







一 背景
知识蒸馏(KD)是想将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,一般来说,teacher具有强大的能力和表现,而student则更为紧凑。通过知识蒸馏,希望student能尽可能逼近亦或是超过teacher,从而用更少的复杂度来获得类似的预测效果。Hinton在Distilling the Knowledge in a Neural Network中首次提出了知识蒸馏的概念,通过引入teacher的软目标(soft targets)以诱导学生网络的训练。近些年来出现了许多知识蒸馏的方法,而不同的方法对于网络中需要transfer的dark knowledge的定义也各不相同。
二 常见方法
1.Distilling the Knowledge in a Neural Network(Hinton系统诠释蒸馏)
该方法提出用soft target来辅助hard target一起训练,而soft target来自于大模型的预测输出。为了使得到的得分vector更soft,在softmax层加上了蒸馏温度T,使蒸馏的性能提升。
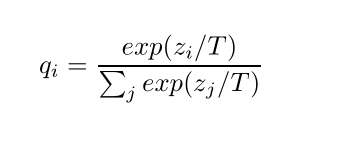
Loss是两者的结合,最好的训练目标函数如下,并且第一个目标函数的权重要大一些。
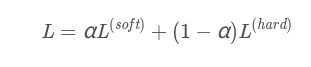
算法的示意图和过程如下:
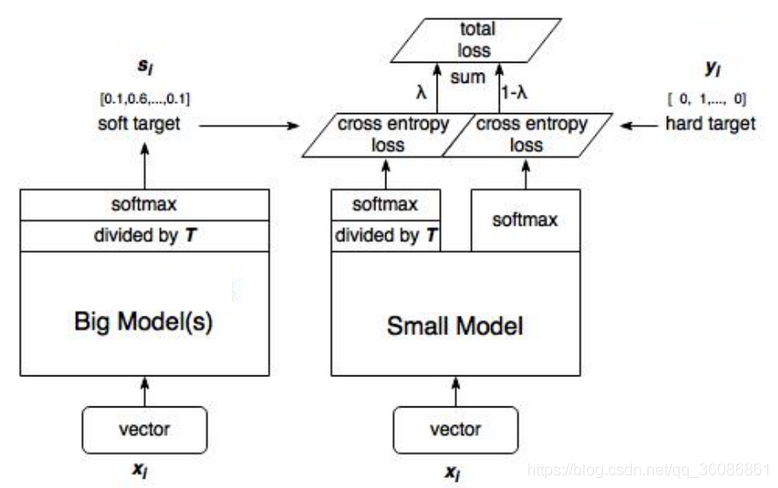
(1)训练大模型:先用hard target,也就是正常的label训练大模型。
(2)计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
(3)训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
(4)预测时,将训练好的小模型按常规方式使用。
2.Fitnets: hints for thin deep nets
该论文的思想是既然网络很深直接训练会很困难,那就通过在中间层加入loss的方法,通过学习teacher中间层feature map来transfer中间层表达的知识,文章中把这个方法叫做Hint-based Training。
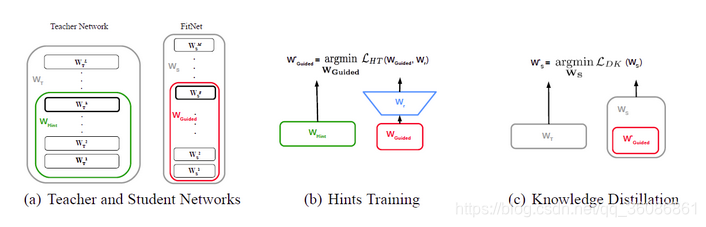
训练分为两个stage:
stage1(Hints Training): 选取teacher的中间层作为guidance,对student的中间层进行监督学习,通常两者的维度不一样,所以需要一个额外的线性矩阵或卷积层去进行维度变换,达到维度一致,然后使用L2 Loss进行监督。
stage2(Knowledge Distillation): 采用论文中KD对整个student进行知识迁移。
两个loss function:
(1)Teacher网络的某一中间层的权值为Wt=Whint,Student网络的某一中间层的权值为Ws=Wguided。使用一个映射函数Wr来使得Wguided的维度匹配Whint,得到Ws'。其中对于Wr的训练使用MSEloss:
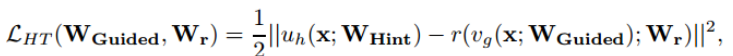
(2)另外一个是改造的softmax loss:
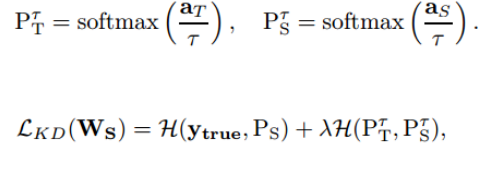
3.Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
