







TOS 2023 Paper 分布式元数据论文阅读笔记整理
问题
基于对象的存储系统被广泛用于各种场景,例如文件存储、块存储、blob存储(例如,大型视频)等,其中数据被放置在大量对象存储设备(OSD)之中。数据放置对于分对象的存储系统的可扩展性至关重要。最先进的CRUSH放置方法是一种去中心化算法,它可以确定地将对象副本放置到存储设备上,而不依赖于中心目录。
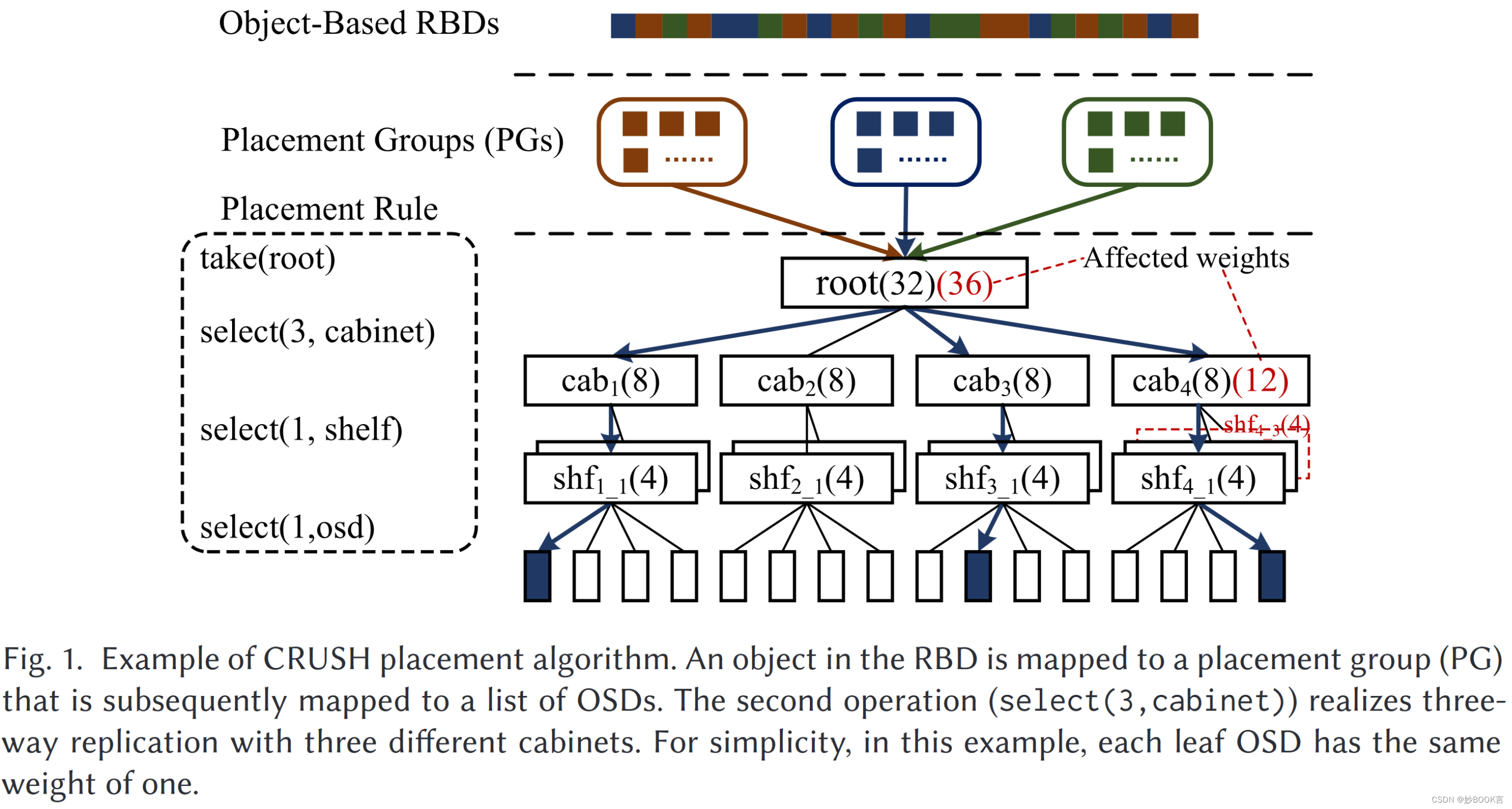
但基于CRUSH的存储系统在扩展存储集群的容量时,会遭受不受控制的数据迁移,这是由CRUSH的性质决定的,并且在频繁扩展时会导致显著的性能下降。

