









强化学习笔记一 初章
from https://www.bilibili.com/video/BV1LE411G7Xj?spm_id_from=333.337.search-card.all.click
第一轮学习笔记,之后二轮的时候会再整理一遍
一、基本概念
Difference between Reinforcement Learning and Supervised Learning
- Sequential data as input (not i.i.d)
- 体现出来强化学习是时间关联的 Time matters (sequential data, non i.i.d data)
- The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.
- 这里体现了强化学习中:Agent‘s actions affect the subsequent data it receives(agent’s action changes the environment)
- Trial-and-error exploration(balance between exploration and exploitation 勘探和开发的平衡)
- exploration 探索新事物
- exploitation 保留过去记录的最大值
- There is no supervisor, only a reward signal, which is also delayed.
强化学习的能力上限?
强化学习的特点,产生了这样的一个优势:
Big deal: Able to Achieve Superhuman Performance
监督学习的上界是人类的能力,而强化学习的上限是超人的能力。
- Upper bound for supervised learning is human-performance.
- Upper bound for reinforcement learning ?

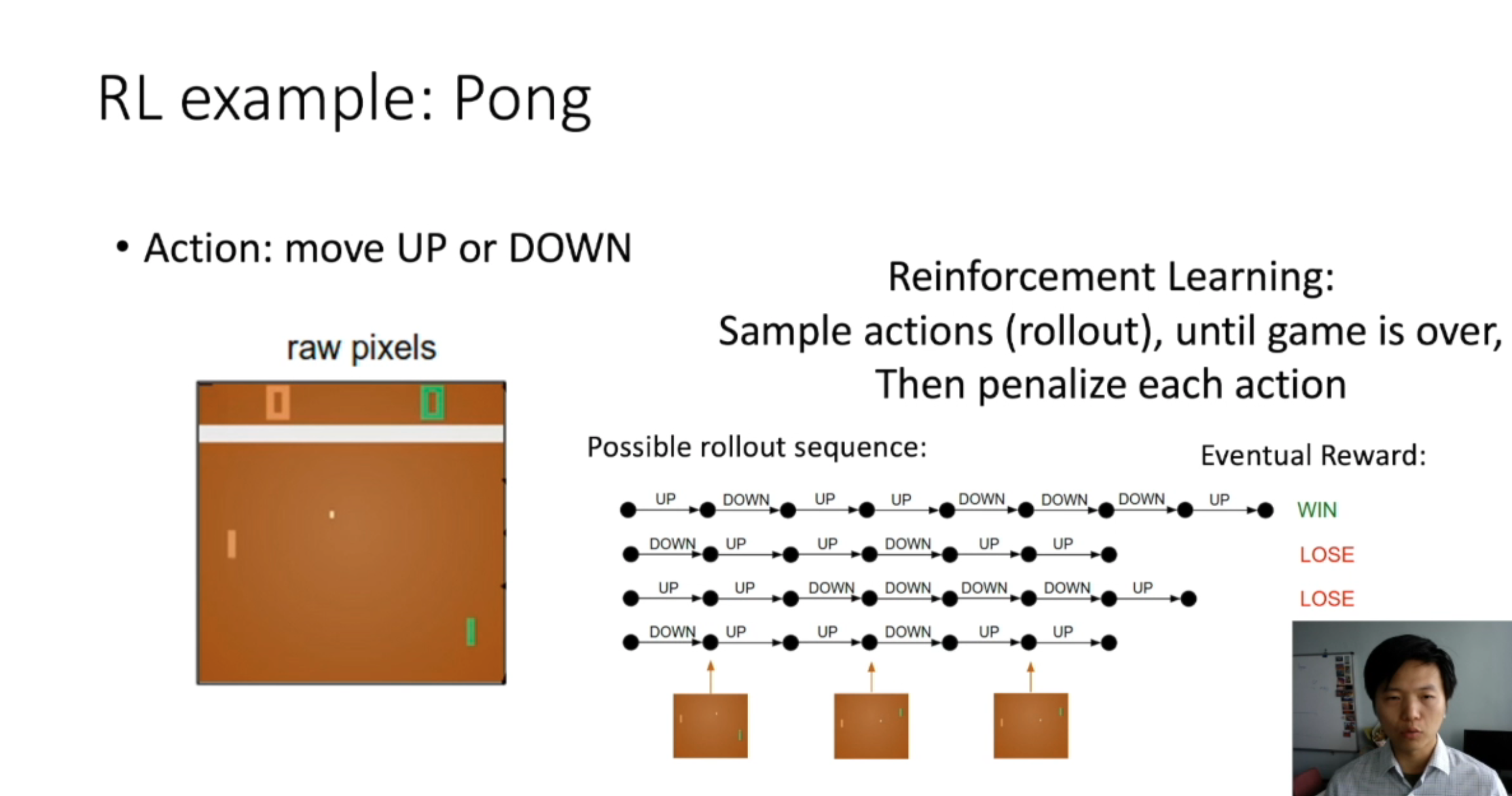
RL example: Pong
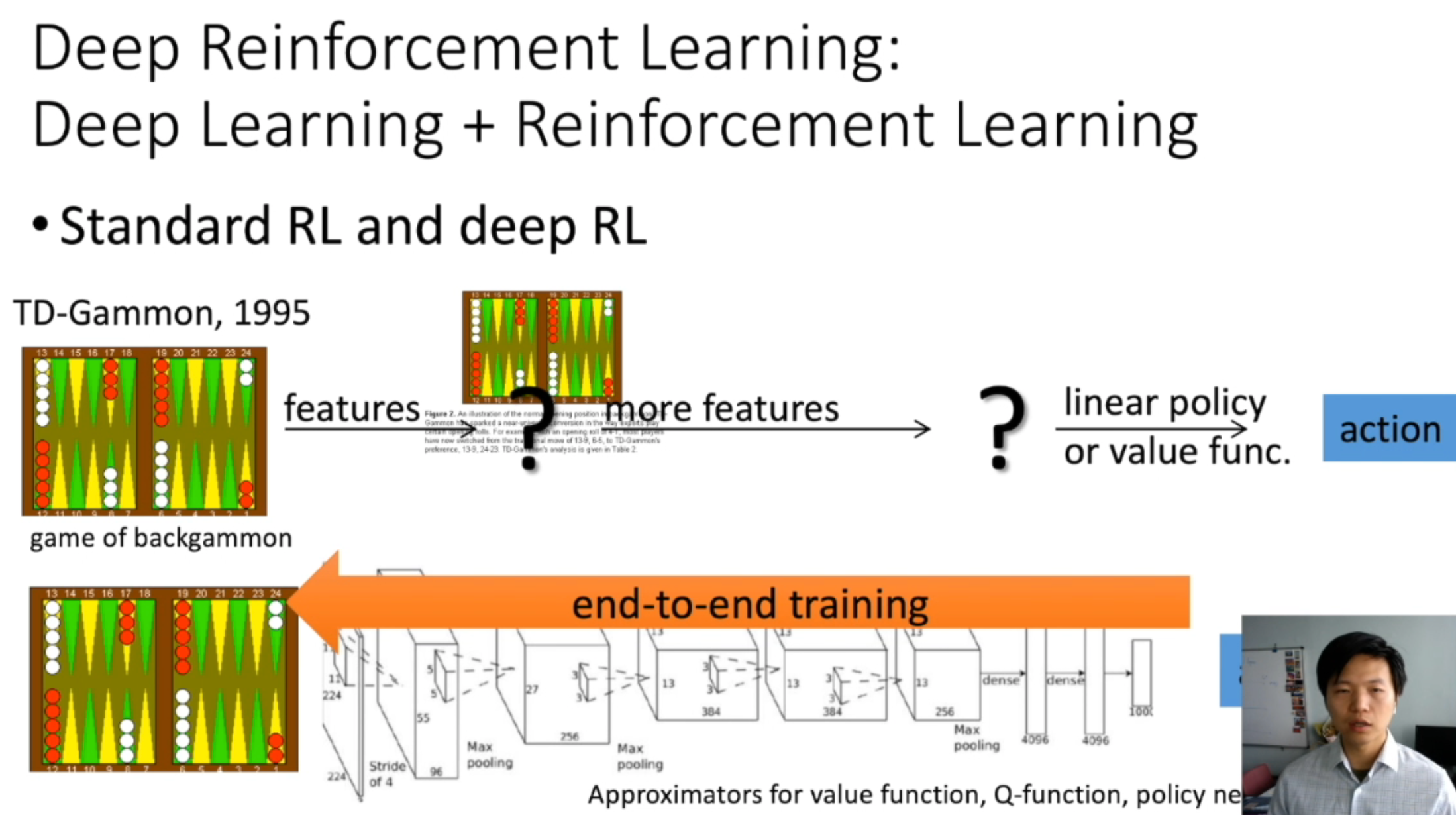
Deep Reinforcement Learning:
Deep Learning + Reinforcement Learning
我的理解是,传统的rl是由人类手动提取特征,然后根据这些特征信息和一个模型来预测出对应的action;而drl是由机器来提取特征,实现端到端的训练。

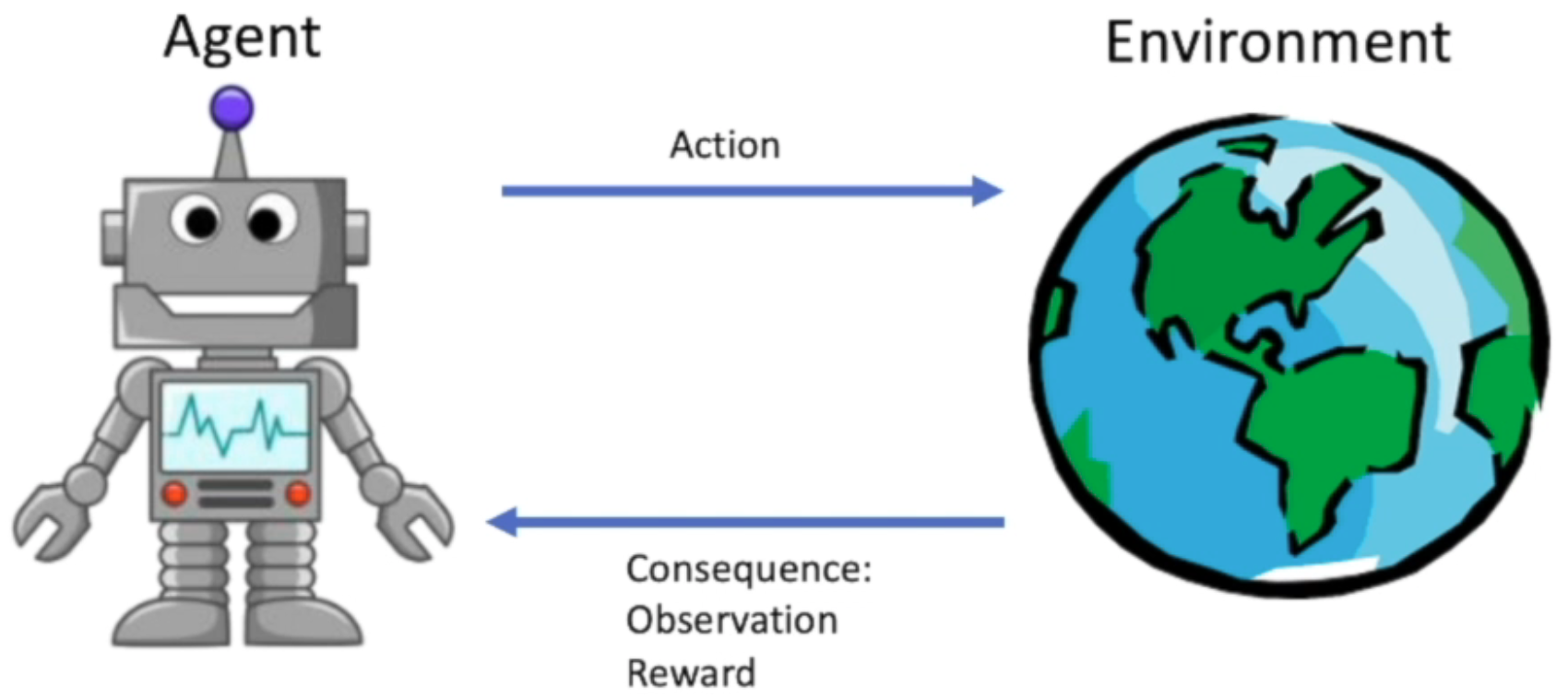
强化学习研究的问题是agent 和 环境之间的交互
