









写在最前面:近几年扩散模型已经逐步取代GAN、VAE等模型成为图像生成领域最炙手可热的研究方向,本文从基础理论的角度出发,简要的介绍一下扩散模型在图像生成领域的几个代表性工作,包括DDPM、DDIM和NCSN等。为保证文章的可读性,本文将尽可能避免具体的公式推导和证明,使用更加通俗易懂的方式来介绍相关内容。
- DDPM
- NCSN
- SDE
- DDIM
- IDDPM
Ho et al. [1] 和 Song et al. [2] 分别从扩散模型(DDPM)和分数模型(NCSN)的角度出发阐述了如何实现图像生成,后面我们会知道二者本质上是等价的,只相差一个系数,而且可以用随机微分方程的形式进行统一(SDE)[3]。下面,我们将从DDPM开始,介绍一下扩散模型是如何实现图像生成的。
1. DDPM
在DDPM中,图像生成被分为两个阶段:扩散和采样。所谓扩散阶段 q ( x T ∣ x 0 ) q(x_T|x_0) q(xT∣x0),就是对一幅图像 x 0 x_0 x0通过逐步增加噪声 ϵ \epsilon ϵ,使其最终变成一个随机噪声 x T x_T xT;而采样阶段 p θ ( x 0 ) p_{\theta}(x_0) pθ(x0),则是从一个随机噪声 x T x_T xT中通过逐步去噪,最终得到一张生成的图像 x 0 x_0 x0。无论是扩散还是采样过程,都是一个马尔可夫链,每一步的预测都依赖于上一步的输出结果。在扩散阶段我们将会训练一个神经网络(UNet),让其根据当前的时间步数 t t t和输入的噪声图像 x t x_t xt,预测一个噪声 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t,t) ϵθ(xt,t),用于采样阶段中对图像进行去噪。下图很形象的表述了扩散和采样过程(图源:B站博主VictorYuki的视频“从零开始了解 Diffusion Model”),图中使用 z ~ \tilde{z} z~表示预测噪声 ϵ θ \epsilon_{\theta} ϵθ。
扩散
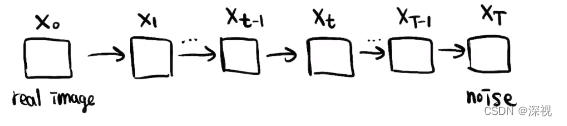
采样
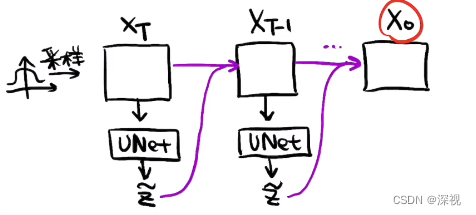
有了一个大致的概念后,我们来具体介绍一下扩散和采样的实现过程。首先给定一幅图像
x
0
x_0
x0,根据上面的介绍我们得知,我们可以对其添加噪声得到
x
1
x_1
x1,再对
x
1
x_1
x1添加噪声得到
x
2
x_2
x2,重复这个过程直至得到纯噪声
x
T
x_T
xT,该过程可以表示为
q
(
x
1
:
T
∣
x
0
)
:
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
(1-1)
q(x_{1:T}|x_0):=\displaystyle\prod_{t=1}^{T}q(x_t|x_{t-1})\tag{1-1}
q(x1:T∣x0):=t=1∏Tq(xt∣xt−1)(1-1)
其中
q
(
x
t
∣
x
t
−
1
)
:
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
(1-2)
q(x_t|x_{t-1}):=\mathcal{N}(x_t;\sqrt{1-\beta_{t}}x_{t-1},\beta_tI)\tag{1-2}
q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)(1-2)
作者将每一步的扩散过程描述成从以
1
−
β
t
x
t
−
1
\sqrt{1-\beta_{t}}x_{t-1}
1−βtxt−1为均值,以
β
t
\beta_t
βt为方差的高斯分布中采样的过程,利用重参数技巧可转化为
x
t
=
1
−
β
t
x
t
−
1
+
β
t
ϵ
,
ϵ
∽
N
(
0
,
I
)
(1-3)
x_t=\sqrt{1-\beta_{t}}x_{t-1}+\sqrt{\beta_t}\epsilon,\epsilon \backsim\mathcal{N}(0,I) \tag{1-3}
xt=1−βtxt−1+βtϵ,ϵ∽N(0,I)(1-3)
可以看到每一步的
x
t
x_t
xt都是由上一步的输出结果
x
t
−
1
x_{t-1}
xt−1与噪声
ϵ
\epsilon
ϵ进行加权求和得到的,权重系数
β
t
\beta_t
βt随着
t
t
t的增加而逐步增长,直至
x
T
x_T
xT变成一个完全的随机噪声。这个过程通常要迭代成百上千次,在DDPM中
T
T
T取值为1000,这就导致扩散的过程十分漫长。为了解决这个问题,作者提出一种快速扩散的方法,可以由
x
0
x_0
x0直接生成任意时刻
t
t
t的噪声图
x
t
x_t
xt,如下式
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
ˉ
t
x
0
,
(
1
−
α
ˉ
t
)
I
)
(1-4)
q(x_t|x_{0})=\mathcal{N}(x_t;\sqrt{\bar{\alpha}_{t}}x_{0},(1-\bar{\alpha}_{t})I)\tag{1-4}
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)(1-4)
即
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
,
ϵ
∽
N
(
0
,
