









26. Null-text Inversion for Editing Real Images using Guided Diffusion Models
本文提出一种文本驱动的真实图像编辑方法,号称是首次提出对真实图像进行文本编辑的方法。我们知道如果要对真实图像进行编辑,需要先将他进行扩散得到一个噪声图,然后再进行去噪,并在去噪过程中引入文本的引导,最终使得生成图像既保留原始图像的布局和形态,又根据文本条件修改了相应的内容。为了保证生成的图像和输入图像之间的相似性,现有的扩散过程,通常使用DDIM来进行扩散。但作者发现,DDIM扩散得到的噪声图在进行无条件采样时,能够得到很好的重建结果。而当增加了无分类器的文本条件引导时,生成结果就会有很大的偏差。为了解决这个问题,作者提出了两个举措:一是使用DDIM在无条件采样过程中得到的生成轨迹作为一个中枢轨迹;二是将无分类器引导采样时用到的空文本条件,改成了一个训练得到的文本条件。这样说其实是很难理解的,下面我们将会具体介绍实现的过程和思路,惯例先展示一波效果

首先,我们先回顾下现有的基于扩散模型的文本驱动图像编辑方法。给定一个输入图像
I
I
I,先按照DDIM中的扩散过程对其增加噪声得到一个噪声图
I
T
I_T
IT,这个过程就叫做DDIM inversion,和训练扩散模型时不同,这里增加的噪声不再是随机采样的
ϵ
\epsilon
ϵ,而是由训练好的噪声估计网络输出的
ε
θ
\varepsilon_\theta
εθ。当然随着LDM的提出,这个扩散过程已经不是直接对图像
I
I
I进行操作了,而是对经过编码的特征
z
0
z_0
z0进行扩散,得到加噪的特征
z
T
z_T
zT。
z
t
+
1
=
α
t
+
1
α
t
z
t
+
α
t
+
1
(
1
α
t
+
1
−
1
−
1
α
t
−
1
)
⋅
ε
θ
(
z
t
)
z_{t+1}=\sqrt{\frac{\alpha_{t+1}}{\alpha_{t}}}z_{t}+\sqrt{\alpha_{t+1}}\left(\sqrt{\frac1{\alpha_{t+1}}-1}-\sqrt{\frac1{\alpha_{t}}-1}\right)\cdot\varepsilon_{\theta}(z_{t})
zt+1=αtαt+1zt+αt+1(αt+11−1−αt1−1)⋅εθ(zt)再以
z
T
z_T
zT为起点,逐步进行反向去噪,得到生成结果
z
0
z_0
z0,这个去噪过程也就是采样,其过程如下
z
t
−
1
=
α
t
−
1
α
t
z
t
+
α
t
−
1
(
1
α
t
−
1
−
1
−
1
α
t
−
1
)
⋅
ε
θ
(
z
t
)
z_{t-1}=\sqrt{\frac{\alpha_{t-1}}{\alpha_t}}z_t+\sqrt{\alpha_{t-1}}\left(\sqrt{\frac{1}{\alpha_{t-1}}-1}-\sqrt{\frac{1}{\alpha_t}-1}\right)\cdot\varepsilon_\theta(z_t)
zt−1=αtαt−1zt+αt−1(αt−11−1−αt1−1)⋅εθ(zt)其中
ε
θ
\varepsilon_\theta
εθ是一个噪声估计器,其根据上一时刻的输出结果
z
t
z_t
zt,时刻
t
t
t和文本条件
C
C
C预测噪声。在这个基础上CDM方法又提出一种无分类器引导的方法,被众多的生成和编辑方法所采用。具体来说就是在这个有文本条件引导的估计噪声的基础上,再增加一个无条件引导的估计噪声,二者按照一定的权重相加,如下
ε
~
θ
(
z
t
,
t
,
C
,
∅
)
=
w
⋅
ε
θ
(
z
t
,
t
,
C
)
+
(
1
−
w
)
⋅
ε
θ
(
z
t
,
t
,
∅
)
\tilde{\varepsilon}_\theta(z_t,t,\mathcal{C},\varnothing)=w\cdot\varepsilon_\theta(z_t,t,\mathcal{C})+(1-w) \cdot\varepsilon_\theta(z_t,t,\varnothing)
ε~θ(zt,t,C,∅)=w⋅εθ(zt,t,C)+(1−w)⋅εθ(zt,t,∅)其中
∅
\varnothing
∅是表示文本条件为空。现有的方法大多在研究如何训练一个更好的噪声估计模型
ε
θ