现有方法局限性
为了缓解CRUSH的迁移风暴,Ceph[69]采用了实现级优化来延迟迁移。它将迁移率限制在相对较低的水平,如果写入的对象正在等待迁移,则会(临时)对旧的OSD执行新的写入。然而,所有对象最终都必须迁移到CRUSH算法计算的目标OSD,这使得Ceph在更长的时间内性能下降,这对于延迟敏感的应用程序来说是不可取的。
本文方法
本文介绍了MapX,是CRUSH的扩展,使用额外的时间维度映射(从对象创建时间到集群扩展时间)来控制集群扩展后的数据迁移。每个扩展都被视为CRUSH映射的一个新层,由CRUSH根下的一个虚拟节点表示。MapX通过操纵中间放置组(PG)的时间戳来控制从对象到层的映射,允许现有对象驻留在其当前层中,而无需在扩展后移动到新添加的OSD。MapX适用于各种基于对象的存储场景,其中对象时间戳可以作为更高级别的元数据进行维护。
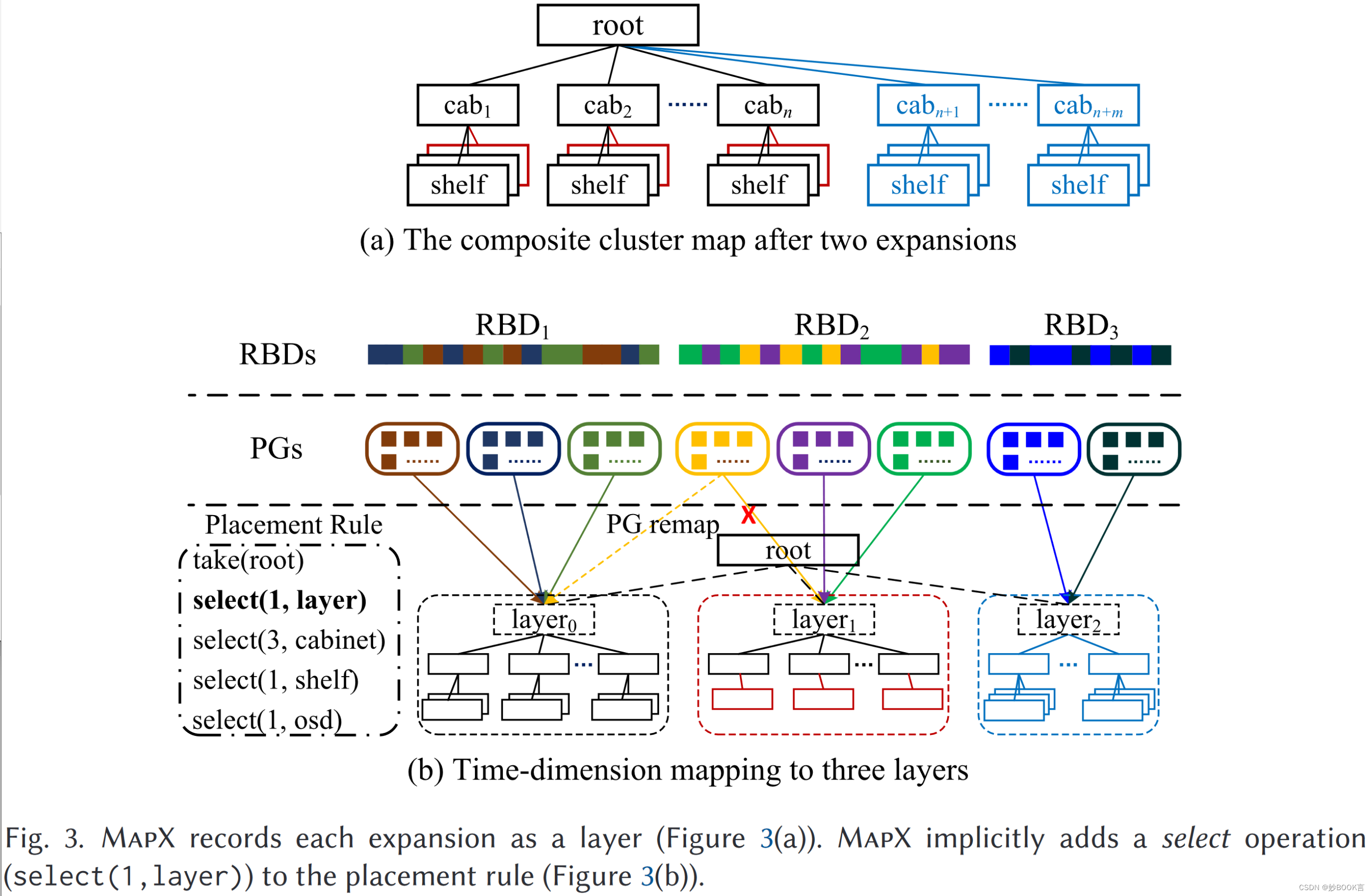
MapX无法支持通用对象存储(如Swift[14]、MinIO[12]和Ceph RADOS[8]),因为对象元数据的维护开销巨大。MapX适用于各种基于对象的存储场景(如块存储和文件存储),其中对象创建时间戳可以作为更高级别的存储元数据进行维护。目前已将MapX应用于最先进的Ceph RBD(RADOS块设备),以实现迁移可控、去中心化的基于对象的块存储(称为Oasis)。Oasis扩展了RBD元数据结构,以在扩展层的粒度上维护和检索近似的对象创建时间(用于迁移控制)。
开源代码:GitHub - nicexlab/ceph at mpx
实验结果表明,基于MapX的Oasis块存储在尾延迟方面优于基于CRUSH的Ceph RBD 3.17×~4.31×,在读(写)IOPS方面提升76.3%(83.8%)。
实验
实验环境:四台机器,三台机器运行Ceph OSD存储服务器,另一台机器运行客户端。每台机器都有双20核Xeon E5-2630 2.20 GHz CPU、128 GB RAM、一个10 GbE NIC、CentOS 7。每台存储机器最初都有两个7200 RPM 2 TB的HDD,通过在每台存储机上添加两个HDD来扩展存储容量。
数据集:FIO
实验对比:尾延迟,IOPS,计算开销,迁移PG比例
实验参数:I/O大小,I/O深度,读写,写比例,扩展级别,多次扩展
总结
对Ceph中CRUSH算法的优化,如何实现扩展时避免过多数据迁移。本文提出MapX,使用额外的时间维度映射(从对象创建时间到集群扩展时间)来控制集群扩展后的数据迁移。将每个扩展都视为CRUSH映射的一个新层,由CRUSH根下的一个虚拟节点表示。MapX通过操纵PG的时间戳来控制从对象到层的映射,使现有对象驻留在其原始层,新对象映射到新层中。
















 9757
9757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











