






OpenNMT是一个用于神经机器翻译和神经序列学习的开源生态系统。
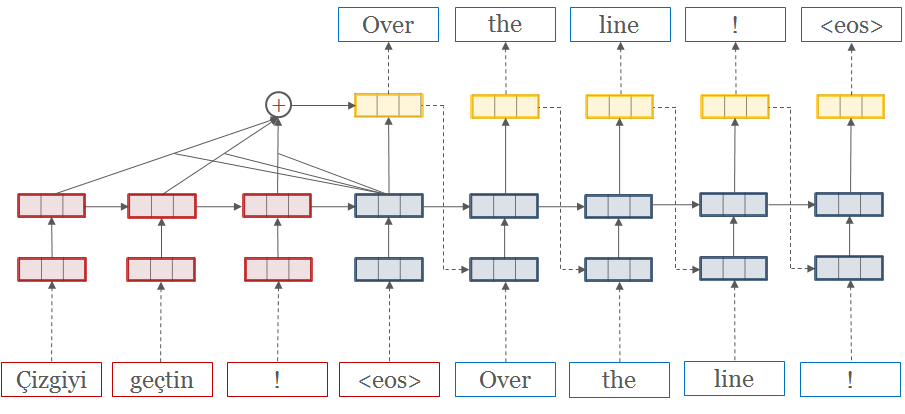
国内教程的挺少的,所以自己跑了个哈英翻译的。
我用的是GPU是 NVIDIA A10 OpenNMT框架用的是 PyTorch
其他语言翻译也是一个逻辑。
OpenNMT-py 需要的版本:
- Python >= 3.8
- PyTorch >= 1.13 <2
本文 ipynb文件:
关注公众号: AKeTech 回复 200529
首先更新下软件包列表
sudo apt-get update
升级下pip
pip install --upgrade pip
当然前两步不是必须
安装下PyTorch,我安装的版本是1.13.1,还有torchvision和CUDA
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
安装OpenNMT-py
pip install OpenNMT-py
准备数据
这是我的数据,是json形式的,里面包含中英哈翻译。
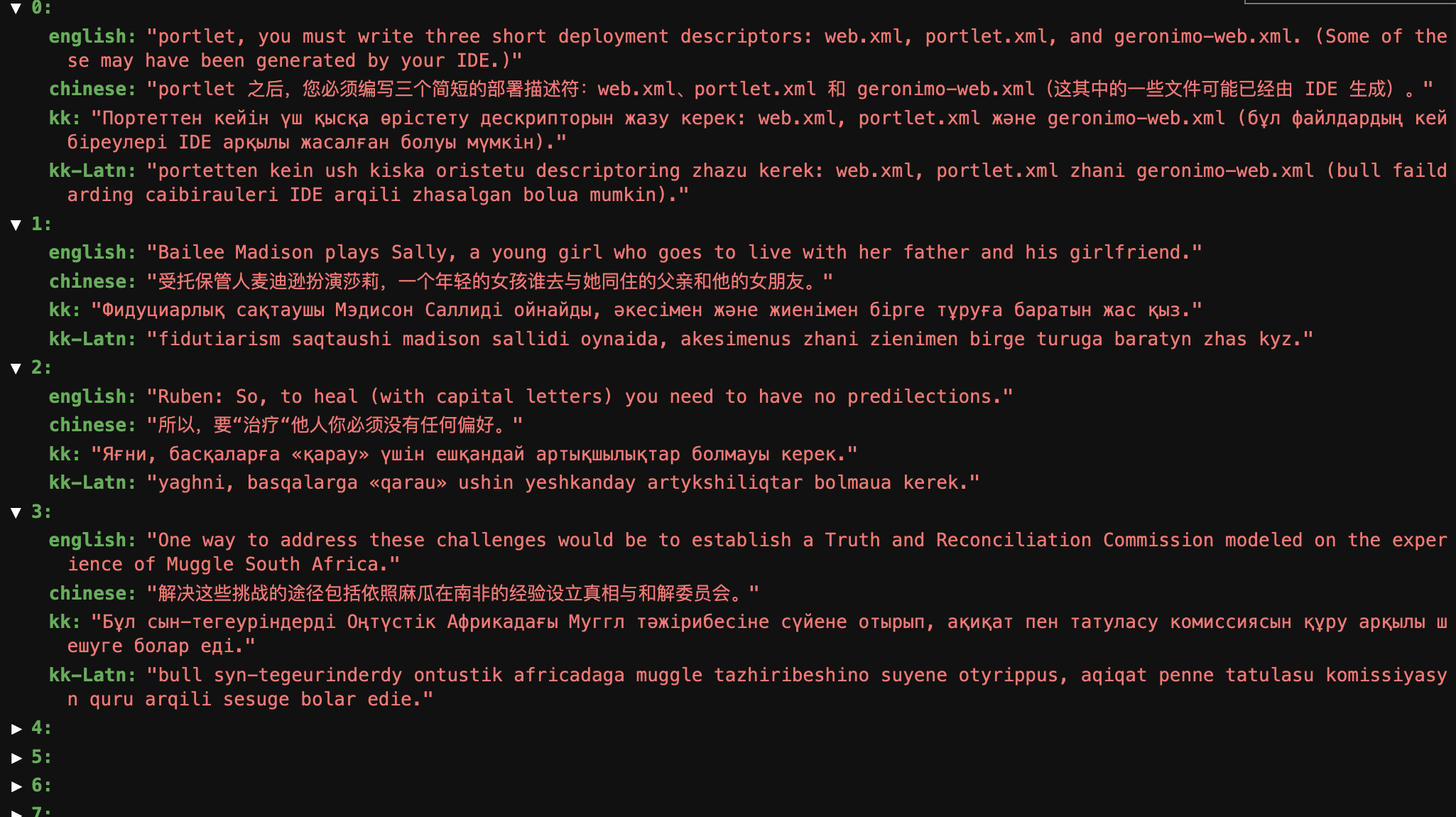
处理数据
# 这个就是把我的json数据的英语和哈语分别放在两个文件中
import json
# 从文件中读取 JSON 数据
with open('output.json', 'r') as f:
data = json.load(f)
source_english=""
source_kk=""
# 将数据写入文件夹中的源语言和目标语言文件
for i, item in enumerate(data):
