









核心思想
本文提出一种通过图块匹配寻找图像和CAD模型之间的对应关系,并进一步实现位姿估计的算法。与许多从单目图像中实现目标物体三维识别并估计位姿的方法类似,本文也是通过从CAD模型库中检索最相似的CAD模型,然后计算旋转和平移矩阵,最终实现三维识别和位姿估计。本文的主要创新在于不是对整幅图像和模型进行匹配,而是在图像中选取小的图块,然后对图块进行匹配。作者认为这种方式不仅能够获取图像和CAD模型之间全局的语义相似性,而且能够获取中级和低级的几何相似性。
实现过程
首先,本文采用RetinaNet进行2D目标检测,并得到目标物体的特征
f
k
f_k
fk,然后利用ShapeMask网络实现物体的实例分割,得到分割结果
m
k
m_k
mk,将分割结果和特征相乘
f
k
∘
m
k
f_k\circ m_k
fk∘mk作为后续模型检索和位姿估计的输入。
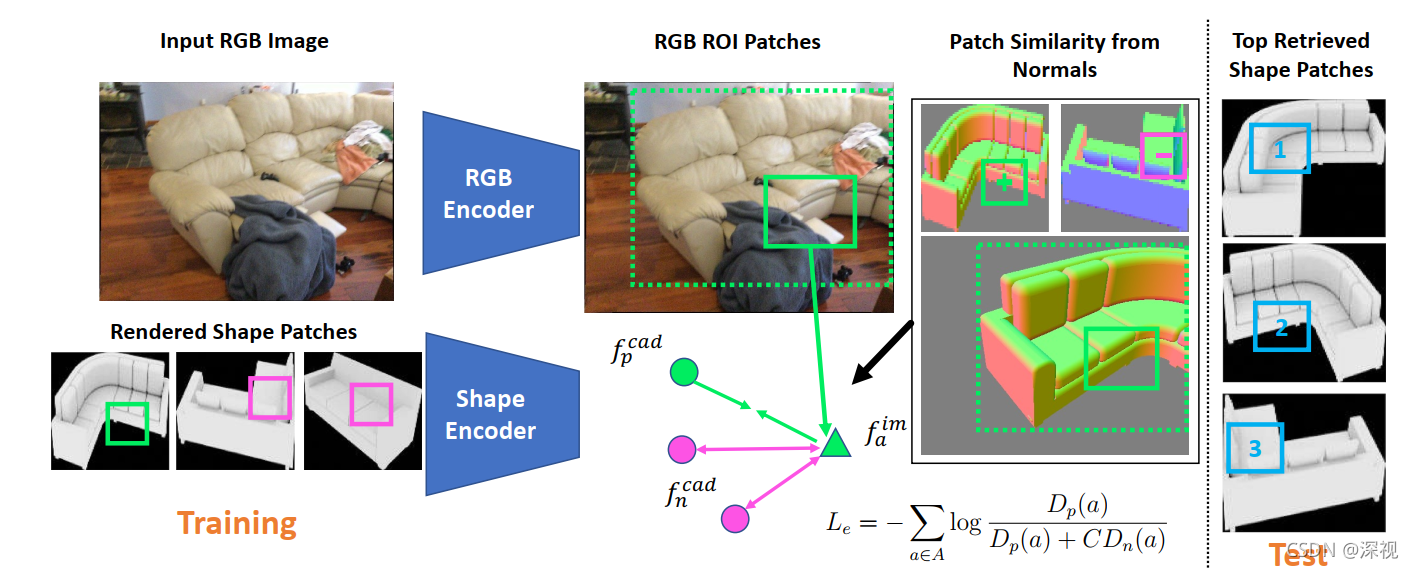
然后,本文构建了一个基于图块的联合嵌入空间,将物体的图像和CAD模型整合在一个统一的空间中来描述。这本身是个困难的任务,因为图像和CAD模型在视角、颜色、光照和材料等方面都有很大的不同。而且对于完整的目标物体而言,图像和CAD模型之间很难找到精确匹配的对象,通常都包含一定的细节差别,如何寻找到二者的共同特征是非常困难的。因此作者考虑到将整个目标对象分解成若干个图块,每个图块中只包含部分的简单结构,这样在进行特征描述时就能够包含更多的低级和中级的几何信息。本文从
f
k
∘
m
k
f_k\circ m_k
fk∘mk中随机选取图块(尺寸为ROI区域的1/3)作为图像输入,对于每个CAD模型,都从16个主视角分别拍摄图像,并提取图块(尺寸为渲染模型的1/3)作为模型输入。图像输入和模型输入分别经过一系列的2D卷积得到对应的特征
f
i
m
f^{im}
fim和
{
f
j
c
a
d
}
\{f^{cad}_j\}
{fjcad},特征提取网络的损失函数如下
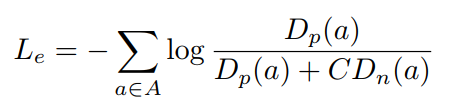
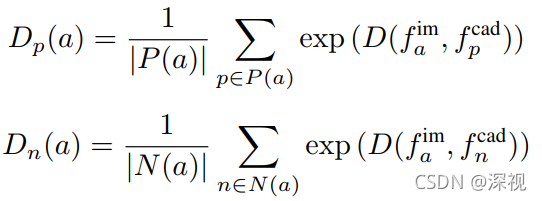
其中,
A
A
A表示查询图块的集合,
P
(
a
)
P(a)
P(a)和
N
(
a
)
N(a)
N(a)分别表示正确的匹配图块和错误的匹配图块集合,
C
C
C是一个加权系数,本文取
C
=
24
C=24
C=24。
D
(
x
,
y
)
D(x,y)
D(x,y)计算过程如下
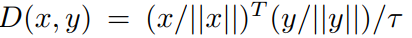
其中,
τ
=
0.15
\tau=0.15
τ=0.15
为了实现上述的训练过程,必须明确图像和模型之间图块相似性的定义,也就是说给定一个查询图块
a
a