该论文的思想是将feature map作为知识直接从teacher transfer到student过于生硬,效果不佳。因此,文章提出将attention map作为知识从teacher transfer到student,希望让student关注teacher所关注的区域。文章的提出的模型结构很朴素,和大部分的知识蒸馏方式相同,教师网络通过生成的注意力图(attentior map)来指导学生网络的注意力图学习,通过attention transfer 缩小学生attentior map 和教师网络attentior map 的距离使得学生网络学习到教师网络的注意力图。这样学生网络学习到了这些知识,便能够生成尽可能与教师网络相似的特征图。这边提一点,在学习中间层特征图,不管是热力图,注意力图还是普通的特征图,两个网络在这个地方的大小是一致的,这样才能通过距离度量计算特征图的距离。
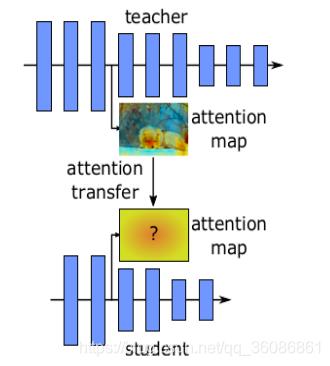
采用hint loss的思想,不同于hint loss只是单纯缩减特征图,而是将特征图转化为注意力图,使得学生网络模型学习到的不 单纯只是特征图信息,而是真正的学到里面的特征。使得学生网络生成的特征图更加灵活,不局限于教师网络的特征图。注意力图生成的方式也是非常朴素的,将多通道特征图叠加起来成为单通道图。这里的叠加可以是本身的n次方后叠加,也可以是不做乘方后的叠加。

4.Similarity-Preserving Knowledge Distillation
本文的构思主要基于一个核心前提:语义相似的输入趋向于在训练好的网络中产生相似的激活模式,反之亦然。基于此,本文提出了核心的假设:如果两个输入在教师网络中有着高度相似的激活,那么引导学生网络趋向于对该输入同样产生高的相似激活(反之亦然)的参数组合,那将是有利的(对于学生更好的学习老师网络的能力与知识)。
本文构造了一种除了最终用于分类的交叉熵损失之外的保留相似性知识蒸馏损失(similarity-preserving knowledge distillation loss):

这里的损失是:
- 针对同一batch数据得到教师模型和学生模型在网络特定层次(教师的l层和学生的l'层)的特征针对batch的相似性关联矩阵。
- 通过计算来自教师模型和学生模型各自关联矩阵的差值的F范数的平方,再针对所有的层次的匹配对计算结果进行加和,针对b^2计算均值可得最终的保留相似性知识蒸馏损失。
- 注意2和3中的公式分母的形式,对于矩阵的右下角标为2的情况,表示的是row-wise L2 normalization 矩阵的谱范数。
- 式子4中的F范数表示的是Frobenius norm(矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数,它的有点在它是一个凸函数,可以求导求解,易于计算)。
总体的损失来进行对学生网络的监督:
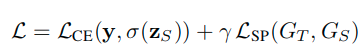
5.Correlation Congruence for Knowledge Distillation
不同于之前的方法,CCKD(correlation congruence knowledge distillation)方法不仅仅关注样本实例层面的一致性,同时也关注实例之间的一致性,如下图:
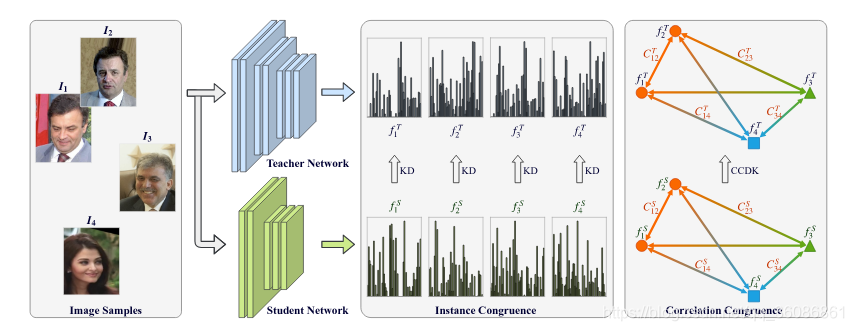
本文用 Ft 和 Fs 来分别表示老师学生网络的特征表示的集合,可以用公式表示如下:
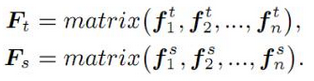
定义 C 为相关性矩阵,其中每一个元素表示 xi 和 yi 的关系,因此可以表示为公式:
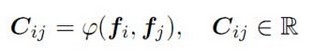
计算 CCloss如下:
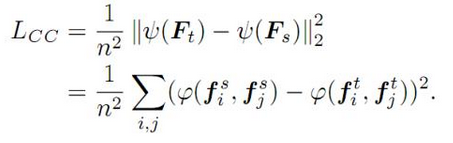
CCKD 算法的 loss 由三部分组成,计算如下:
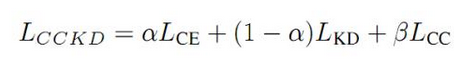
6.A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
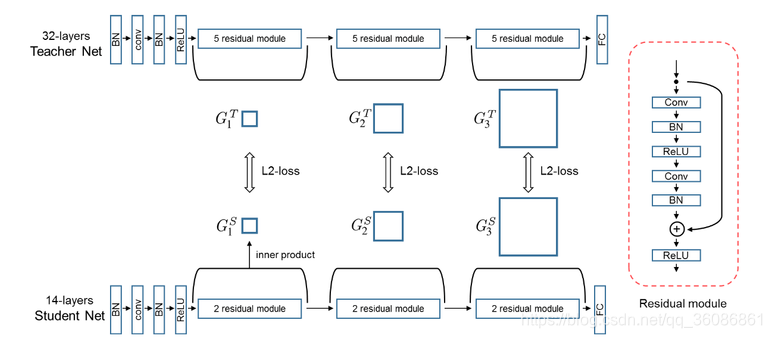
本文不再拟合大模型的输出,而是去拟合大模型层与层之间的关系。这个关系是用层与层之间的内积来定义的:假如说甲层有 M 个输出通道,乙层有 N 个输出通道,就构建一个 M*N 的矩阵来表示这两层间的关系,其中 (i, j) 元是甲层第 i 个通道 和 乙层第 j 个通道的内积(因此此方法需要甲乙两层 feature map 的形状相同)。文中把这个矩阵叫 FSP (flow of solution procedure) 矩阵,其实这也是一种Gram矩阵。
计算內积的方式(也就是所谓的"知识"):
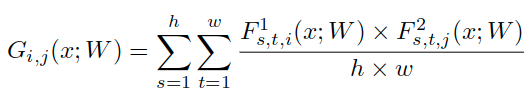
损失函数为:
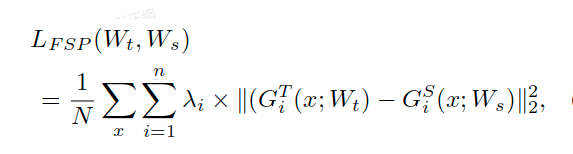
7.Like what you like: knowledge distill via neuron selectivity transfer
本文探索出了教师模型中一种新的知识,并将其迁移给学生模型。具体来说,利用神经元的选择性知识。这个模型背后的直觉是相当简单的:每个神经元基本上从原始输入中提取与手头任务相关的某种模式。 因此,如果神经元在某些区域或样本中被激活,则这意味着这些区域或样本共享了可能与任务相关的一些常见属性。这样的聚类知识对于学生网络是有价值的,因为它为教师模型的最终预测提供了一个解释。因此,我们提出使学生模型和教师模型之间的神经元选择性知识的分布相一致。
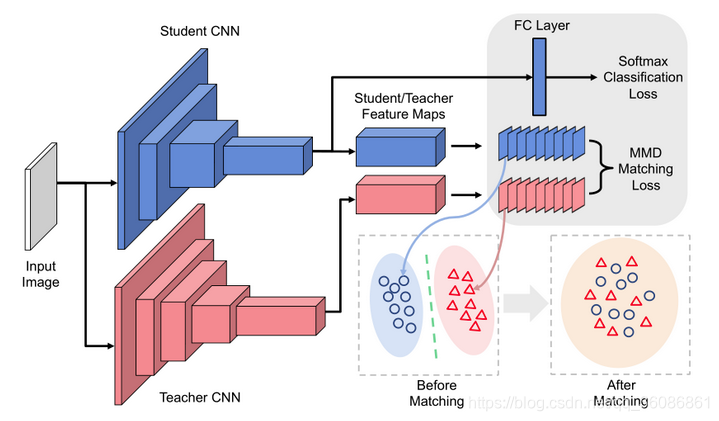
本文用最大平均差异(Maximum Mean Discrepancy,MMD)用做损失函数作为评价教师特征与学生特征的差异.
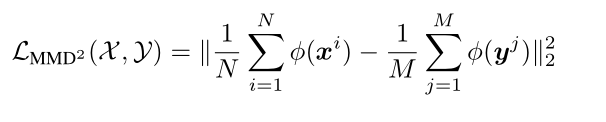
简化MMD公式如下:
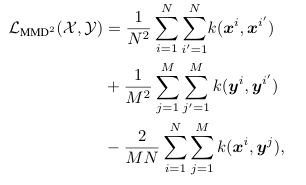
最终的损失函数如下:
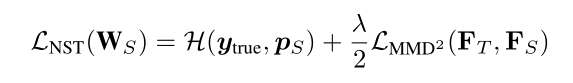
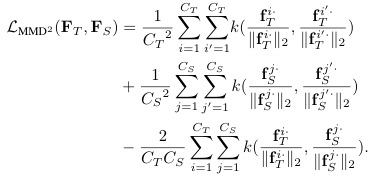
其中k为核函数,可以采用线性核函数 多项式核函数 高斯核函数.
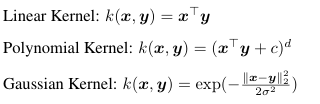
三 参考资料
https://www.yuque.com/lart/gw5mta/scisva
https://github.com/FLHonker/Awesome-Knowledge-Distillation
https://github.com/HobbitLong/RepDistiller

















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









