









一、算法原理
Logistic回归是众多分类算法中的一员。Logistic回归即对数概率回归,它的名字虽然叫“回归”,但却是一种用于二分类问题的分类算法,它用sigmoid函数估计出样本属于某一类的概率。
1.Logistic函数(Sigmoid函数)
(1)Sigmoid的函数形式为:


(2)sigmoid函数求导
sigmoid导数具体的推导过程如下:

2.构造预测函数
对于线性边界的情况,边界形式如下:

构造预测函数为:

函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
 (1)
(1)
3.构造损失函数J
Cost函数和J函数如下,它们是基于最大似然估计推导得到的。
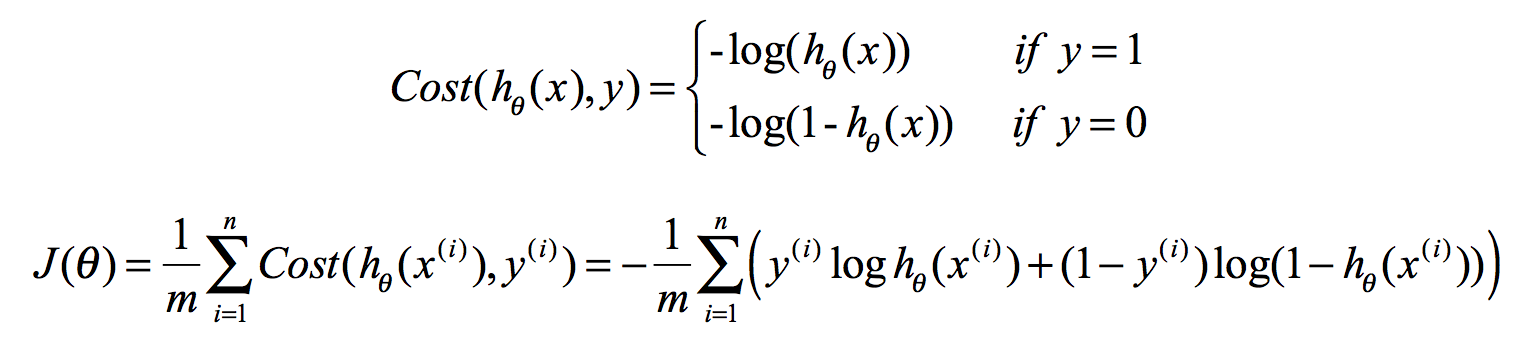
下面详细说明推导的过程:
(1)式综合起来可以写成:

取似然函数为:

对数似然函数为:

最大似然估计就是求使取最大值时的θ。我们乘了一个负的系数-1/m,所以取
最小值时的θ为要求的最佳参数。

4.梯度下降参数求解
θ更新过程:

θ更新过程可以写成:

5.正则化Regularization
对于线性回归或逻辑回归的损失函数构成的模型,可能会有些权重很大,有些权重很小,导致过拟合(就是过分拟合了训练数据),使得模型的复杂度提高,泛化能力较差(对未知数据的预测能力)。
下面左图即为欠拟合,中图为合适的拟合,右图为过拟合。

问题的主因:过拟合问题往往源自过多的特征。
解决方法:
1)减少特征数量(减少特征会失去一些信息,即使特征选的很好)
- 可用人工选择要保留的特征;
- 模型选择算法;
2)正则化(特征较多时比较有效)
- 保留所有特征,但减少θ的大小
正则化类似于线性回归的正则化方法。上一篇博客已经介绍,不再累赘。
6.多分类问题
上面主要使用逻辑回归解决二分类的问题,那对于多分类的问题,也可以用逻辑回归来解决。
(1)one vs rest
由于概率函数所表示的是样本标记为某一类型的概率,但可以将一对一(二分类)扩展为一对多(one vs rest):
- 将类型class1看作正样本,其他类型全部看作负样本,然后我们就可以得到样本标记类型为该类型的概率p1;
- 然后再将另外类型class2看作正样本,其他类型全部看作负样本,同理得到p2;
- 以此循环,我们可以得到该待预测样本的标记类型分别为类型class i时的概率pi,最后我们取pi中最大的那个概率对应的样本标记类型作为我们的待预测样本类型。
(2)softmax函数
softmax函数的介绍可以参见博客:https://blog.csdn.net/behamcheung/article/details/71911133
softmax的预测函数 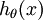 为:
为:

方案选择:当标签类别之间是互斥时,适合选择softmax回归分类器 ;当标签类别之间不完全互斥时,适合选择建立多个独立的logistic回归分类器。
二、算法实践
1.梯度下降法实现逻辑回归
实现LogisticReressionClassifier类,对Iris数据集中的前两种花类型进行分类,同时只使用sepal length和sepal width作为特征。
#Author zsl
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = df.iloc[:100,[0,1,-1]]
data = np.array(data)
return data[:,:2],data[:,-1]
class LogisticReressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.01):
self.max_iter = max_iter
self.learning_rate = learning_rate
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d])
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
err = result - y[i]
self.weights -= self.learning_rate * err * np.transpose([data_mat[i]])
print('LogisticReression model(learning_rate={},max_iter={}) trained.'.format(self.learning_rate, self.max_iter))
def predict(self, X_test):
X_test = self.data_matrix(X_test)
result = []
for i in range(len(X_test)):
pre = self.sigmoid(np.dot(X_test[i], self.weights))
if pre >= 0.5:
result.append(1)
else:
result.append(0)
return result
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
if __name__ == '__main__':
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
lr = LogisticReressionClassifier()
lr.fit(X_train, y_train)
result = lr.predict(X_test)
print(result)
score = lr.score(X_test, y_test)
print(score)
#可视化
x_point = np.arange(4,8)
y_ = -(lr.weights[1]*x_point + lr.weights[0])/lr.weights[2]
plt.plot(x_point, y_)
plt.scatter(X[:50, 0],X[:50, 1], label = '0')
plt.scatter(X[50:, 0],X[50:, 1], label = '1')
plt.legend()
plt.show()

