







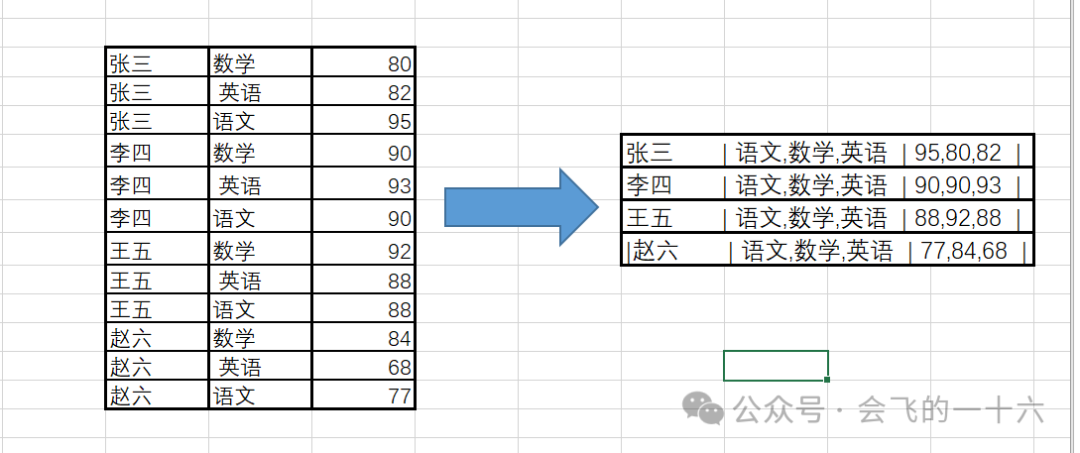
有如下需求,需要将左边的表变换成右边的表,注意字段内容的顺序及对应内容的一致性。
第一个字段为name,第二个字段为subject,第三个字段为score,变换后要求subject按照语文、数学、英语排列,且score和subject之间内容保持一一对应。
数据准备
with data as (select '张三' as name , '数学' as subject , 80 as score union allselect '张三' as name , '英语' as subject , 82 as score union allselect '张三' as name , '语文' as subject , 95 as score union allselect '李四' as name , '数学' as subject , 90 as score union allselect '李四' as name , '英语' as subject , 93 as score union allselect '李四' as name , '语文' as subject , 90 as score union allselect '王五' as name , '数学' as subject , 92 as score union allselect '王五' as name , '英语' as subject , 88 as score union allselect '王五' as name , '语文' as subject , 88 as score union allselect '赵六' as name , '数学' as subject , 84 as score union allselect '赵六' as name , '英语' as subject , 68 as score union allselect '赵六' as name , '语文' as subject , 77 as score)
02
数据分析
题目考察的是行转列,但是难度要比简单行转列要复杂很多。本题首先要求subject顺序按照语文、数学及英语排列,其次score中的对应分值内容必须和subject保持一一对应。看似老生常谈的问题,但实则面试通过率并不高,因为候选人往往忽略了有序性及内容的一一对应。
如果我们直接进行行转列,看看会有什么结果:
select name, concat_ws(',',collect_list(subject)) sub, concat_ws(',',collect_list(cast(score as string))) scofrom data
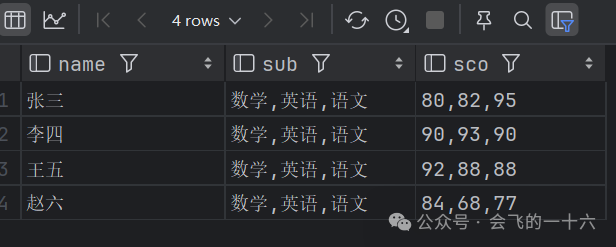
在hive中collect_list()函数并不能像其他数据库中如 group_concat()函数等可以指定字段的顺序,collect_list()在大数据体系下遇到shuffle过程还可能出现乱序。因此为了保证顺序性,我们先按照规则进行指定排序,语文标为1,数学标为2,英语标为3,具体如下SQL所示
select name, subject, score, case when subject ='语文' then 1when subject ='数学' then 2when subject ='英语' then 3end seqfrom data
其次,我们采用concat_ws()+collect_list() ove()函数 进行数据行转列,注意此处采用的是collect_list() ove()分析函数,目的是为了能够在窗口中指定顺序,保证合并数据的有序性。具体SQL如下:
select name,seq,concat_ws(',', collect_list(subject) over (partition by name order by seq)) subject,concat_ws(',', collect_list(cast(score as string)) over (partition by name order by seq)) scorefrom (select name, subject, score, casewhen subject = '语文' then 1when subject = '数学' then 2when subject = '英语' then 3end seqfrom data) t