the agent learns ro interact with the environment
Major Components of an RL Agent(强化学习中一个Agent的主要组成成分)
An RL agent may include one or more of these components:
- Policy: agent’s behavior function
- Value function: how good is each state or action
- Model: agent’s state representation of the environment
强化学习的分类
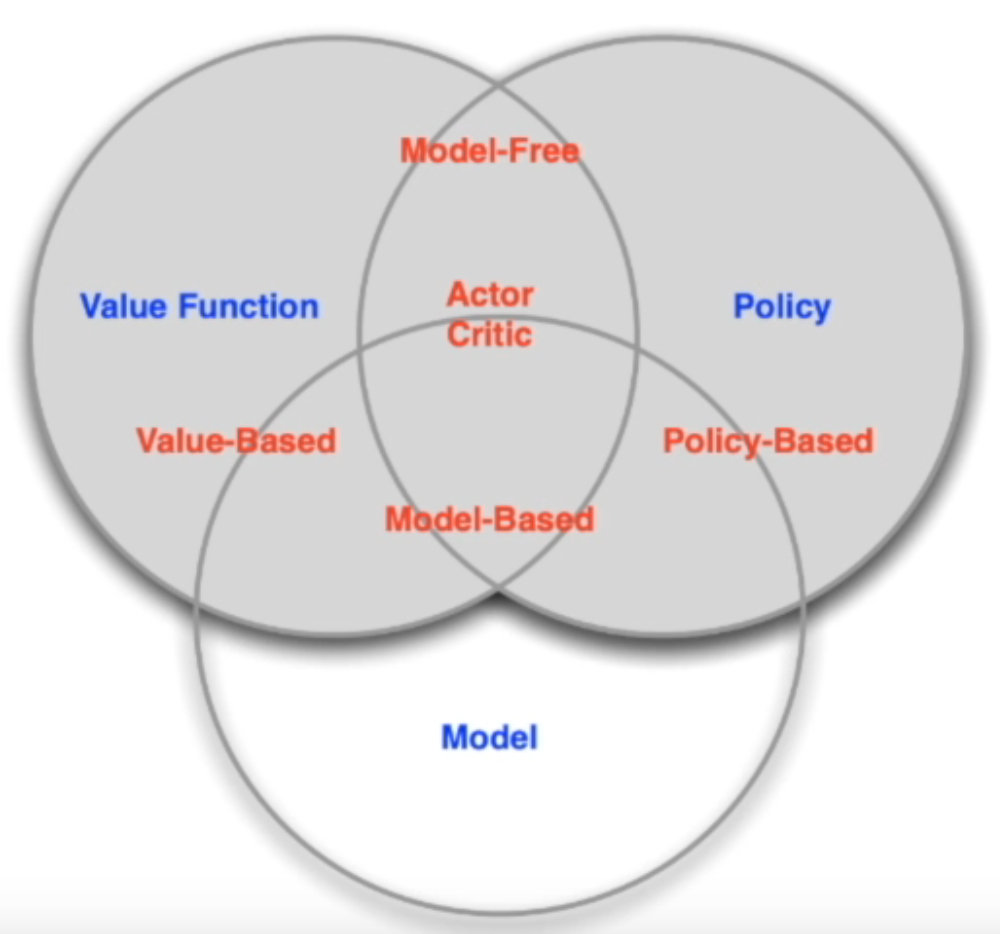
Types of RL Agents based on What the Agent Learns
-
Value-based agent:
学习价值函数

- Explicit: Value function
- Implicit: Policy(can derive a policy from value function)
-
Policy-base
学习策略
给定当前的状态,来学习policy
- Explicit: policy
- No value function
-
Actor-Critic agent:
将上面两种内容结合
将策略函数和价值函数都学习了,通过这两者的交互得到一个最佳的行为
- Explicit: policy and value function
Types of RL Agents on if there is model
根据有没有学习环境模型来分类
-
Model-based
通过学习状态转移来采取措施
- Explicit: model
- May or may have policy and/or value function
-
Model-free
没有学习状态转移,而是只通过policy 和 value function来进行决策
- Explicit: value function and/or policy function
- No model
Exploration and Exploitation
Exploration表示我们怎么去探索环境,通过尝试不同的行为,可以得到一个获得最大奖励的策略
Exploitation表示我们现在不去尝试新的东西,就采取我们现在已知的得到很大奖励的行为
所以说这里就面临一个trade-off,怎么通过 牺牲短期的reward来获得行为的理解
- Agent only experiences what happens for the actions it tries!
- How should an RL agent balance its actions?
