







三者的意义
- 训练数据:用来训练模型的数据
- 验证数据:用来检验模型准确率
- 测试数据:再一次确认验证数据集中的模型是好的模型。
一般步骤:
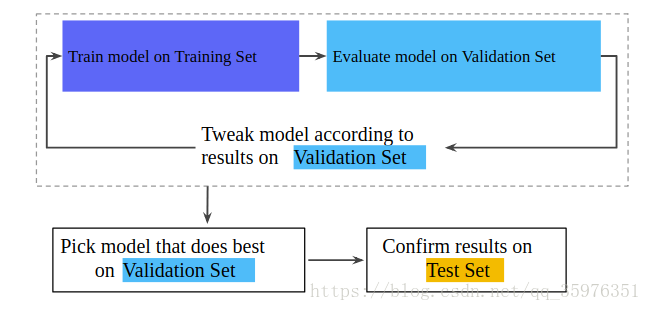
测试数据集和验证数据的数据一定不能用来训练,否则会出现过拟合的现象
代码:
import math
import os
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.INFO)
pd.options.display.max_rows = 10
# 读取数据
if os.path.exists('data.csv'):
california_housing_dataframe = pd.read_csv('data.csv', sep=',')
else:
california_housing_dataframe = pd.read_csv(
"https://storage.googleapis.com/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe.to_csv('data.csv')
def preprocess_features(california_housing_dataframe):
'''
准备输入测试数据特征列
:param california_housing_dataframe:
:return:
'''
selected_features = california_housing_dataframe[
[
'latitude',
'longitude',
'housing_median_age',
'total_rooms',
'total_bedrooms',
'population',
'households',
'median_income'
]
]
processed_features = california_housing_dataframe.copy()
# 添加人均住房面积
processed_features['rooms_per_person'] = (
california_housing_dataframe['total_rooms'] /
california_housing_dataframe['population']
)
return processed_features
def preprocess_targets(california_housing_dataframe):
'''
目标值输入函数
:param california_housing_dataframe:
:return: 房子的价值
'''
output_targets = pd.DataFrame()
output_targets['median_house_value'] = (
california_housing_dataframe['median_house_value'] / 1000.0
)
return output_targets
# 传入12000组数据
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_examples.describe()
# 传入12000组目标值
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
training_targets.describe()
# 验证数据集
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_examples.describe()
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
validation_targets.describe()
plt.figure(figsize=(13, 8))
ax = plt.subplot(1, 2, 1)
ax.set_title("Validation Data")
ax.set_ylim([32, 43])
ax.set_autoscalex_on(False)
ax.set_xlim([-126, -112])
plt.scatter(validation_examples['longitude'],
validation_examples['latitude'],
cmap="coolwarm",
c=validation_targets['median_house_value'] / training_targets['median_house_value'].max()
)
plt.plot()
def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
'''
输入函数
:param features: 特征列
:param targets: 目标值
:param batch_size: batch size
:param shuffle: 是否乱序
:param num_epochs: epoch的数量
:return: 一个迭代批次数据,包含特征列和标签
'''
ds = Dataset.from_tensor_slices((dict(features), targets))
ds = ds.batch(batch_size=batch_size)
if shuffle:
ds.shuffle(buffer_size=10000)
features, labels = ds.make_one_shot_iterator().get_next()
return features, labels
def construct_feature_columns(input_features):
'''
:param input_features:特征
:return: 构造的特征列
'''
return set([tf.feature_column.numeric_column(key=my_feature)
for my_feature in input_features])
def train_model(learning_rate,
steps,
batch_size,
training_examples,
training_targets,
validation_examples,
validation_targets):
periods = 10
steps_per_period = steps // periods
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)
linear_regressor = tf.estimator.LinearRegressor(
feature_columns=construct_feature_columns(training_examples),
optimizer=my_optimizer
)
print("Training model.....")
training_rmse = []
validation_rmse = []
for period in range(0, periods):
# 开始训练
linear_regressor.train(
input_fn=lambda: my_input_fn(
training_examples,
training_targets['median_house_value'],
batch_size=batch_size
),
steps=steps_per_period
)
# 预测数据集的处理
training_predictions = linear_regressor.predict(
input_fn=lambda: my_input_fn(
training_examples,
training_targets['median_house_value'],
num_epochs=1,
shuffle=False
)
)
training_predictions = np.array([item['predictions'][0] for item in training_predictions])
# 验证数据集的处理
validation_predictions = linear_regressor.predict(
input_fn=lambda: my_input_fn(
validation_examples,
validation_targets['median_house_value'],
num_epochs=1,
shuffle=False
)
)
validation_predictions = np.array([item['predictions'][0] for item in validation_predictions])
tmp_training_rmse = math.sqrt(
metrics.mean_squared_error(training_predictions, training_targets)
)
tmp_validation_rmse = math.sqrt(
metrics.mean_squared_error(validation_predictions, validation_targets)
)
print("period %02d: %0.2f" % (period, tmp_training_rmse))
training_rmse.append(tmp_training_rmse)
validation_rmse.append(tmp_validation_rmse)
print("Model training finished")
# 输出结果图
plt.ylabel("RMSE")
plt.xlabel("Periods")
plt.title("Root Mean Squred Error vs. Periods")
plt.tight_layout()
plt.plot(training_rmse, labels="training")
plt.plot(validation_rmse, labels="validation")
plt.legend()
return linear_regressor
# 训练模型
linear_regressor = train_model(
learning_rate=0.00003,
steps=500,
batch_size=1,
training_examples=training_examples,
training_targets=training_targets,
validation_examples=validation_examples,
validation_targets=validation_targets
)
# 在测试数据集上评估模型
california_housing_test_data = pd.read_csv('data.csv', sep=',')
test_examples = preprocess_features(california_housing_test_data)
test_targets = preprocess_targets(california_housing_test_data)
predict_test_input_fn = lambda: my_input_fn(
test_examples,
test_targets['median_house_value'],
num_epochs=1,
shuffle=False
)
test_predictions = linear_regressor.predict(input_fn=predict_test_input_fn)
test_predictions = np.array([item['predictions'][0] for item in test_predictions])
RMSE = math.sqrt(
metrics.mean_squared_error(test_predictions, test_targets)
)
print("Final RMSE (on test data): %0.2f" % RMSE)

















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