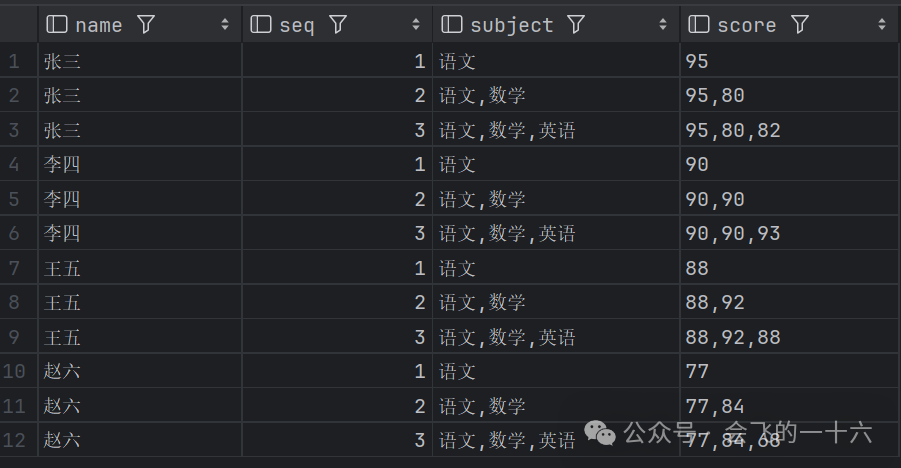
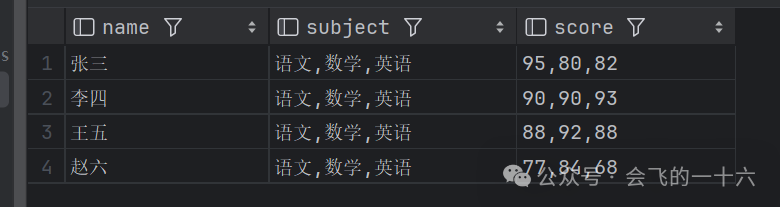
由于窗口函数 collect_list() ove()在滑动的过程中会针对每行数据都会生成一个记录,通过上面结果我们可以看到只有seq等于3的时候,才是我们想要的结果,因此我们对上述结果进行过滤,获得最终的SQL如下:
with data as (select '张三' as name , '数学' as subject , 80 as score union allselect '张三' as name , '英语' as subject , 82 as score union allselect '张三' as name , '语文' as subject , 95 as score union allselect '李四' as name , '数学' as subject , 90 as score union allselect '李四' as name , '英语' as subject , 93 as score union allselect '李四' as name , '语文' as subject , 90 as score union allselect '王五' as name , '数学' as subject , 92 as score union allselect '王五' as name , '英语' as subject , 88 as score union allselect '王五' as name , '语文' as subject , 88 as score union allselect '赵六' as name , '数学' as subject , 84 as score union allselect '赵六' as name , '英语' as subject , 68 as score union allselect '赵六' as name , '语文' as subject , 77 as score)select--过滤符合条件的结果name,subject,scorefrom (select name,seq,--指定合并时候排序规则,保证有序性concat_ws(',', collect_list(subject) over (partition by name order by seq)) subject,concat_ws(',', collect_list(cast(score as string)) over (partition by name order by seq)) scorefrom (select name, subject, score---步骤1:基于排序规则,指定排序顺序, casewhen subject = '语文' then 1when subject = '数学' then 2when subject = '英语' then 3end seqfrom data) t) twhere seq = 3;
03
小结
本文针对 多行转列过程中如何保证不同字段内容有序性及内容一一对应这一问题给出了解决方案。整体解决思路分如下几个步骤:
步骤1:按照业务规则指定排序顺序,一般采用case when 指定或基于row_number()进行排序指定。具体根据实际需求分析得出采用哪一种。
步骤2:采用collect_list() ove( partition by order by)窗口函数进行求解,具体需要在order by中指定合并的顺序。为什么此处采用collect_list()over()窗口函数而不是其聚合函数,主要是因为保证有序性,只有collect_list()over()能够指定顺序
步骤3:过滤出最终符合条件的数据















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