english = item['english']
kk = item['kk']
source_english+=english+'\n'
source_kk+=kk+'\n'
with open(f'source.txt', 'w', encoding='utf-8') as f1:
f1.write(source_english)
with open(f'target.txt', 'w', encoding='utf-8') as f2:
f2.write(source_kk)
print('ok')
# 读取两个文件并将其存储在两个列表 source 和 target 中
# 然后,计算两个列表中较短的长度,并使用切片操作截取两个列表,使它们的长度一样
all_parallel = []
source_root = 'source.txt'
target_root = 'target.txt'
source = open(source_root).readlines()
target = open(target_root).readlines()
min_len = min(len(source), len(target))
source = source[:min_len]
target = target[:min_len]
import os
from sklearn.model_selection import train_test_split
# 使用 train_test_split 函数将源语言和目标语言的句子对划分为训练集和验证集
# test_size 参数指定了验证集的大小,这里设置为 10000
# random_state 参数用于设置随机种子,以确保每次运行代码时得到相同的划分结果。
# 返回值是四个列表对象,分别为训练集和验证集的源语言和目标语言句子列表
src_train, src_val, tgt_train, tgt_val = train_test_split(
source, target, test_size=10000, random_state=227)
# 英文 -> 哈萨克
# 将划分好的训练集和验证集写入到四个文件中,分别为 src-train.txt、tgt-train.txt、src-val.txt 和 tgt-val.txt。
with open('src-train.txt', 'w') as fp:
fp.write(''.join(tgt_train))
with open('tgt-train.txt', 'w') as fp:
fp.write(''.join(src_train))
with open('src-val.txt', 'w') as fp:
fp.write(''.join(tgt_val))
with open('tgt-val.txt', 'w') as fp:
fp.write(''.join(src_val))
# src -> source 显示下前几个句子
! head src-train.txt
# tgt -> target
!head tgt-train.txt
# 设置模型保存的路径。
model_root = 'modern'
# 创建
!mkdir -p '{model_root}'