I
)
(1-5)
x_t=\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon,\epsilon \backsim\mathcal{N}(0,I)\tag{1-5}
xt=αˉtx0+1−αˉtϵ,ϵ∽N(0,I)(1-5)
其中
α
t
=
1
−
β
t
,
α
ˉ
t
=
∏
s
=
1
t
α
s
\alpha_{t}=1-\beta_{t},\bar{\alpha}_{t}=\prod^t_{s=1}\alpha_s
αt=1−βt,αˉt=∏s=1tαs。
介绍完扩散过程,我们再来看一下采样过程。采样过程(也叫重建过程)是一个逆扩散过程,即从随机采样得到的噪声
X
T
X_T
XT逐步去噪直至生成一个图像
x
0
x_0
x0,表示为
p
θ
(
x
0
:
T
)
:
=
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
(1-6)
p_{\theta}(x_{0:T}):=p(x_T)\prod^{T}_{t=1}p_{\theta}(x_{t-1}|x_{t})\tag{1-6}
pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt)(1-6)
其中
p
(
x
T
)
=
N
(
0
,
I
)
,
p
θ
(
x
t
−
1
∣
x
t
)
:
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
p(x_T)=\mathcal{N}(0,I),p_{\theta}(x_{t-1}|x_{t}):=\mathcal{N}(x_{t-1};\mu_{\theta}(x_t,t),\Sigma_{\theta}(x_t,t))
p(xT)=N(0,I),pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))。分布
p
θ
(
x
t
−
1
∣
x
t
)
p_{\theta}(x_{t-1}|x_{t})
pθ(xt−1∣xt)实际上是未知的,而逆转后的扩散过程的分布
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)是可以利用贝叶斯公式计算出来的,因此作者使用神经网络模型去拟合一个分布,使其逼近
q
(
x
t
−
1
∣
x
t
,
x
0
)
q(x_{t-1}|x_t,x_0)
q(xt−1∣xt,x0)。
q
(
x
t
−
1
∣
x
t
,
x
0
)
=
N
(
x
t
−
1
;
μ
~
t
(
x
t
,
x
0
)
,
β
~
t
I
)
(1-8)
q(x_{t-1}|x_t,x_0)=\mathcal{N}(x_{t-1};\tilde{\mu}_t(x_t,x_0),\tilde{\beta}_tI)\tag{1-8}
q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)(1-8)
其中
μ
~
t
(
x
t
,
x
0
)
:
=
α
ˉ
t
−
1
β
t
1
−
α
ˉ
t
x
0
+
α
t
(
1
−
α
ˉ
t
−
1
)
1
−
α
ˉ
t
x
t
,
β
~
t
:
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
(1-9)
\tilde{\mu}_t(x_t,x_0):=\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_{t}}x_0+\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_{t}}x_t,\tilde{\beta}_t:=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_t\tag{1-9}
μ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt,β~t:=1−αˉt1−αˉt−1βt(1-9)
训练的目标函数为
L
V
L
B
=
E
q
[
D
K
L
(
q
(
x
T
∣
x
0
)
∣
∣
p
(
x
T
)
)
⏟
L
T
+
∑
t
>
1
D
K
L
(
q
(
x
t
−
1
∣
x
t
,
x
0
)
∣
∣
p
θ
(
x
x
−
1
∣
x
t
)
)
⏟
L
t
−
1
−
log
p
θ
(
x
0
∣
x
1
)
⏟
L
0
]
(1-10)
\mathcal{L}_{VLB}=\mathbb{E}_q\left[ \underbrace{D_{KL}(q(x_T|x_0)||p(x_T))}_{L_T} + \sum_{t>1}\underbrace{D_{KL}(q(x_{t-1}|x_t,x_0)||p_{\theta}(x_{x-1}|x_t))}_{L_{t-1}} \underbrace{ -\log{p_{\theta}(x_0|x_1)}}_{L_0}\right]\tag{1-10}
LVLB=Eq
LT
DKL(q(xT∣x0)∣∣p(xT))+t>1∑Lt−1
DKL(q(xt−1∣xt,x0)∣∣pθ(xx−1∣xt))L0
−logpθ(x0∣x1)
(1-10)
该目标函数也就是所谓的变分下界(variational lower bound,VLB),其中第一项
L
T
L_T
