channel hdfs sink:减少了source,提高了效率
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.rollInterval = 10 # 基于时间间隔来进行文件滚动,默认是30S,0表示不使用
a1.sinks.k1.hdfs.rollSize = 134217728 #基于文件大小来进行文件滚动,这里设置128M
a1.sinks.k1.hdfs.rollCount = 0 #基于Event来进行文件滚动,0表示不使用
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
一、flume组成、put事务、task事务
1、taildir source
1)断点续传,多目录
2)没有断点续传怎么办?自定义
3)taildir挂了怎么办?
不会丢数据,断点续传,数据重复。
4)怎么处理重复的数据?
不处理,生产情况通常不处理,因为会影响传输效率,在下一级处理用hive之类的去重。
5)taildir source是否支持递归遍历文件夹读取文件?
不支持,自定义遍历文件夹+读取文件
6)batchsize大小如何设置?
Event 1k左右,500-1000合适(默认为100)
2、file channel memory channel kafka channel
1)file channel
数据存储于磁盘。
优势:可靠性高。劣势:传输速度低。
容量:100万Event。
注意:FileChannel可以通过设置dataDirs指向多个路径,每个路径对应不同的磁盘,增大Flume吞吐量。
2)memory channel
数据存储于内存。
优势:传输速率快。劣势:可靠性差。
默认容量:100个Event。
3)kafka channel
数据存储于kafka,基于磁盘。
优势:可靠性高。传输速度快:kafka channel>memory channel+kafka sink。
传输速度快的 原因:省去了sink阶段。
4)生产环境如何选择
如果下一级是kafka,有限选择kafka channel。
如果是金融,对钱要求准确的公司,选择file channel。
如果就是普通日志,通常选择memory channel。
每天丢几百万数据pb级处理吗?
1pb比100万条=1亿条比100条,亿万富翁丢100块是不会捡的。
3、HDFS sink
滚动:文件生成,即关闭当前文件,创建新文件。
1)时间1小时
2)大小为128M
3)Event个数(默认为0表示禁止)
4、agent
source+channel+sink 就是一个Agent
5、事务
Source到Channel是Put事务
Channel到Sink是Take事务
二、flume拦截器
1.例子:判断传输的json串是否完整



2.自定义拦截器步骤
1)实现Intercepter
2)重写四个方法:
【1】initiallize
【2】public Event intercept(Event event)
处理单个Event
【3】public List<Event> itercept(List<Event> events)
处理多个event,在这个方法中调用Event intercept(Event event)
【4】close方法
3)静态内部类,实现Interceptor.Builder
3.拦截器可以不用吗
可以不用,需要在下一级hive的dwd层或SparkStreming里面处理。
4.Time Intercepter用来解决零点漂移问题
参考
业务数据采集_零点漂移处理方法(Flume+Kafka+HDFS)_徐一闪_BigData的博客-CSDN博客
1)问题
flume从日志文件拉取数据有一定的时间
由于Flume默认会用Linux系统时间作为传输到HDFS的时间,如果数据是23:59:59产生的,Flume拉取数据的时候可能是00:00:03,那么这部分数据会被发往第二天的HDFS路径。我们希望的是根部日志里面的实际时间发往HDFS路径,所以下面的拦截器作用是获取日志中的实际时间。

2)解决思路
拦截json日志,解析event body中的json,获取实际时间ts,将获取的ts时间写入拦截器header头,header的key必须是timestamp。Flume框架会自动根据这个key值识别为时间,写入HDFS。
3)代码
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}三、选择器
1、什么是选择器
Channel Selectors可以让不同的项目日志通过不同的Channel到不同的Sink中去。
有两种Channel Selectors:
1)Replicating Channel Selector(default)
2)Mutiplexing Channel Selector
2、replication(复制)
可以将数据复制多份,分别传递到多个Channel中,每个Channel接受到的数据都是相同的。
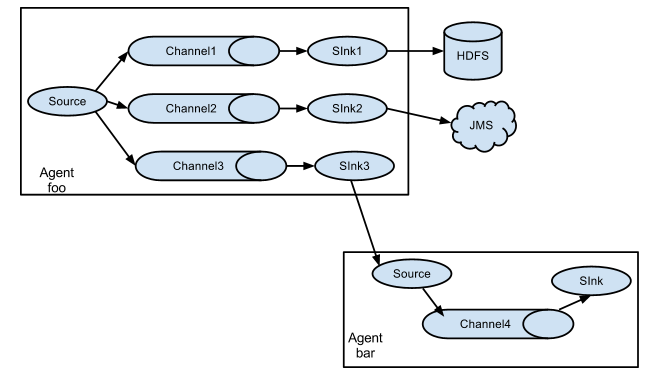
这种方式的配置主要有两个key:

a1.sources = r1
a1.channels = c1 c2 c3
a1.sources.r1.selector.type = replicating
a1.sources.r1.channels = c1 c2 c3
#这意味着c3是可选的,向c3写入失败会被忽略。但是向c1,c2写入失败会出错
a1.sources.r1.selector.optional = c33、multiplexing(分流)
Selector可以根据header的值来确定数据传递到哪个channel,其中header的值可以通过interceptor去设置。如果现在还不明白拦截器,就把它当做能在header中添加一个key-value对的东西就可以。

假如我们通过拦截器向header中添加了key为state的一个属性,他的值根据具体需求可以为CZ和US等,那我们想把值为CZ的数据流通过C1处理,把值为US的数据通过C2,C3处理,其他情况用C4。则flume.conf配置如下:
a1.sources = r1
a1.channels = c1 c2 c3 c4
#设置selector类型
a1.sources.r1.selector.type = multiplexing
#设置根据header中的什么key去分流
a1.sources.r1.selector.header = state
#设置根据key的具体值选择哪个channel
a1.sources.r1.selector.mapping.CZ = c1
a1.sources.r1.selector.mapping.US = c2 c3
#设置默认channel
a1.sources.r1.selector.default = c4四、Sink Processors(处理器)
有3中sink processor
1、default sink processor
默认的sink processor,一个sink
2、failover sink processor
一个sink组多个sink,sink组内的sink有优先级。
event先往sink1里发,这个sink出问题了,再发送到另一个sink2,等之前那个sink1好了,再将sink2中的数据发往sink1。
#define sinkgroups
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=k1 k2
a1.sinkgroups.g1.processor.type=failover
#在Sink中的两个数据为优先级分别设置默认为5、10,数字越大越优先
a1.sinkgroups.g1.processor.priority.k1=10
a1.sinkgroups.g1.processor.priority.k2=5
a1.sinkgroups.g1.processor.maxpenalty=100003、load balancing sink processor负载均衡
一个sink组有多个sink,event按照轮询,或者随机的形式均匀的发送给多个sink。
#define sinkgroups
#这里定义的就是Processor
a1.sinkgroups=g1
a1.sinkgroups.g1.sinks=k1 k2
#类型为负载均衡
a1.sinkgroups.g1.processor.type=load_balance
#是否指数增长超时恢复时间
a1.sinkgroups.g1.processor.backoff=true
#选择下一个sink的算法
a1.sinkgroups.g1.processor.selector=round_robin五、Flume监控器
采用监控器Gangelia,监控到Flume尝试提交的次数远远大于最终成功的次数,说明flume运行比较差。
解决方法
1)自身增加内存 flume-env.sh 4-6G
2)-Xmx(程序使用的内存)与-Xms(程序初始化时内存的大小,设置这个会让启动性能提高)最好设置一致,减少内存抖动带来的性能影响,如果设置不一致会导致频繁垃圾回收。
3)增加服务器台数
六、Flume采集数据会丢失吗(防止数据丢失的机制)
如果是FlileChannel不会,Channel存储可以存储在File中,数据传输自身有事务。
如果是MemoryChannel可能会丢。
七、Flume如何保证数据的完整性
Flume是以事务为单位进行处理的,默认100个Event为以批次。
1)Source-Channel事务
当前批次的Event全部写入Channel,该事务就完成了。
2)Channel-Sink事务
当其中有一个Event没有成功,这个事务会将处理的处理的这一批次所有的Events全部回滚到Channel中,重新传输。














 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