a,如何判断哪些模型图块是正确匹配,哪些是错误匹配。本文是利用CAD模型中渲染得到的法线向量来描述局部的几何特征。对于CAD模型来说,就直接提取图块对应的法线向量;对于图像来说,则是提取图块对应的CAD模型(groundtruth)在该区域的法线向量。对于每个图块的法线向量都利用自相似性直方图(self-similarity histogram)来作为特征描述,自相似性直方图统计了该图块中各个法向量两两之间的角度差异,并且进行了归一化处理。通过计算两个图块对应的自相似性直方图之间的IoU区域大小来计算两个图块之间的匹配相似性,将
I
o
U
>
θ
p
IoU>\theta_p
IoU>θp图块视为正确匹配图块,将
I
o
U
<
θ
n
IoU<\theta_n
IoU<θn的图块视为错误匹配。对于每个查询图块
a
a
a,都选择1024个错误匹配图块来进行训练,而正确匹配图块的数量可能是不固定的,但这会影响训练的稳定性,因此作者将所有正确匹配图块取平均值作为一个正确匹配图块来进行训练。
接下来利用图块来完成模型的检索,对于一个待检索的目标物体
f
i
m
f^{im}
fim,从中随机选择
K
q
K_q
Kq个图块,而对于每个图块都从模型数据库中检索得到
K
r
K_r
Kr个相似的模型图块。根据这
K
r
K_r
Kr个模型图块归属的CAD模型,通过投票的方式,选择得票数最多的CAD模型作为当前图块的匹配模型。举个例子解释一下,比如对于一个图像图块
a
a
a,检索得到10个(
K
r
=
10
K_r=10
Kr=10)模型图块与之相似,其中7个图块属于模型A,2个图块属于模型B,1个图块属于模型C,那么模型A就是图像图块
a
a
a的匹配模型。那么
K
q
K_q
Kq个图像图块就会得到
K
q
K_q
Kq个对应的匹配模型,然后同样通过投票的方式选择得票数最高的模型,作为整个目标物体的匹配模型。
最后,要根据检索得到的匹配模型来进行目标的姿态估计。对于旋转参数(用四元数表示),本文通过对训练目标的旋转参数进行K中心值聚类得到对应的
K
K
K个旋转参数分区(rotation bins),然后利用交叉熵损失函数通过分类的方式判断当前目标属于哪个分区,再利用Huber损失通过回归的方式计算旋转参数的偏移量,在分区的基础上进行优化。对于平移参数,则是直接利用Huber损失函数预测目标外接框中心的偏移量。
创新点
- 提出一种基于图块的模型检索方法,降低了构建整个图像和模型间匹配关系的难度
- 利用法线向量之间的自相似性来评估图块之间的相似程度
算法评价
本文的核心思想并没有什么大的改变,还是延续着二维图像识别+分割,三维模型匹配,模型检索和位姿估计的路线,主要的创新在于考虑到图像和模型整体匹配的难度,而使用图块的局部特征来进行匹配和检索,并通过投票的形式选出最佳匹配模型。从实验结果来看,本文的方法相较于整体进行匹配的方法(Mask2CAD)还是有一定提升的。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











