









3. SDE
在前两篇文章中,我们分别介绍了基于扩散模型的DDPM和基于分数的NCSN两种生成方法,正如宋飏博士所说二者就像物理学中的波动力学和矩阵力学,是一个事物的两种不同解释方式,最终都会统一到量子力学的框架中,这里的“量子力学框架”就是随机微分方程(Stochastic Differential Equation,SDE)。
3.1 回顾DDPM与NCSN
在介绍SDE之前,我们先简单回顾下DDPM和NCSN两种生成方法。首先,都要对原始分布中的一个样本
x
0
x_0
x0,不断地添加噪声使其变为一个随机噪声
x
T
x_T
xT。DDPM中称之为扩散过程,NCSN中称之为干扰或扰动,实现方式如下
D
D
P
M
:
x
t
=
α
ˉ
t
x
0
+
1
−
α
ˉ
t
z
,
z
∽
N
(
0
,
I
)
(3-1)
DDPM:x_t =\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}z,z\backsim\mathcal{N}(0,I)\tag{3-1}
DDPM:xt=αˉtx0+1−αˉtz,z∽N(0,I)(3-1)
N
C
S
N
:
x
t
=
x
0
+
σ
t
z
,
z
∽
N
(
0
,
I
)
(3-2)
NCSN:x_t=x_0+\sigma_tz,z\backsim\mathcal{N}(0,I)\tag{3-2}
NCSN:xt=x0+σtz,z∽N(0,I)(3-2)公式(3-1)和(3-2)还可以写成对应的离散的单步推导的形式:
D
D
P
M
:
x
t
=
1
−
β
t
x
t
−
1
+
β
t
z
t
−
1
(3-3)
DDPM:x_t=\sqrt{1-\beta_t}x_{t-1}+\sqrt{\beta_t}z_{t-1}\tag{3-3}
DDPM:xt=1−βtxt−1+βtzt−1(3-3)
N
C
S
N
:
x
t
=
x
t
−
1
+
σ
t
2
−
σ
t
−
1
2
z
t
−
1
(3-4)
NCSN:x_t=x_{t-1}+\sqrt{\sigma_t^2-\sigma_{t-1}^2}z_{t-1}\tag{3-4}
NCSN:xt=xt−1+σt2−σt−12zt−1(3-4)
然后,二者均构建了神经网络模型,根据当前输入
x
t
x_t
xt和时间
t
t
t,来估计噪声
ϵ
θ
(
x
t
,
t
)
\epsilon_{\theta}(x_t,t)
ϵθ(xt,t)或分数
s
θ
(
x
t
,
t
)
s_{\theta}(x_t,t)
sθ(xt,t)。
NCSN的原文中写作 s θ ( x t , σ ) s_{\theta}(x_t,\sigma) sθ(xt,σ),但考虑到 σ \sigma σ是一个人为设定的且只与 t t t有关的变量,为保持形式的统一,此处写为 s θ ( x t , t ) s_{\theta}(x_t,t) sθ(xt,t)
最后,二者均从一个随机采样得到的样本
x
T
x_T
xT再反向重建得到
x
0
x_0
x0,在DDPM中采用ancestral sampling的方法,在NCSN中采用的是退火朗之万动力学方法
D
D
P
M
:
x
t
−
1
=
1
1
−
β
t
(
x
t
−
β
t
ϵ
θ
(
x
t
,
t
)
)
+
β
t
z
t
(3-5)
DDPM:x_{t-1}=\frac{1}{\sqrt{1-\beta_t}}\left(x_t-\beta_t\epsilon_{\theta}(x_t,t)\right)+\sqrt{\beta_t}z_t\tag{3-5}
DDPM:xt−1=1−βt1(xt−βtϵθ(xt,t))+βtzt(3-5)
N
C
S
N
:
x
t
−
1
=
x
t
+
ϵ
s
θ
(
x
t
,
t
)
+
2
ϵ
z
t
(3-6)