2.sklearn实现
class sklearn.linear_model.LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None,
solver=’warn’, max_iter=100, multi_class=’warn’, verbose=0, warm_start=False, n_jobs=None,
l1_ratio=None)参数说明如下:参数说明参考(https://blog.csdn.net/c406495762/article/details/77851973)更细节。
- penalty:惩罚项,str类型,可选参数为l1和l2,默认为l2。用于指定惩罚项中使用的规范。newton-cg、sag和lbfgs求解算法只支持L2规范。L1G规范假设的是模型的参数满足拉普拉斯分布,L2假设的模型参数满足高斯分布,所谓的范式就是加上对参数的约束,使得模型更不会过拟合(overfit),但是如果要说是不是加了约束就会好,这个没有人能回答,只能说,加约束的情况下,理论上应该可以获得泛化能力更强的结果。
- dual:对偶或原始方法,bool类型,默认为False。对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。
- tol:停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
- c:正则化系数λ的倒数,float类型,默认为1.0。必须是正浮点型数。像SVM一样,越小的数值表示越强的正则化。
- fit_intercept:是否存在截距或偏差,bool类型,默认为True。
- intercept_scaling:仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1。
- class_weight:用于标示分类模型中各种类型的权重,可以是一个字典或者balanced字符串,默认为不输入,也就是不考虑权重,即为None。
- random_state:随机数种子,int类型,可选参数,默认为无,仅在正则化优化算法为sag,liblinear时有用。
- solver:优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear。solver参数决定了我们对逻辑回归损失函数的优化方法。
- max_iter:算法收敛最大迭代次数,int类型,默认为10。仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。
- multi_class:分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。ovr即前面提到的one-vs-rest(OvR),而multinomial即前面提到的many-vs-many(MvM)。如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。
- verbose:日志冗长度,int类型。默认为0。就是不输出训练过程,1的时候偶尔输出结果,大于1,对于每个子模型都输出。
- warm_start:热启动参数,bool类型。默认为False。如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。
- n_jobs:并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。
#Author zsl
from math import exp
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = df.iloc[:100,[0,1,-1]]
data = np.array(data)
return data[:,:2],data[:,-1]
if __name__ == "__main__":
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = LogisticRegression(max_iter=200)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(score)
三、算法总结
优点:
- 实现简单,易于理解和实现;
- 计算代价不高,速度很快,存储资源低。
缺点:
- 容易欠拟合,分类精度可能不高。
- 很难处理数据不平衡问题。
- 处理非线性数据比较麻烦。
四、面试题
1.为什么逻辑回归中使用最大似然函数求得的参数是最优可能的参数值?
最大似然估计的核心是让产生所采样的样本出现的概率最大。即利用已知的样本信息,反推具有最大可能导致这些样本结果出现的模型的参数值。对于逻辑斯特回归来说,样本已经采样了,使其发生的概率最大才符合逻辑,这时通过最大似然函数所求出的参数值就是使采样概率发生最大的参数值,所以可以认为是模型此时的最优解。
2.逻辑回归输出值是0到1之间的值,这个值是真实的概率吗?
逻辑回归输出的值在0到1之间,并非所有在0到1之间的值都可以表示概率。这个0到1之间的值是通过sigmoid函数将线性回归的结果映射到0到1之间,我们也可以采用其他函数将数值映射到非0到1之间,因此,用sigmoid函数得到的结果并不是绝对的真实概率值,但是可以认为他是一个接近真实概率的值。
3.逻辑回归是线性模型吗?
逻辑回归是一种广义的线性模型,它引入sigmoid函数映射,是非线性模型,但本质上又是一个线性回归模型,因为除sigmoid映射函数关系,其他的步骤是线性回归的。可以说,逻辑回归是以线性回归为理论支持的。
4逻辑回归做分类的样本应该满足什么分布?
逻辑回归的样本应该满足伯努力分布,逻辑回归的样本标签是基于样本特征通过伯努力分布产生的,分类器要做的实际上就是估计这个分布。
5.逻辑回归与线性回归的联系与区别?
逻辑回归与线性回归拥有紧密的联系,逻辑回归实在线性回归的基础上添加了一个函数映射(一般为sigmoid函数)得到的,他 们都属于广义线性模型,具体的说,都是从指数分布族导出的线性模型。两者又存在着不同之处:
- 逻辑回归假设变量服从伯努力分布,而线性回归假设变量服从高斯分布。
- 逻辑回归的输出结果为离散分类如0、1,故其经常被用于分类,而线性回归的输出结果是连续变量,它经常被用于预测。
- 逻辑回归经常使用最大似然估计去计算预测函数中的最优参数,而线性回归使用最小二乘法去对自变量的关系进行拟合。
6.LR和SVM的联系与区别?
LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
(1)LR是参数模型,SVM是非参数模型。
(2)从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss.这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
(3)SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
(4)逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
(5)logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。














 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