# 生成一个 YAML 格式的配置文件
# - `save_data`:指定数据集和词汇表的保存路径。
# - `src_vocab` 和 `tgt_vocab`:指定源语言和目标语言的词汇表文件路径。
# - `src_vocab_size` 和 `tgt_vocab_size`:指定词汇表的大小,即最多包含多少个词汇。
# - `share_vocab`:表示是否共享源语言和目标语言的词汇表。
# - `queue_size` 和 `bucket_size`:控制数据加载和处理的并行度。
# - `world_size` 和 `gpu_ranks`:指定使用的 GPU 数量和编号。
# - `batch_size` 和 `valid_batch_size`:指定训练集和验证集的批次大小。
# - `data`:指定训练集和验证集的文件路径。
# - `save_model`:指定模型文件的保存路径。
# - `save_checkpoint_steps`、`train_steps` 和 `valid_steps`:控制模型训练和保存的频率。
# https://opennmt.net/OpenNMT-py/options/train.html
# https://github.com/OpenNMT/OpenNMT-py/blob/master/docs/source/FAQ.md#how-do-i-use-the-transformer-model-do-you-support-multi-gpu
yml = f'''# train.yaml
## Where the samples will be written
save_data: {model_root}
## Where the vocab(s) will be written
src_vocab: {model_root}/src.vocab