LT不包含可训练的参数,因此在训练时通常忽略,而对于第三项
L
0
L_{0}
L0,作者构建了一个离散化的分段积分累乘方法来计算,此处不再展开介绍,感兴趣的可阅读原文[1]。我们重点关注第二项
L
t
−
1
L_{t-1}
Lt−1。
对于分布
p
θ
(
x
x
−
1
∣
x
t
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
p_{\theta}(x_{x-1}|x_t)=\mathcal{N}(x_{t-1};\mu_{\theta}(x_t,t),\Sigma_{\theta}(x_t,t))
pθ(xx−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t)),当
0
<
t
≤
T
0< t\leq T
0<t≤T时,作者令方差项为一个无需训练只与时间
t
t
t有关的常数,即
Σ
θ
(
x
t
,
t
)
=
σ
t
2
I
\Sigma_{\theta}(x_t,t)=\sigma_t^2I
Σθ(xt,t)=σt2I,其中
σ
t
2
=
β
t
\sigma_t^2=\beta_t
σt2=βt或
σ
t
2
=
β
~
t
=
1
−
α
ˉ
t
−
1
1
−
α
ˉ
t
β
t
\sigma_t^2=\tilde{\beta}_t=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_t
σt2=β~t=1−αˉt1−αˉt−1βt。实验结果表明两种取值方式并没有显著差别,
Σ
θ
(
x
t
,
t
)
\Sigma_{\theta}(x_t,t)
Σθ(xt,t)也可以作为一个可训练参数,但本文的实验表示这会使得训练不稳定。利用多元高斯分布的KL散度求解公式,
L
t
−
1
L_{t-1}
Lt−1可以写为
L
t
−
1
=
E
q
[
1
2
σ
t
2
∥
μ
~
t
(
x
t
,
x
0
)
−
μ
θ
(
x
t
,
t
)
∥
2
]
+
C
(1-11)
L_{t-1}=\mathbb{E}_q\left [\frac{1}{2\sigma^2_t}\left \| \tilde{\mu}_t(x_t,x_0)-\mu_{\theta}(x_t,t)\right \|^2\right]+C\tag{1-11}
Lt−1=Eq[2σt21∥μ~t(xt,x0)−μθ(xt,t)∥2]+C(1-11)
则训练目标转化为训练一个网络根据输入的噪声图
x
t
x_t
xt和时间
t
t
t输出对应的均值
μ
θ
(
x
t
,
t
)
\mu_{\theta}(x_t,t)
μθ(xt,t)使其接近
μ
~
t
(
x
t
,
x
0
)
\tilde{\mu}_t(x_t,x_0)
μ~t(xt,x0)。利用公式(1-5),我们可以得到
x
0
=
1
α
t
(
x
t
−
1
−
α
ˉ
t
ϵ
)
(1-12)
x_0=\frac{1}{\sqrt{\alpha_t}}(x_t-\sqrt{1-\bar{\alpha}_t}\epsilon)\tag{1-12}
x0=αt1(xt−1−αˉtϵ)(1-12)
将其带入
μ
~
t
(
x
t
,
x
0
)
\tilde{\mu}_t(x_t,x_0)
μ~t(xt,x0)的表达式中可得
μ
~
t
(
x
t
,
x
0
)
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
ϵ
)
(1-13)
\tilde{\mu}_t(x_t,x_0)=\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon)\tag{1-13}
μ~t(xt,x0)=αt1(xt−1−αˉtβtϵ)(1-13)其中
x
t
,
α
t
,
β
t
x_t,\alpha_t,\beta_t
xt,αt,βt都是已知量,只有噪声
ϵ
\epsilon
ϵ是一个随机变量,因此预测
μ
θ
(
x
t
,
t
)
\mu_{\theta}(x_t,t)
μθ(xt,t)进一步转化为根据当前的输入
x
t
x_t
xt和时间
t
t
t预测一个噪声
ϵ
θ
(
x
t
,
t
)
\epsilon_{\theta}(x_t,t)
ϵθ(xt,t),即
μ
θ
(
x
t
,
t
)
=
μ
~
t
(
x
t
,
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
ϵ
θ
(
x
t
)
)
)
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
ϵ
θ
(
x
t
,
t
)
)
(1-14)
\mu_{\theta}(x_t,t)=\tilde{\mu}_t\left (x_t,\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_{\theta}(x_t))\right)=\frac{1}{\sqrt{\alpha_t}}\left(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_{\theta}(x_t,t)\right)\tag{1-14}
μθ(xt,t)=μ~t(xt,αt1(xt−1−αˉtβtϵθ(xt)))=αt1(xt−1−αˉtβtϵθ(xt,t))(1-14)
则训练目标可以进一步的写为
L
t
−
1
=
E
x
0
,
ϵ
[
β
t
2
2