NCSN:{x}_{t-1}={x}_{t}+\epsilon s_{\theta}({x}_{t},t)+\sqrt{2\epsilon}z_t\tag{3-6}
NCSN:xt−1=xt+ϵsθ(xt,t)+2ϵzt(3-6)
此处参考了SDE文中的写法,与原文中略有出入,但本质相同
3.2 统一为SDE形式
经过上述的比较,我们不难发现二者在思路和实现形式上都有很多共通之处,关键点有三个:逐步添加噪声、估计每步的噪声、逐步消除噪声,能不能用一个统一的框架来描述上述的过程呢?答案是:有的。而且上述过程都是以离散方式描述的,如果将时间步数T无限划分,我们就可以得到一个连续的变量
t
t
t,进而利用随机微分方程(SDE)来描述扩散和重建过程
d
x
=
f
(
x
,
t
)
d
t
+
g
(
t
)
d
w
(3-7)
dx=f(x,t)dt+g(t)dw\tag{3-7}
dx=f(x,t)dt+g(t)dw(3-7)
d
x
=
[
f
(
x
,
t
)
−
g
2
(
t
)
∇
x
log
p
t
(
x
)
]
d
t
+
g
(
t
)
d
w
ˉ
(3-8)
dx=[f(x,t)-g^2(t)\nabla_x\log{p_t(x)}]dt+g(t)d\bar{w}\tag{3-8}
dx=[f(x,t)−g2(t)∇xlogpt(x)]dt+g(t)dwˉ(3-8) 上式(3-7)和(3-8)分别表示扩散和重建,其中
f
(
x
,
t
)
f(x,t)
f(x,t)为漂移系数,
g
(
t
)
g(t)
g(t)为扩散系数,
w
w
w表示标准布朗运动,
d
w
dw
dw可以看作是一个极小的白噪声。那么这个SDE又是如何与DDPM和NCSN联系起来的呢?我们先看逐步添加噪声的过程,DDPM中扩散过程的离散表示(3-3),当
T
→
∞
T\rightarrow \infty
T→∞时,可以写为连续的形式
d
x
=
−
1
2
β
(
t
)
x
d
t
+
β
(
t
)
d
w
(3-9)
dx=-\frac{1}{2}\beta(t)xdt+\sqrt{\beta(t)}dw\tag{3-9}
dx=−21β(t)xdt+β(t)dw(3-9)即
f
(
x
,
t
)
=
−
1
2
β
(
t
)
x
f(x,t)=-\frac{1}{2}\beta(t)x
f(x,t)=−21β(t)x,
g
(
t
)
=
β
(
t
)
g(t)=\sqrt{\beta(t)}
g(t)=β(t)。随着
t
→
∞
t\rightarrow \infty
t→∞,公式(3-9)产生的是一个方差有界的分布,因此作者称其为方差保持的SDE(Variance Preserving SDE, VP SDE)。NCSN中的离散干扰过程(3-4)也可以写为连续的形式
d
x
=
d
[
σ
2
(
t
)
]
d
t
d
w
(3-10)
dx=\sqrt{\frac{d[\sigma^2(t)]}{dt}}dw\tag{3-10}
dx=dtd[σ2(t)]dw(3-10)即
f
(
x
,
t
)
=
0
f(x,t)=0
f(x,t)=0,
g
(
t
)
=
d
[
σ
2
(
t
)
]
d
t
g(t)=\sqrt{\frac{d[\sigma^2(t)]}{dt}}
g(t)=dtd[σ2(t)],随着
t
→
∞
t\rightarrow \infty
t→∞,公式(3-10)产生的是一个方差爆炸的分布,因此作者称其为方差爆炸的SDE(Variance Exploding SDE, VE SDE)。除了上述的两种扩散方式,其实还可以人为设定
f
(
x
,
t
)
f(x,t)
f(x,t)和
g
(
t
)
g(t)
g(t),来获取更加优化的扩散方法。比如在SDE中,作者就提出一种称为sub-VP SDE的方法
d
x
=
−
1
2
β
(
t
)
x
d
t
+
β
(
t
)
(
1
−
e
−
2
∫
0
t
β
(
s
)
d
s
)
d
w
(3-11)