tgt_vocab: {model_root}/src.vocab
src_vocab_size: 200000
tgt_vocab_size: 200000
share_vocab: true
# Batching
queue_size: 100
bucket_size: 2048
world_size: 1
gpu_ranks: [0]
batch_size: 32
valid_batch_size: 16
# Corpus opts:
data:
corpus_1:
path_src: src-train.txt
path_tgt: tgt-train.txt
valid:
path_src: src-val.txt
path_tgt: tgt-val.txt
# Where to save the checkpoints
save_model: {model_root}/model
save_checkpoint_steps: 10000
train_steps: 1000000
valid_steps: 10000
'''
with open('train.yaml', 'w') as fp:
fp.write(yml)
# 显示最后几个句子
!tail src-train.txt
!tail tgt-train.txt
!tail src-val.tx
!tail tgt-val.txt
构建训练模型所必需的词汇表
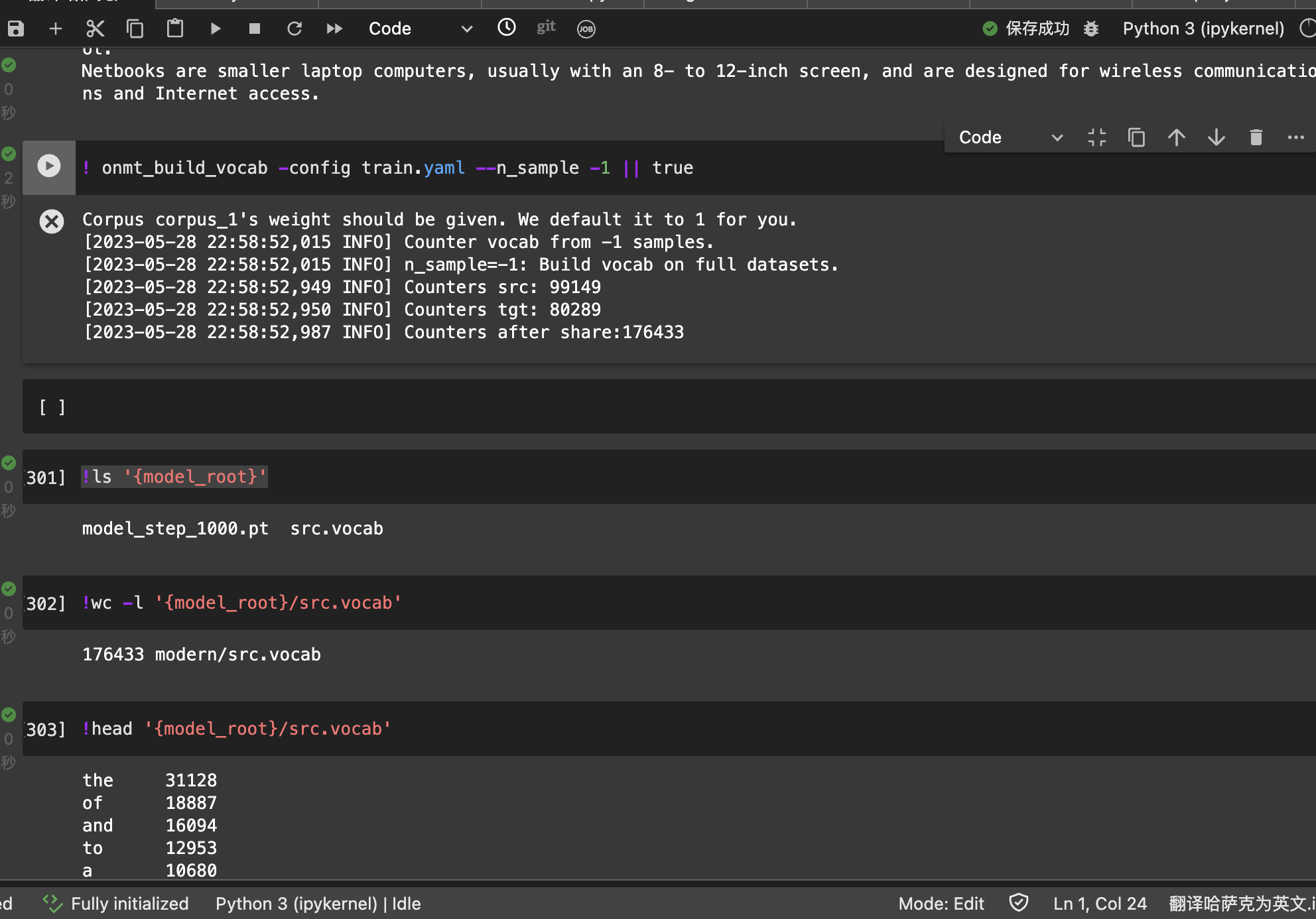
# -1表示所有
! onmt_build_vocab -config train.yaml --n_sample -1 || true