\varepsilon_\theta
εθ或者如何优化文本条件
C
\mathcal{C}
C,但本文另辟蹊径从初始起点
z
T
z_T
zT和空文本条件
∅
\varnothing
∅着手,提出一种新的改进思路。这里要强调一下,本文并不是直接研究图像编辑的采样阶段的,而是研究Inversion过程,具体的文本驱动的图像编辑采用了Prompt-to-Prompt的方法。
作者发现当没有文本条件引导时,即权重
w
=
0
w=0
w=0时,DDIM Inversion过程产生的误差很小可以忽略不记。但在有文本条件引导时,这个偏差会随着采样过程不断累积,并且会随着权重
w
w
w的增长而被放大,导致最后得到的噪声不再属于高斯分布。那么怎么解决这个问题呢?作者取了一个折衷的方法,先进行DDIM Inversion得到一个中枢噪声轨迹
{
z
t
∗
}
\{z_t^*\}
{zt∗}其终点是
z
T
∗
z_T^*
zT∗,过程中权重
w
=
1
w=1
w=1,也就是使用文本引导条件,但是不用无分类器引导。然后,以这个噪声
z
T
∗
z_T^*
zT∗为起点,进行逐步去噪,并且在去噪过程中希望每个时刻对应的去噪结果
z
t
z_{t}
zt能够与中枢噪声轨迹中对应的噪声向量
z
t
∗
z_t^*
zt∗尽可能地相近,从而减少采样结果与原始图像之间的差异,目标函数也很简单
min
∥
z
t
−
1
∗
−
z
t
−
1
∥
2
2
\min\begin{Vmatrix}z_{t-1}^*-z_{t-1}\end{Vmatrix}_2^2
min
zt−1∗−zt−1
22如下图中的上半部分所示。
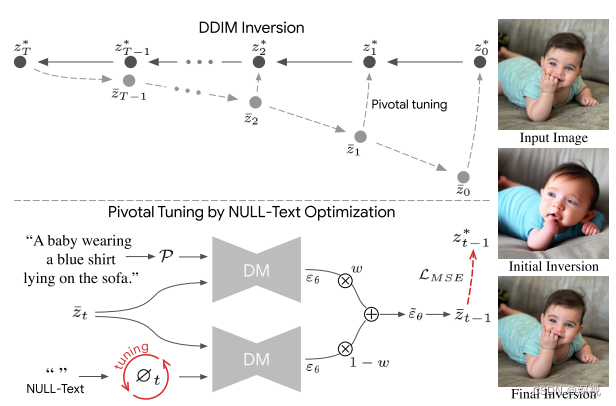
可能有人会有疑问了,噪声估计器在训练扩散模型时就已经训练好了,是确定的。那么采样过程应该也是确定了呀?有什么可以被训练呢?难道要再对噪声估计器进行训练嘛?作者说:不用!模型不用训练,文本条件也不需要训练!我们训练的是无分类器引导中的空白文本条件
∅
\varnothing
∅。有人又要问了,不是说不用无分类器引导了嘛?那是初始的时候,为了得到一个更好的空白文本条件
∅
\varnothing
∅,我们要将
w
w
w设置为7.5(LDM中的默认参数),让他来引导生成过程。不仅如此,我们是对每个时刻的
∅
t
\varnothing_t
∅t都进行优化,得到一组最优的
{
∅
t
}
t
=
1
T
\{\varnothing_t\}_{t=1}^T
{∅t}t=1T。具体而言就是将空白文本转换成一个可训练的嵌入特征,然后用上文提出的目标函数在采样的过程中对每个时刻对应的
∅
t
\varnothing_t
∅t进行优化
min
∅
t
∥
z
t
−
1
∗
−
z
t
−
1
(
z
t
ˉ
,
∅
t
,
C
)
∥
2
2
\operatorname*{min}_{\varnothing_{t}}\left\|{z_{t-1}^{*}}-z_{t-1}(\bar{z_{t}},\varnothing_{t},\mathcal{C})\right\|_{2}^{2}
∅tmin
zt−1∗−zt−1(ztˉ,∅t,C)
22其中
z
ˉ
t
−
1
=
z
t
−
1
(
z
ˉ
t
,
∅
t
,
C
)
\bar{z}_{t-1}=z_{t-1}(\bar{z}_{t},\varnothing_{t},\mathcal{C})
zˉt−1=zt−1(zˉt,∅t,C)要注意到目前未知我们还没有涉及到图像编辑的内容,这里的文本条件
C
C
C也是输入图像的文本描述,而不是目标图像的文本描述。就像我们前面提到的,我们折腾了一大圈才只是得到了一个不错的Inversion结果
z
T
ˉ
=
z
T
∗
\bar{z_T}=z_T^*
zTˉ=zT∗,也就是
w
=
1
w=1
w=1时DDIM Inversion的结果, 和一系列经过优化的空白文本引导条件
{
∅
t
}
t
=
1
T
\{\varnothing_t\}_{t=1}^T
{∅t}t=1T。将二者与目标文本描述
P
∗
P^*
P∗按照Prompt-to-Prompt的方法输入到一个训练好的LDM模型中就可以得到对应的编辑结果啦。

与其他的文本驱动图像编辑算法的效果对比




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











