









核心思想
该文提出一种基于位置的单目视觉伺服算法,与传统的PBVS不同,该文利用预训练的CNN从环境中提取特征信息,并通过一个简单的线性回归过程输出概率图(反映每个像素点属于目标物体的概率值)。然后结合拓展卡尔曼滤波(EKF)来确定目标物体在图像中的精确位置。最后利用迭代线性二次型调节器(iLQR)来实现视觉伺服的控制过程。整个过程如下图所示
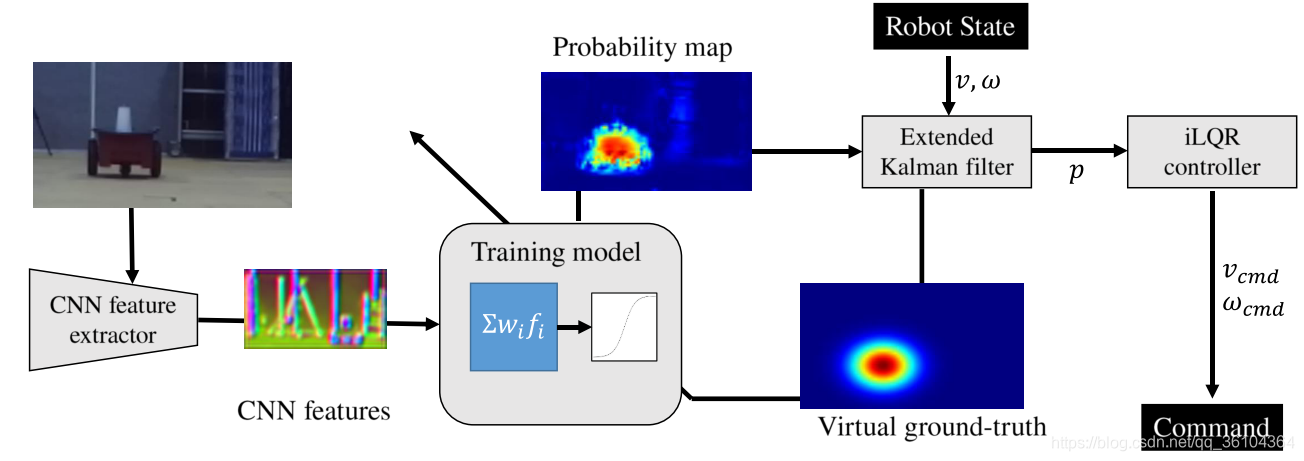
首先,单目相机采集的图像输入到一个CNN特征提取器,该CNN预先在ImageNet上做过训练,能够提取图像的特征信息。将特征信息输入到一个简单的线性回归模型中,得到图像对应的概率图,如下式
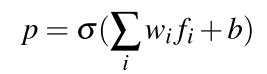
f
i
f_i
fi表示提取得到的特征信息,
p
p
p表示概率图,其中每个像素点的数值表示该点属于目标物体的概率值。这个模型可以通过交叉熵损失函数进行快速训练,采用的是自监督模式。在初始位置需要根据给定的目标框来生成对应的概率图作为groundtruth,运动过程中会利用EKF输出估计的概率值作为ground truth实现对于线性回归模型的训练。
然后,利用EKF来获取目标物体在图像坐标系中的位置。对于这个位置信息,我们有两种方式获取,第一是通过一个模型去预测他,第二是通过一个传感器去测量他,但这两种方式都会由于种种原因存在误差,卡尔曼滤波则是充分考虑两种定位方式的可靠性,制定一个加权求和的策略,来获取更为精确的位置。本文设计的预测模型是利用小孔成像原理构建的模型,但该模型有个重要的问题就是不能获取深度信息。了解双目视觉或者对极几何的同学应该知道,深度信息可以利用视差进行计算。单目相机可以通过控制机器人的移动来生成视差信息(机器人在a点观察目标物体,然后水平移动到b点再次观察目标物体,目标物体在两幅图像中的坐标差值就是视差)。因为不知道目标物体的形状,因此采用一种类高斯的椭圆概率图来表示目标物体的位置(如下图所示)
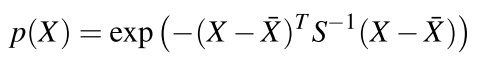