-n_sample这里是必需的——它代表从每个语料库中抽取的用于构建词汇表的行数。
# 目录下的文件和文件夹列表
!ls '{model_root}'
训练
!onmt_train -config train.yaml
我这里出现了个问题:
cuDNN version incompatibility: PyTorch was compiled against (8, 5, 0) but found runtime version (8, 2, 0). PyTorch already comes bundled with cuDNN. One option to resolving this error is to ensure PyTorch can find the bundled cuDNN.Looks like your LD_LIBRARY_PATH contains incompatible version of cudnnPlease either remove it from the path or install cudnn (8, 5, 0)
PyTorch 编译时使用的 cuDNN 版本与当前运行环境中的 cuDNN 版本不兼容。
解决方案:将其路径添加到 LD_LIBRARY_PATH 环境变量中
export LD_LIBRARY_PATH=/home/pai/lib/python3.9/site-packages/torch/lib:$LD_LIBRARY_PATH
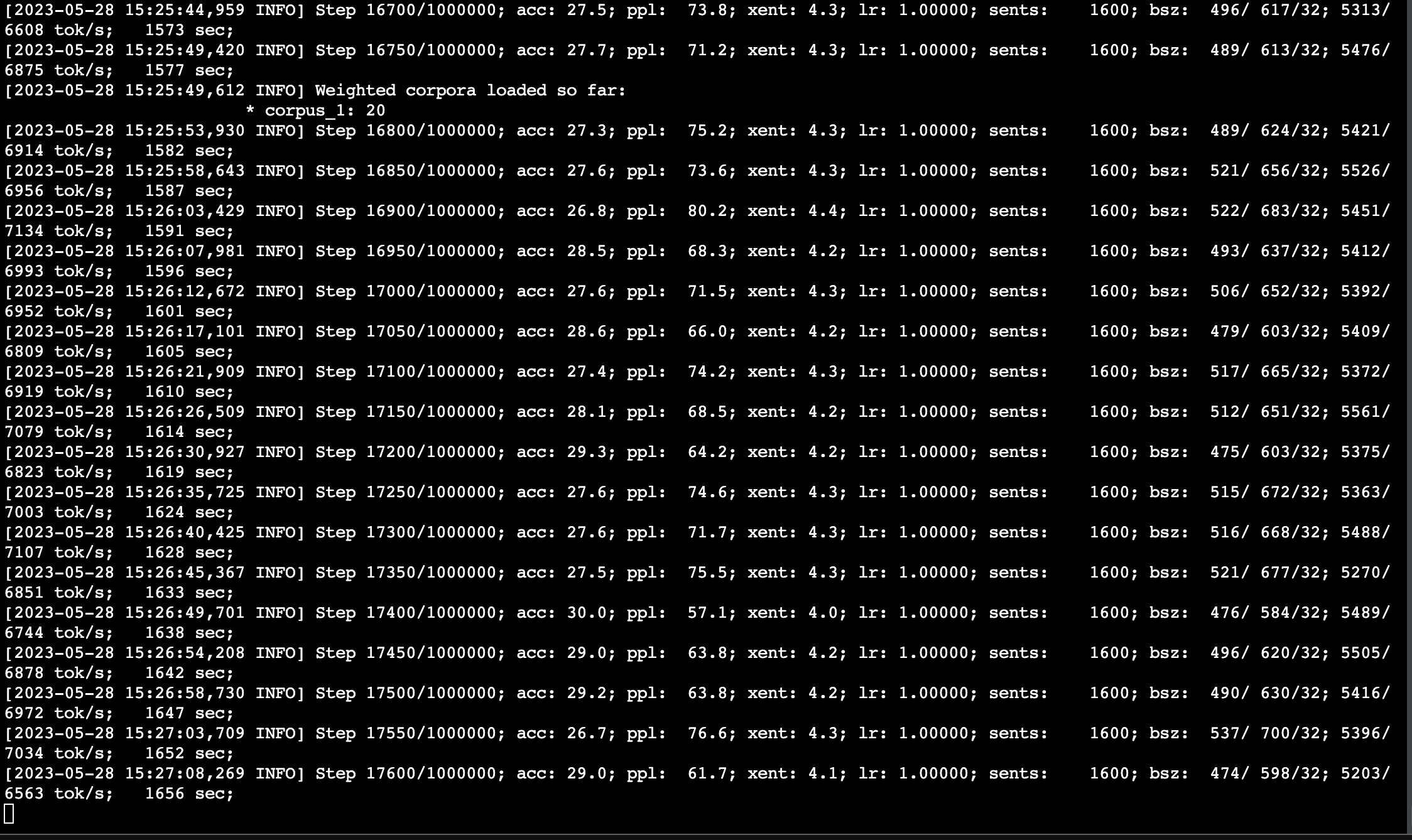