- Exploration: trying new things that might enable the agent to make better decisions in the future
- Exploitation: choosing actions thata are expected to yield good reward given the past experience
- Often there may be an exploration-expoitation trade-off
- May have to sacrifice reward in order to explore & learn about potentially better policy
比如说在下面的餐馆选择中:
- Restaurant Selection
- Exploiation: Go to your favourite restaurant
- Exploration: Try a new restaurant
或者是在广告推荐的任务中:
- Online Banner Advertisements
- Exploitation: show the most successful advert
- Exploration: show a different advert
- 挖油田的任务中
- 搜索: 挖已知的油田
- 利用:尝试一个新的未知油田
其他
- https://openai.com/
- 一家非盈利公司,提供了很多ai的内容。
import gym
env = gym.make("Taxi-v2")
observation = env.reset()
agent = load_agent()
for step in range(100):
action = agent(observation)
observation, reward, done, info = env.step(action)
二、马尔科夫决策过程
from https://github.com/metalbubble/RLexample
马尔科夫决策过程
- Last Time
- Key elements of an RL agent:model,value, policy
- This Time
- Markov Chain -> Markov Reward Process(MRP) -> Markov Decision Processes(MDP)
- Policy evaluaion in MDP
- Control in MDP:policy iteration and value iteration
马尔科夫决策过程
在马尔科夫决策过程中,环境是全部能被观察到的。
马尔科夫决策过程与强化学习的关系?