X
ˉ
\bar{X}
Xˉ表示目标的位置,
S
S
S表示尺度参数。在惯性坐标系(世界坐标系)下,表示为
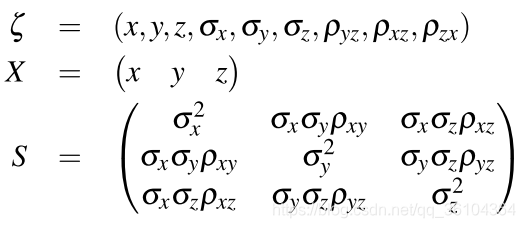
ζ
\zeta
ζ表示卡尔曼滤波器的状态,包括预测位置,标准差和相关系数。而在图像坐标系中模型预测的位置如下
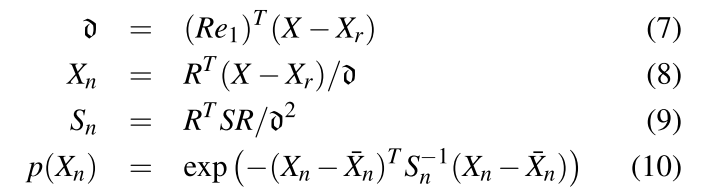
"像6一样的符号"表示深度信息,
X
r
X_r
Xr表示机器人的位置,
R
R
R表示机器人的方向,这两个数据都可以通过读取机器人的里程计获取。
⋅
n
\cdot _n
⋅n是
⋅
\cdot
⋅在图像坐标系中的表示。卡尔曼滤波器还需要一个传感器测量值,因为本文采用的单目相机,所以感知目标位置的传感器也只有相机,所以利用上一部分CNN+线性模型预测出来的概率图,可以作为测量值
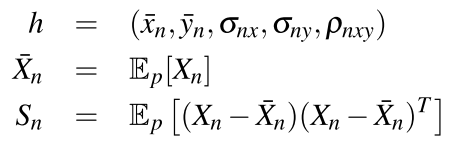
最后,在获得了目标位置之后,就是利用iLQR算法来实现伺服控制了。迭代方法首先要将运动过程离散化
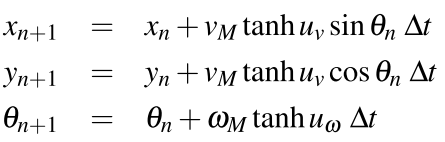
还需要建立成本函数
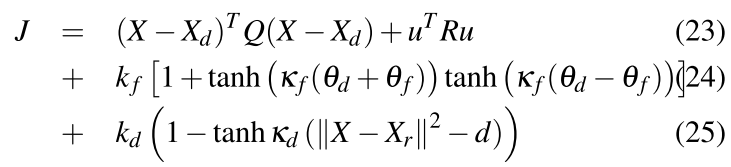
第一项是标准的状态误差和输入误差,第二项是约束目标在相机视野内,第三项是避免机器人与目标距离太近,导致碰撞。
算法评价
本文与传统的视觉伺服过程有很大的不同,深度学习模型在其中扮演一个提取特征并预测目标位置的作用。卡尔曼滤波器一方面要根据模型预测一个位置,另一方面还要利用深度学习输出的位置,将两者加权平均后可以获得一个更精确的位置概率图。这个位置概率图既要用来计算控制律,又要作为一个ground truth来帮助前面的深度学习模型来进行自监督训练。最后,迭代的线性二次型控制器来实现视觉伺服的控制部分,根据输入的位置概率图来计算控制律。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