dx=-\frac{1}{2}\beta(t)xdt+\sqrt{\beta(t)(1-e^{-2\int_0^t\beta(s)ds})}dw\tag{3-11}
dx=−21β(t)xdt+β(t)(1−e−2∫0tβ(s)ds)dw(3-11)其本质上是VP SDE的一个子集。
明确了噪声添加的过程后,我们再看看噪声估计的部分是如何实现的。作者给出了一个统一的连续形式的目标函数
θ
∗
=
arg min
θ
E
t
{
λ
(
t
)
E
x
(
0
)
E
x
(
t
)
∣
x
(
0
)
[
∥
s
θ
(
x
(
t
)
,
t
)
−
∇
x
(
t
)
log
p
0
t
(
x
(
t
)
∣
x
(
0
)
)
∥
2
2
]
}
(3-12)
\theta^*=\argmin_{\theta}\mathbb{E}_t\{\lambda(t)\mathbb{E}_{x(0)}\mathbb{E}_{x(t)|x(0)}[\left \|s_{\theta}(x(t),t)-\nabla_{x(t)}\log{p_{0t}(x(t)|x(0))}\right \|^2_2]\} \tag{3-12}
θ∗=θargminEt{λ(t)Ex(0)Ex(t)∣x(0)[
sθ(x(t),t)−∇x(t)logp0t(x(t)∣x(0))
22]}(3-12)上式采用了基于去噪分数匹配的目标函数,作者表示DDPM中的目标函数也可以写成上述的形式。
λ
(
t
)
\lambda(t)
λ(t)是一个反比于
E
[
∥
∇
x
(
t
)
log
p
0
t
(
x
(
t
)
∣
x
(
0
)
)
∥
2
2
]
\mathbb{E}[\left \|\nabla_{x(t)}\log{p_{0t}(x(t)|x(0))}\right \|_2^2]
E[
∇x(t)logp0t(x(t)∣x(0))
22]的权重系数。利用上式就可以对NCSN中的分数估计模型
s
θ
(
x
(
t
)
,
t
)
s_{\theta}(x(t),t)
sθ(x(t),t)或DDPM中的噪声估计模型
ϵ
θ
(
x
(
t
)
,
t
)
\epsilon_{\theta}(x(t),t)
ϵθ(x(t),t)进行训练,用于估计分数或噪声。根据B站博主VictorYuki的视频,二者之间存在如下比例关系
s
θ
(
x
(
t
)
,
t
)
=
−
1
1
−
α
ˉ
(
t
)
ϵ
θ
(
x
(
t
)
,
t
)
(3-13)
s_{\theta}(x(t),t)=-\frac{1}{\sqrt{1-\bar{\alpha}(t)}}\epsilon_{\theta}(x(t),t)\tag{3-13}
sθ(x(t),t)=−1−αˉ(t)1ϵθ(x(t),t)(3-13) 得到分数估计模型后就可以对公式(3-8)中的对数概率密度的梯度进行准确的估计,至此(3-8)中的所有参数都是已知的,通过对(3-8)求解就可以得到重建过程。通用的SDE求解器如Euler-Maruyama 和 stochastic Runge-Kutta 方法都可以用来求解(3-8)。此外作者提出一种称为Predictor-Corrector的方法,具体实现过程可参见原文,此处不再展开。
整个过程的可视化效果如下图所示,最左侧的两个正态分布曲线表示原始数据
x
(
0
)
x(0)
x(0)的分布情况
p
0
(
x
)
p_0(x)
p0(x),经过前向SDE,也就是常说的扩散阶段,得到一个接近标准正态分布的噪声分布
p
T
(
x
)
p_T(x)
pT(x),图中不同颜色的曲线可以理解为不同的样本在扩散过程中的变化。从噪声分布中采样并进行反向SDE求解,就又可以重建原始数据分布,并可以从中采样得到新的生成样本。而采集的样本也逐渐从高度随机的状态逐渐集中于两个分布的中心。
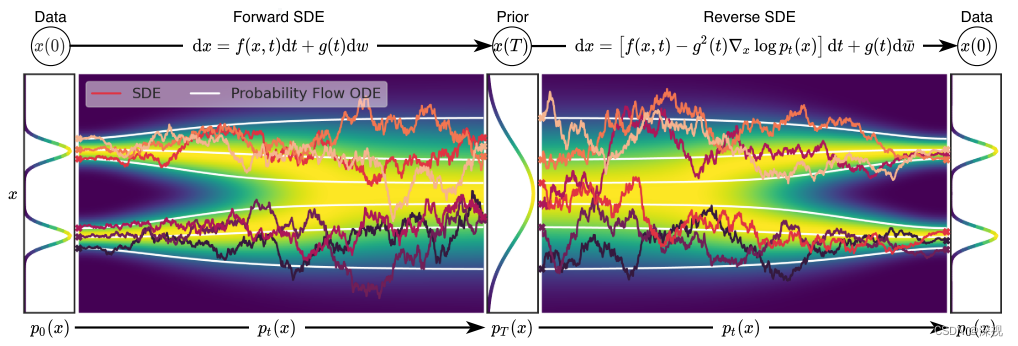