强化学习中的agent和environment之间的交互,可以通过马尔科夫决策过程进行表示,所以马尔科夫决策过程是强化学习的基本框架。
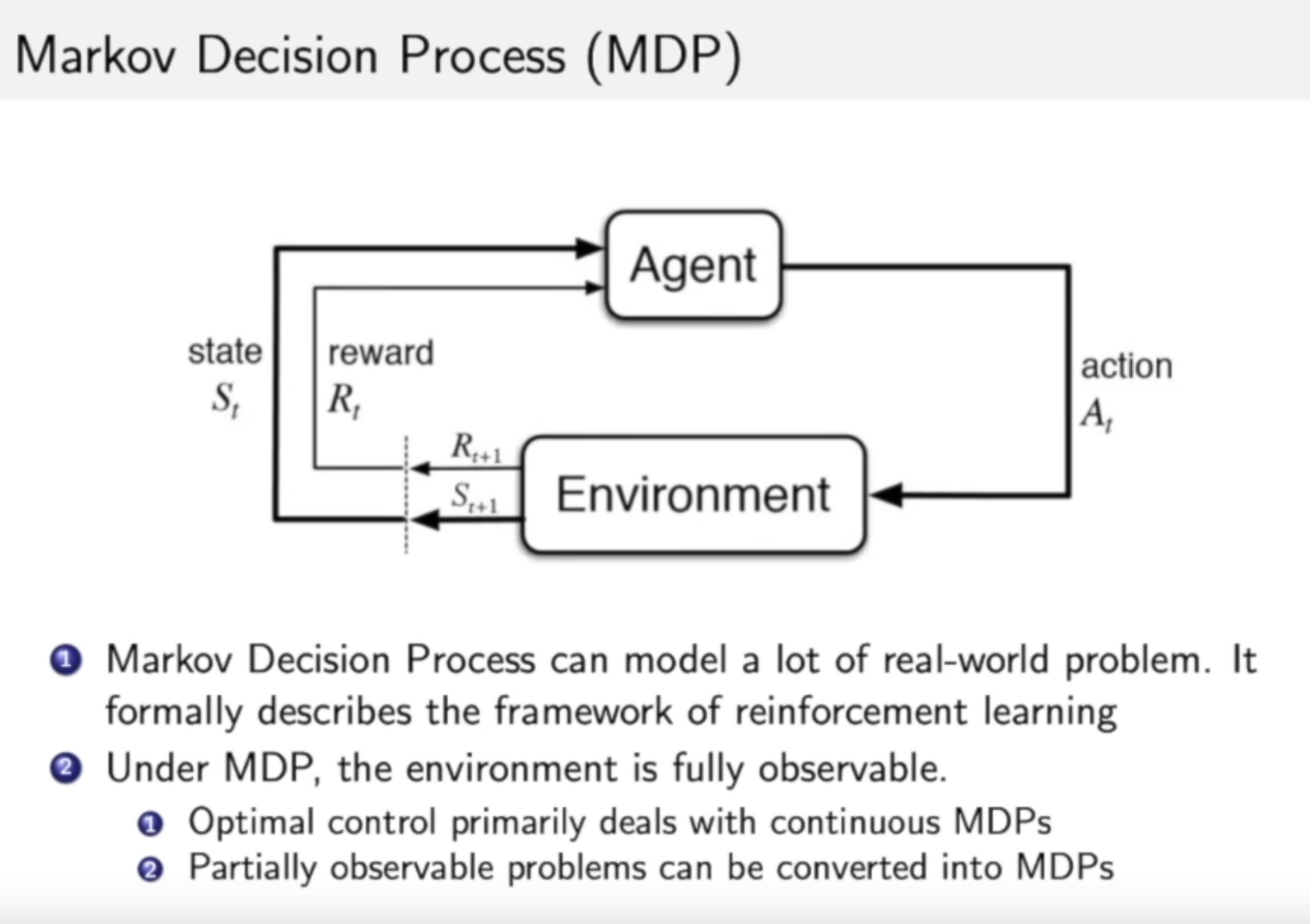
如何讲一个过程是符合马尔科夫特征的呢?
未来的状态只与当前状态有关,不与过去的状态相关。

马尔科夫过程 / 马尔科夫链
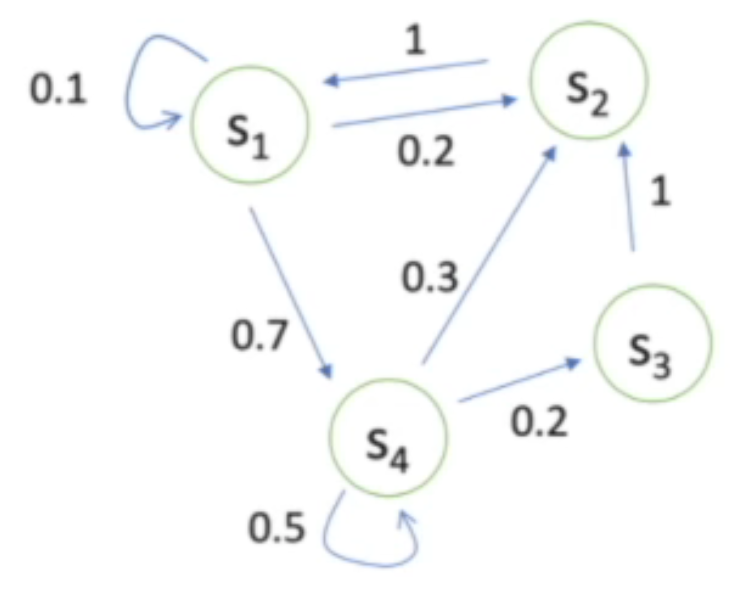
状态转移矩阵如下:
2.1 马尔科夫奖励过程
Return and Value function
-
Definition of Horizon
Horizon的目的是为了对马尔科夫决策过程指定一个观测的最大长度,而不是进行无限的观察
-
Number of maximum time steps in each episode
每个集合的最大步数?这是什么意思呢?
-
Can be infinite, otherwise called finite Markov (reward) Process
可以是无限的,否则可以称为有限的马尔科夫(奖励)过程
-
-
Definition of Return
将奖励进行折扣获得的收益
通过这个公式,可以当出现奖励时,对前面的状态进行奖励
- Discounted sum of rewards from time step t to horizon
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + . . . + + γ T − t − 1 R T G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \gamma^3 