σ
t
2
α
t
(
1
−
α
ˉ
t
)
∥
ϵ
−
ϵ
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
,
t
)
∥
2
]
(1-15)
L_{t-1}=\mathbb{E}_{x_0,\epsilon}\left [\frac{\beta^2_t}{2\sigma^2_t\alpha_t(1-\bar{\alpha}_t)}\left \|\epsilon-\epsilon_{\theta}(\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon,t)\right \| ^2\right ]\tag{1-15}
Lt−1=Ex0,ϵ[2σt2αt(1−αˉt)βt2
ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)
2](1-15)
结合
L
t
−
1
L_{t-1}
Lt−1和
L
0
L_0
L0,最终的目标函数
L
V
L
B
\mathcal{L}_{VLB}
LVLB简化为
L
s
i
m
p
l
e
(
θ
)
:
=
E
t
,
x
0
,
ϵ
[
∥
ϵ
−
ϵ
θ
(
α
ˉ
t
x
0
+
1
−
α
ˉ
t
ϵ
,
t
)
∥
2
]
(1-16)
L_{simple}(\theta):=\mathbb{E}_{t,x_0,\epsilon}\left [\left \|\epsilon-\epsilon_{\theta}(\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon,t)\right \| ^2\right ]\tag{1-16}
Lsimple(θ):=Et,x0,ϵ[
ϵ−ϵθ(αˉtx0+1−αˉtϵ,t)
2](1-16)
利用扩散过程中输入的
x
0
x_0
x0和每次随机采样的噪声
ϵ
\epsilon
ϵ就能训练得到一个噪声预测模型
ϵ
θ
(
x
t
,
t
)
\epsilon_{\theta}(x_t,t)
ϵθ(xt,t)。最后在采样阶段,根据
x
t
−
1
∽
p
θ
(
x
t
−
1
∣
x
t
)
x_{t-1}\backsim p_{\theta}(x_{t-1}|x_t)
xt−1∽pθ(xt−1∣xt)可得
x
t
−
1
=
μ
θ
(
x
t
,
t
)
+
σ
t
z
=
1
α
t
(
x
t
−
β
t
1
−
α
ˉ
t
ϵ
θ
(
x
t
,
t
)
)
+
σ
t
z
,
z
∽
N
(
0
,
I
)
(1-17)
x_{t-1}=\mu_{\theta}(x_t,t)+\sigma_tz=\frac{1}{\sqrt{\alpha_t}}\left(x_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_{\theta}(x_t,t)\right)+\sigma_tz,z\backsim \mathcal{N}(0,I)\tag{1-17}
xt−1=μθ(xt,t)+σtz=αt1(xt−1−αˉtβtϵθ(xt,t))+σtz,z∽N(0,I)(1-17)
当模型训练完成时,
μ
θ
(
x
t
,
t
)
\mu_{\theta}(x_t,t)
μθ(xt,t)是一个确定过程,只与输入的
x
t
x_t
xt有关,而在每次重建时都会随机采样一个
z
z
z来增加一定的随机性,使得生成样本具有更大的多样性。我们再看一下作者给出的训练和采样阶段的算法流程

训练阶段,首先采样得到一个图像样本
x
0
x_0
x0,然后从
{
1
,
.
.
.
,
T
}
\{1,...,T\}
{1,...,T}中均匀采样一个时间
t
t
t,并按照标准正态分布采样一个噪声
ϵ
\epsilon
ϵ,利用目标函数(1-16)训练一个UNet模型用于预测
ϵ
θ
(
x
t
,
t
)
\epsilon_{\theta}(x_t,t)
ϵθ(xt,t)。在采样阶段,在标准正态分布中采样得到初始的噪声图
x
T
x_T
xT,并且在每一步都采样一个随机变量
z
z
z,然后按照公式(1-17),由
T
T
T到1逐步预测
x
t
−
1
x_{t-1}
xt−1,直至得到
x
0
x_0
x0。值得注意的是当
t
=
1
t=1
t=1时,也就是最后一步预测时,随机变量
z
=
0
z=0
z=0。
至此,我们对DDPM的扩散和采样过程,以及训练目标进行了一个相对完整的介绍。我们只给出了结论性的公式,如果要了解具体推导和证明步骤,可参考原文及附录,这篇博客和这个视频也给出了更加详细的分析。受篇幅限制,本文仅对DDPM进行了介绍,其他的方法将在后续的文章中分别介绍。
参考文献
[1] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851.
[2] Song Y, Ermon S. Generative modeling by estimating gradients of the data distribution[J]. Advances in neural information processing systems, 2019, 32.
[3] Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2020). Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