Step:表示当前训练的步数和总步数;acc:表示当前训练的准确率;ppl:表示当前训练的困惑度;xent:表示当前训练的交叉熵损失;lr:表示当前学习率;sents:表示当前训练的句子数量;bsz:表示当前批次的大小;tok/s:表示当前处理的单词数;sec:表示当前训练所花费的时间。
测试训练的模型
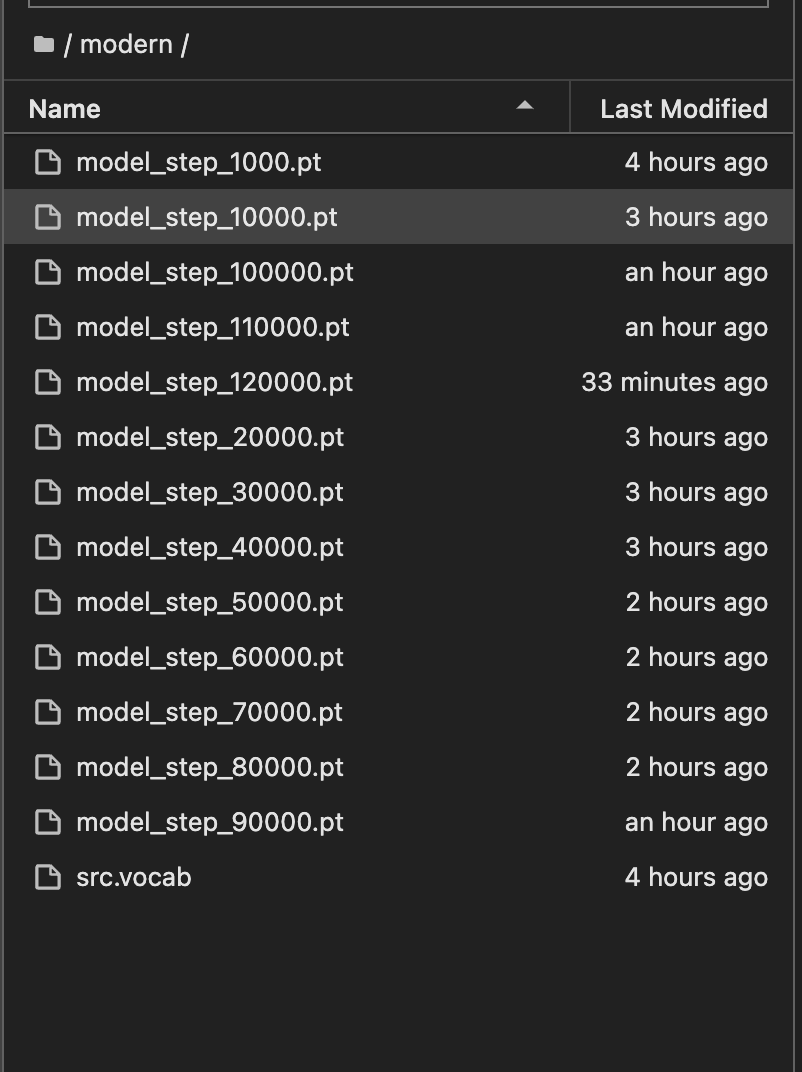
训练了12万多次就停了,训练的有点多哈哈,第一次可以搞个几万,别搞太多。
这里的1万到12万指的是每隔 10000 步就保存一次。在yaml文件中的 save_checkpoint_steps
通常情况下,训练步数越大的模型参数文件所保存的模型性能也会更好,因为它经过了更多次的训练迭代。
# 写入文件
with open(f'test.txt', 'w', encoding='utf-8') as f1:
f1.write('қолданамыз.')
# 翻译
! onmt_translate --model '{model_root}/model_step_120000.pt' --src test.txt --output put.txt
# 输出
! cat put.txt
我这里因为数据集很小,所以翻译结果非常糟糕。
基本都是胡说八道哈哈。
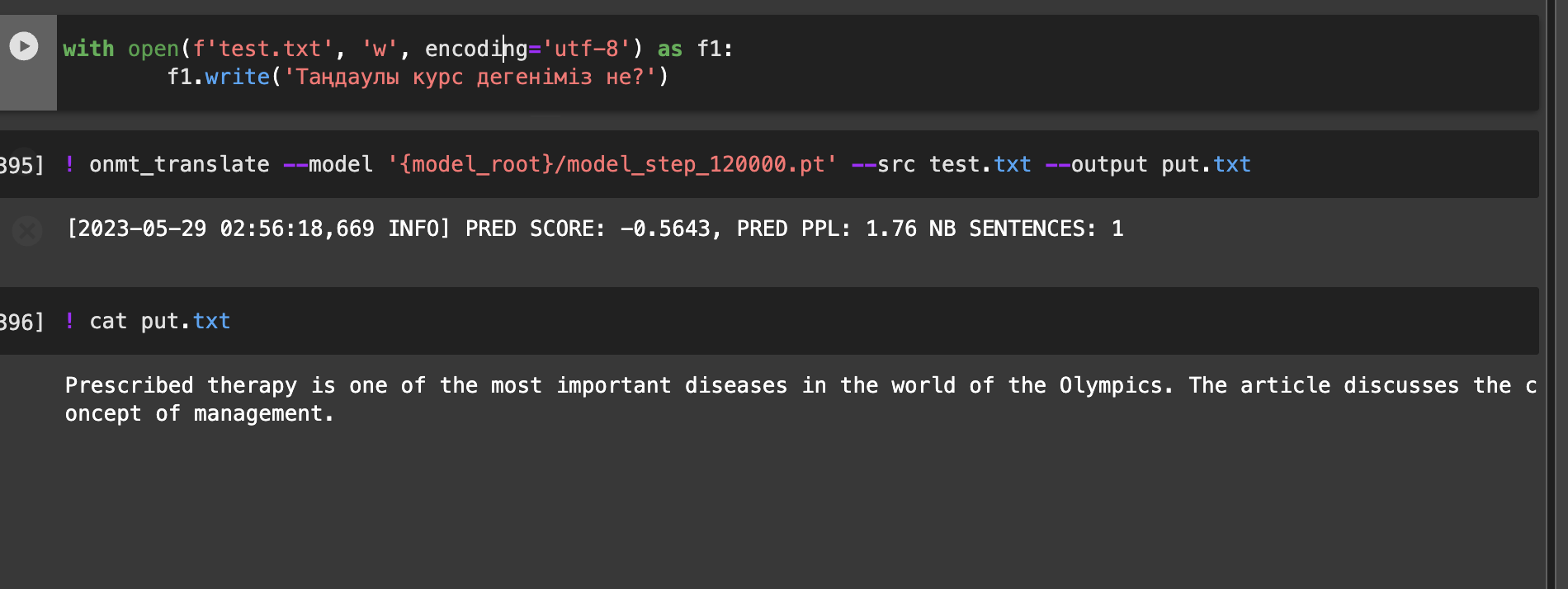
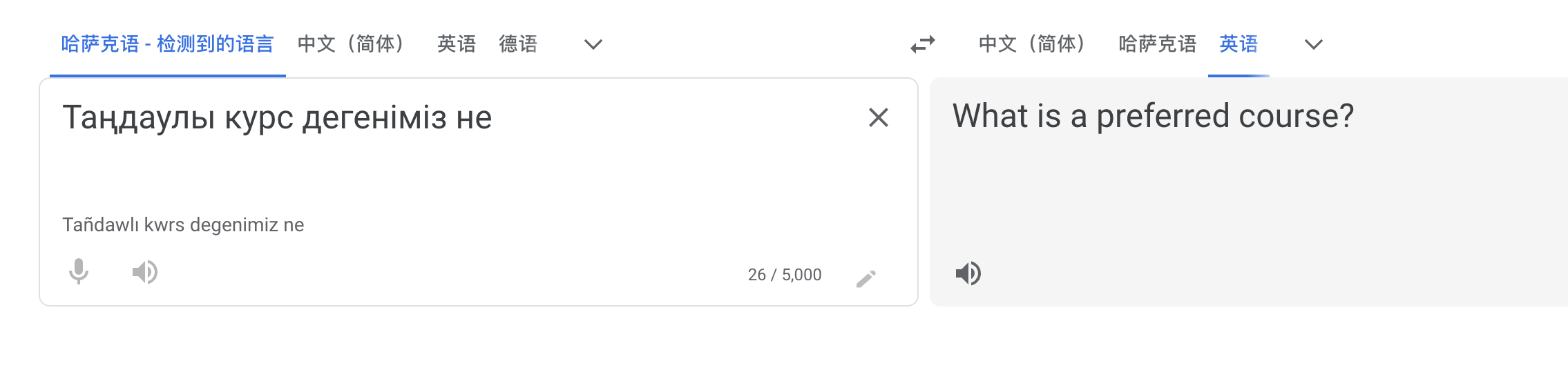
每个模型的结果可能会是不一样的。
结束!
如果想研究一些其他的技术,欢迎关注公众号:AKeTech
















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