R_{t+4} + ... + + \gamma^{T-t-1} R_T Gt=Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+...++γT−t−1RT
- Discounted sum of rewards from time step t to horizon
-
Definition of state value function V t ( s ) V_t(s) Vt(s) for a MRP
-
Expected return from t t t in state s s s
期望表示的是,从当前的状态开始,未来能获得的最大的价值
可以把这个期望可以看成是进入某一个状态后,你当前具有多大的价值
V t ( s ) = E [ G t ∣ s t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + . . . + + γ T − t − 1 R T ∣ s t = s ] V_t(s) = E[G_t|s_t=s] = E[R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \gamma^3 R_{t+4} + ... + + \gamma^{T-t-1} R_T | s_t = s] Vt(s)=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+...++γT−t−1RT∣st=s]
-
Present value of future rewards
-
为什么需要 γ \gamma γ:
- 为了避免马尔科夫过程是带环的
- 为了将「对于未来的不确定性」表示出来,希望能够尽可能快地得到奖励
- 如果这个奖励是有实际价值的,我们希望能尽快得到这种奖励,而不是未来得到这种奖励
- 人类/动物的behaviour展示出了希望快速得到奖励的偏好
-
γ
\gamma
γ
- 设置为0:仅仅能获得当前状态的奖励
- 设置为1:将未来状态中获得的奖励与现有状态的奖励等效
案例:
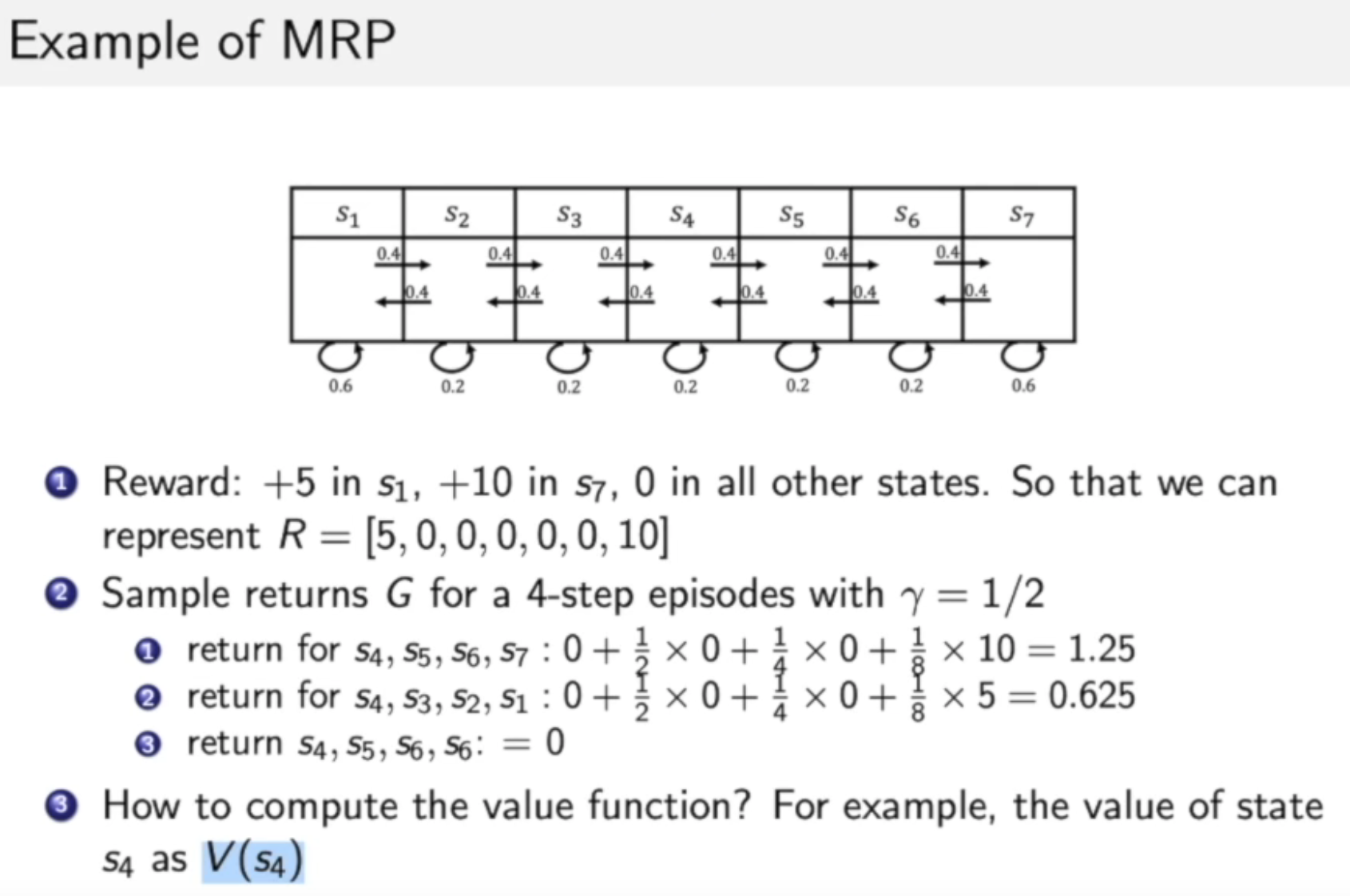

Bellman equation, 是一个重要的概念。
Bellman equation describes the iterative relations of states
Bellman等式描述了不同状态之间的迭代关系
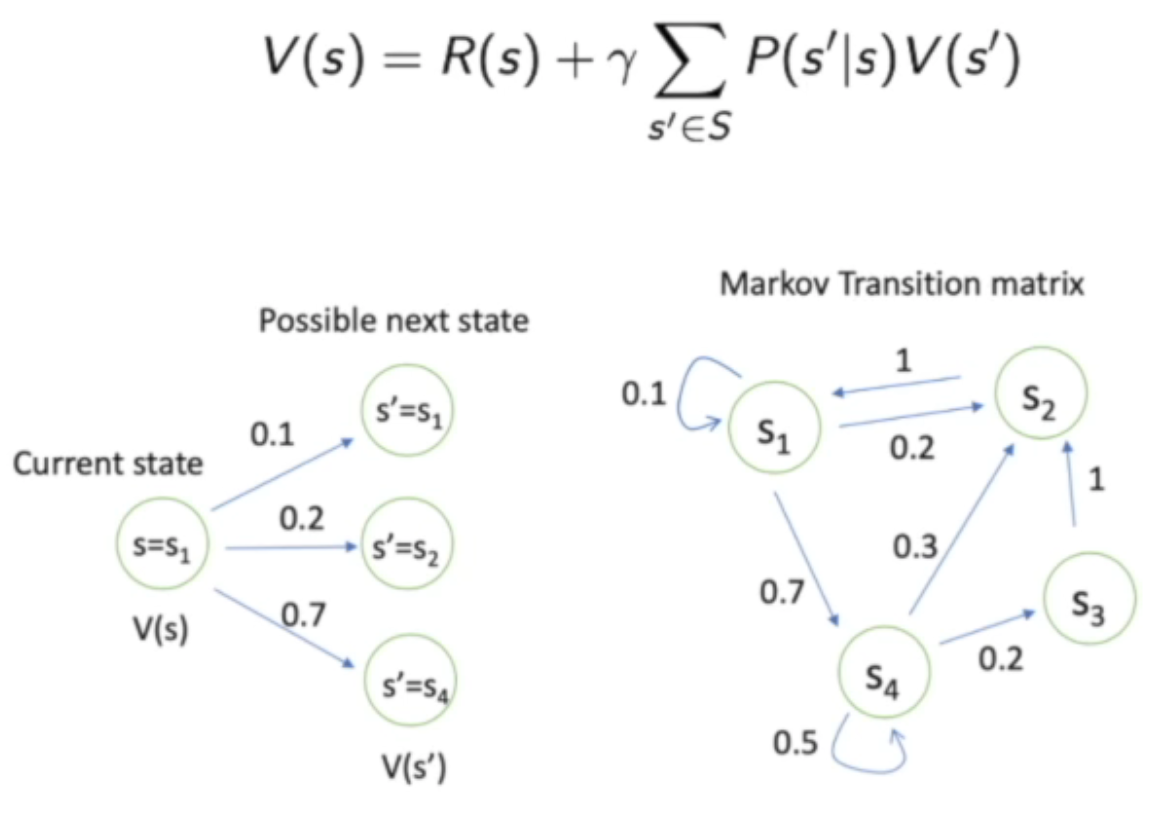
将Bellman equation可以写成下面这种矩阵的形式:

正如上式子所表达的:
- Bellman 等式可以写成上面的等式的形式
- 进一步的,当价值函数不变化时,即上式中左右两侧的V经过翻覆地迭代变成了一致时,我们就能够推出V的计算方程
- 这个计算的方程具有 O ( N 3 ) O(N^3) O(N3)的复杂度,N表示状态的数量
- 当N比较大的时候,上面的这个矩阵就变成了比如 一百万*一百万的矩阵,因为对大矩阵求逆是非常困难的,所以就不适合用这个式子来求解。
使用迭代的方法来计算MRP的价值
- Dynamic Programming(动态规划方法)
- Monte-Carlo evaluation(蒙特卡洛采样方法)