3.3 概率流常微分模型
作者还发现在SDE这个随机过程中,其实包含着一定的确定过程,该过程满足下述常微分方程(ODE)
d
x
=
[
f
(
x
,
t
)
−
1
2
g
(
t
)
2
∇
x
log
p
t
(
x
)
]
d
t
(3-14)
dx=[f(x,t)-\frac{1}{2}g(t)^2\nabla_{x}\log{p_t(x)}]dt\tag{3-14}
dx=[f(x,t)−21g(t)2∇xlogpt(x)]dt(3-14)其中,
p
t
(
x
)
p_t(x)
pt(x)表示边缘概率密度。与公式(3-8)相比,上式缺少了包含随机性的
g
(
t
)
d
w
ˉ
g(t)d\bar{w}
g(t)dwˉ的部分。当任意时刻的分数
∇
x
log
p
t
(
x
)
\nabla_{x}\log{p_t(x)}
∇xlogpt(x)都可以利用分数估计模型
s
θ
(
x
(
t
)
,
t
)
s_{\theta}(x(t),t)
sθ(x(t),t)估计得到时,重建的过程将会变成一个确定的过程。也就是说,我们从一个噪声分布里采样得到一个点
x
~
T
\tilde{x}_T
x~T,那么他就会生成唯一确定的一个样本
x
~
0
\tilde{x}_0
x~0,就像上图中白色的线条所表示的,这一点在DDPM的介绍中也有体现。这样做有什么好处呢?作者提到可以准确计算似然,可以对潜在的表征进行操作,可以获得独特的可识别的编码,可以加快采样的速度。但这样做也会丧失一定的随机性,使得生成样本的多样性降低。
3.4 条件生成
前面所将的图像生成过程都是无条件生成,生成的样本与训练样本属于同一个分布,但我们没法具体地控制生成的内容。例如,我们用教堂的数据集训练模型,则生成的样本都是属于教堂的。但如果我们同时用车辆和马匹数据集进行训练,生成的样本则会是随机的,我们不能指定生成样本所属的类别。还有一种情况,是我们希望模型在我们提供的图像基础上进行生成,比如图像修复或者重新着色等。因此,我们需要根据特定的条件,来生成图像。
假设给定条件
y
y
y,如果条件分布
p
t
(
y
∣
x
(
t
)
)
p_t(y|x(t))
pt(y∣x(t))已知,则可以生成在
y
y
y条件下的样本
p
0
(
x
(
0
)
∣
y
)
p_0(x(0)|y)
p0(x(0)∣y),只需求解如下的条件逆SDE
d
x
=
{
f
(
x
,
t
)
−
g
(
t
)
2
[
∇
x
log
p
t
(
x
)
+
∇
x
log
p
t
(
y
∣
x
)
]
}
d
t
+
g
(
t
)
d
w
ˉ
(3-15)
dx=\{f(x,t)-g(t)^2[\nabla_x\log{p_t(x)}+\nabla_x\log{p_t(y|x)}]\}dt+g(t)d\bar{w}\tag{3-15}
dx={f(x,t)−g(t)2[∇xlogpt(x)+∇xlogpt(y∣x)]}dt+g(t)dwˉ(3-15)相比于无条件SDE其中多了一个新的未知项
∇
x
log
p
t
(
y
∣
x
(
t
)
)
\nabla_x\log{p_t(y|x(t))}
∇xlogpt(y∣x(t)),可以通过一个单独的神经网络模型用于学习
log
p
t
(
y
∣
x
(
t
)
)
\log{p_t(y|x(t))}
logpt(y∣x(t)),然后再计算它的导数。作者在附录里给出了一个求解方案,感兴趣的可以去学习一下。这个工作给出了条件扩散模型的理论基础,为后面大量的条件生成工作提供了理论支持。
总结
至此,我们已经完整的介绍了DDPM、NCSN和SDE三个基于扩散模型的图像生成工作,这三个工作也是整个扩散生成领域的理论基础,后续的众多工作都是在此基础上进行改进和应用。后面,我们将介绍两个基于DDPM的改进工作:DDIM和IDDPM。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