- Temporal-Difference learning(将上面的两种方法的一种结合)
Monte-Carlo采样的方法是说,给定一个采样总数N,从当前状态出发,去迭代并得到N次采样结果,利用这个N个结果来计算当前状态的价值。

动态规划(?还是说只是迭代)的方法来计算价值
具体上,不断地更新价值函数,当上一个价值与新价值的迭代幅度变的很小的时候,就可以得到一个近似的解了。

2.2 马尔科夫决策过程
相比于马尔科夫奖励过程,马尔科夫决策多了一个actions
- 状态转移也多了一个condition,a_t = a,
- 价值函数也是多了一个如上的condition

在MDP中的Policy定义的是,在当前状态s下,应当采取什么样的行为。
在MDP中,Policy是静态的(stationary,time-independent),表示策略的分布只与当前状态有关,不与时间有关。

当我们已知了一个马尔科夫决策过程和policy π之后,我们可以通过下面的方法将MDP转换成马尔科夫奖励过程:

上述式子一中,因为我们知道了在每个状态下采取某种行为的概率π,那我们就可以用π这个函数 marginize(边缘化)掉action,直接可以把这个a去掉。
同理,对于马尔科夫奖励函数,我们也可以利用函数π来marginize掉奖励函数中的状态函数。
可以通过下面这种图来对比一下MP/MRP and MDP:
可以看到,MDP中是多了一层actions
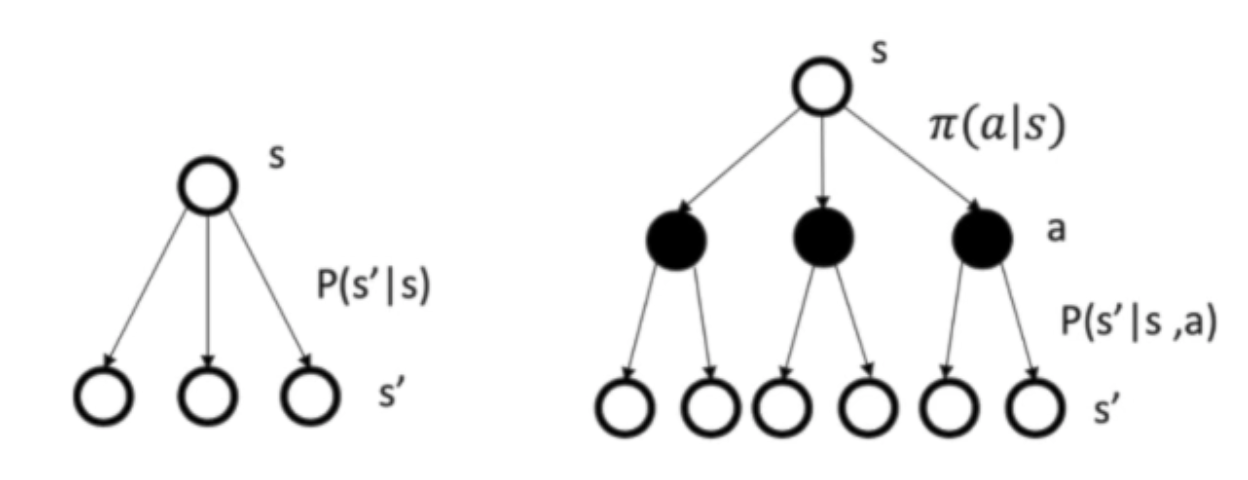
🙋 奖励函数和价值函数是两个函数吗?
- 奖励函数描述的是环境的固有状态
- 价值函数表示的是agent在某种状态、进行某种action时的价值期望

Bellman Expectation Equation
六式中表示 state-value function:
- 这里期望的是policy,marginize掉所有的action
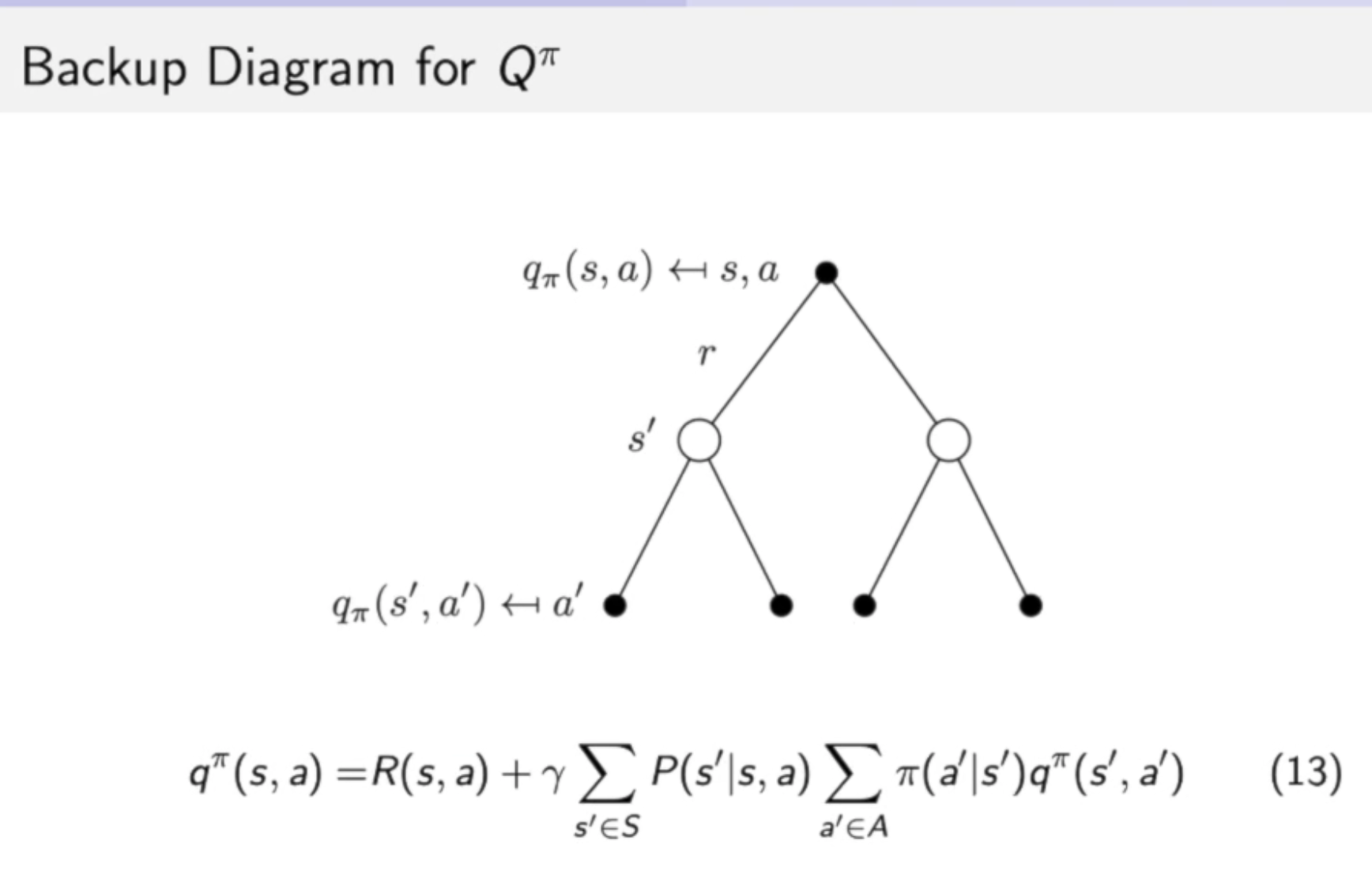
七式中表示 action-value function:
- 这里面包含了动作信息哟

等式八象征了价值函数和q函数之间的关联。
等式九:弹幕上说这是根据贝曼方程,从等式八中推理出来的。
等式十一:将等式八插入到等式九中,象征了当前时刻的q函数跟未来时刻的q函数之间的关联。
等式十:将等式九插入到等式八中,象征了当前时刻的价值函数跟未来时刻的价值函数之间的关联。
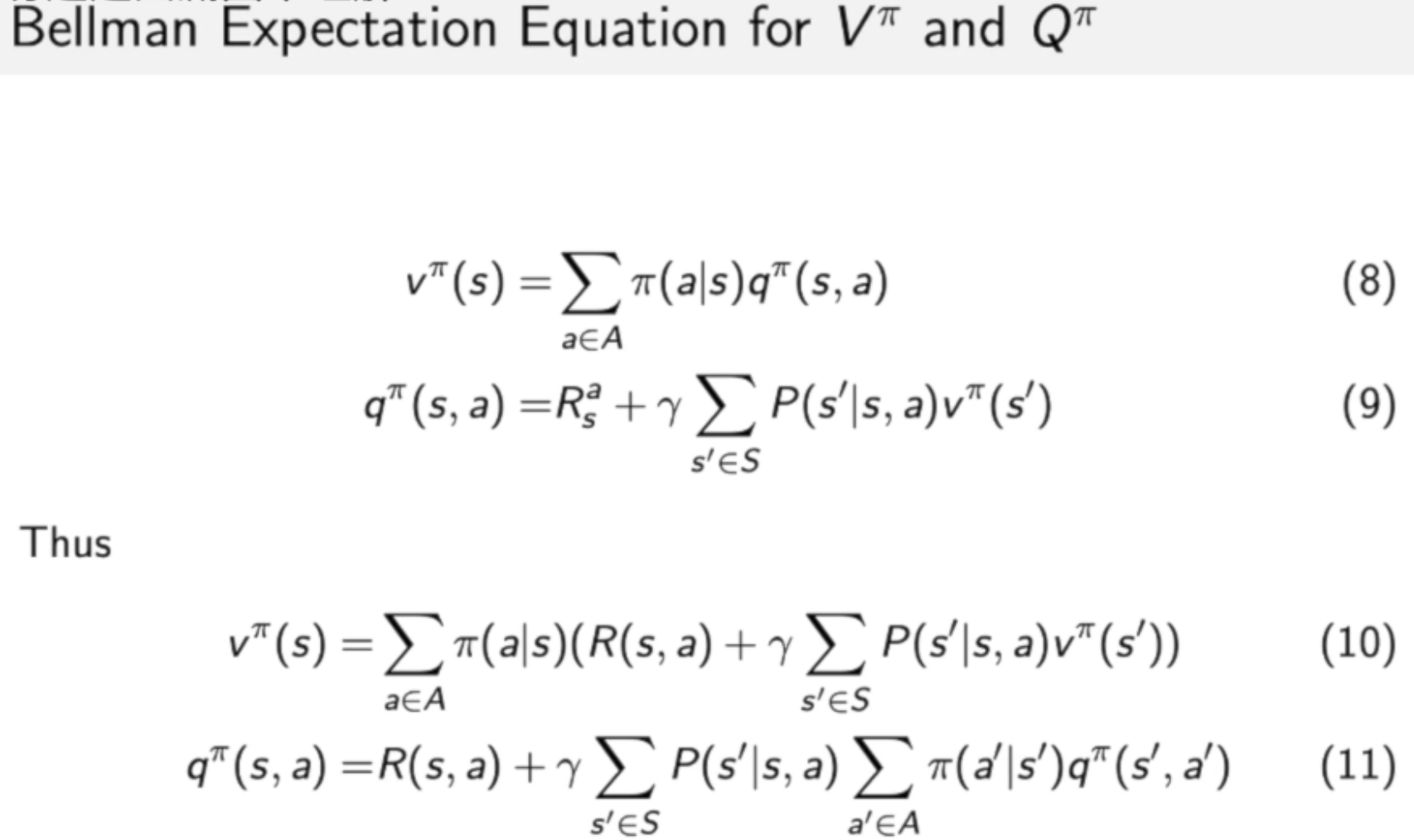
下面这个图例说明了两种状态之间的关系。
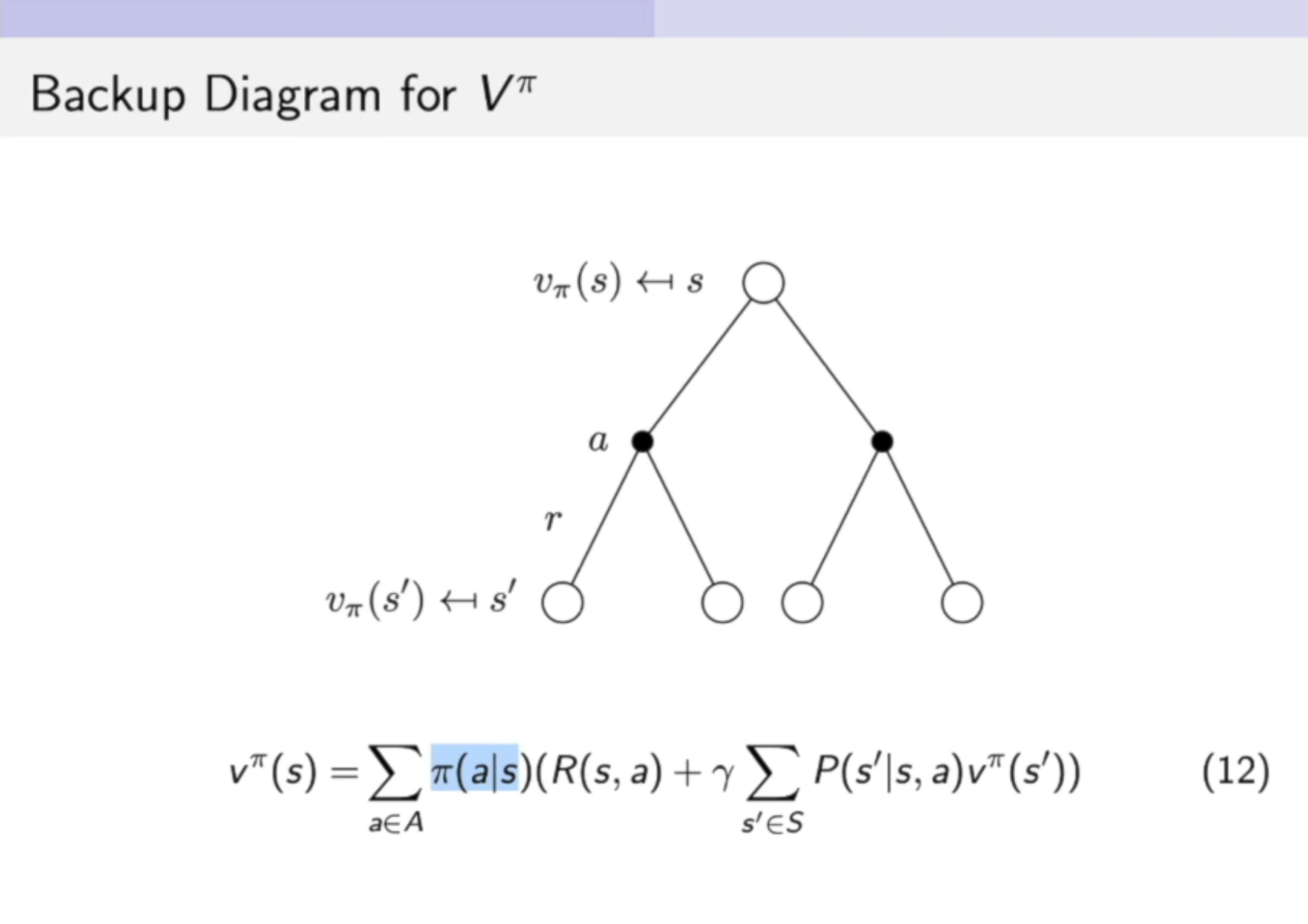
下面这个图例说明了两种行为之间的关系。
Policy Evaluation:
计算每一个状态的价值
-
Evaluate the value of state given a policy π:compute v π ( s ) v^π(s) vπ(s)
给定策略函数π,policy evaluation的目的是为了evaluate the value of state
-
Also called as (value) prediction
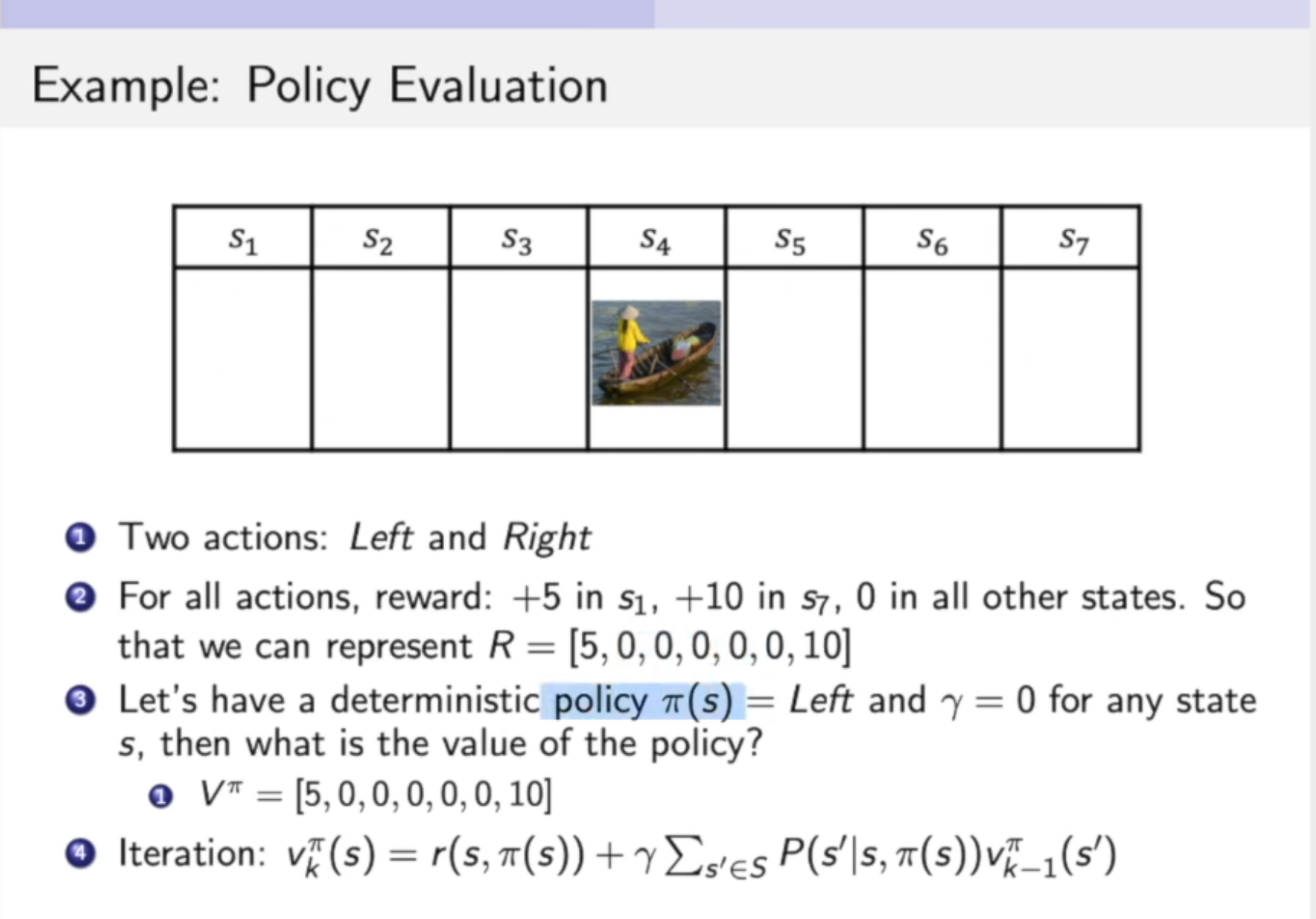
马尔科夫决策过程就相当与在原来随波逐流的船上,加了一个可以控制船移动方向的人。

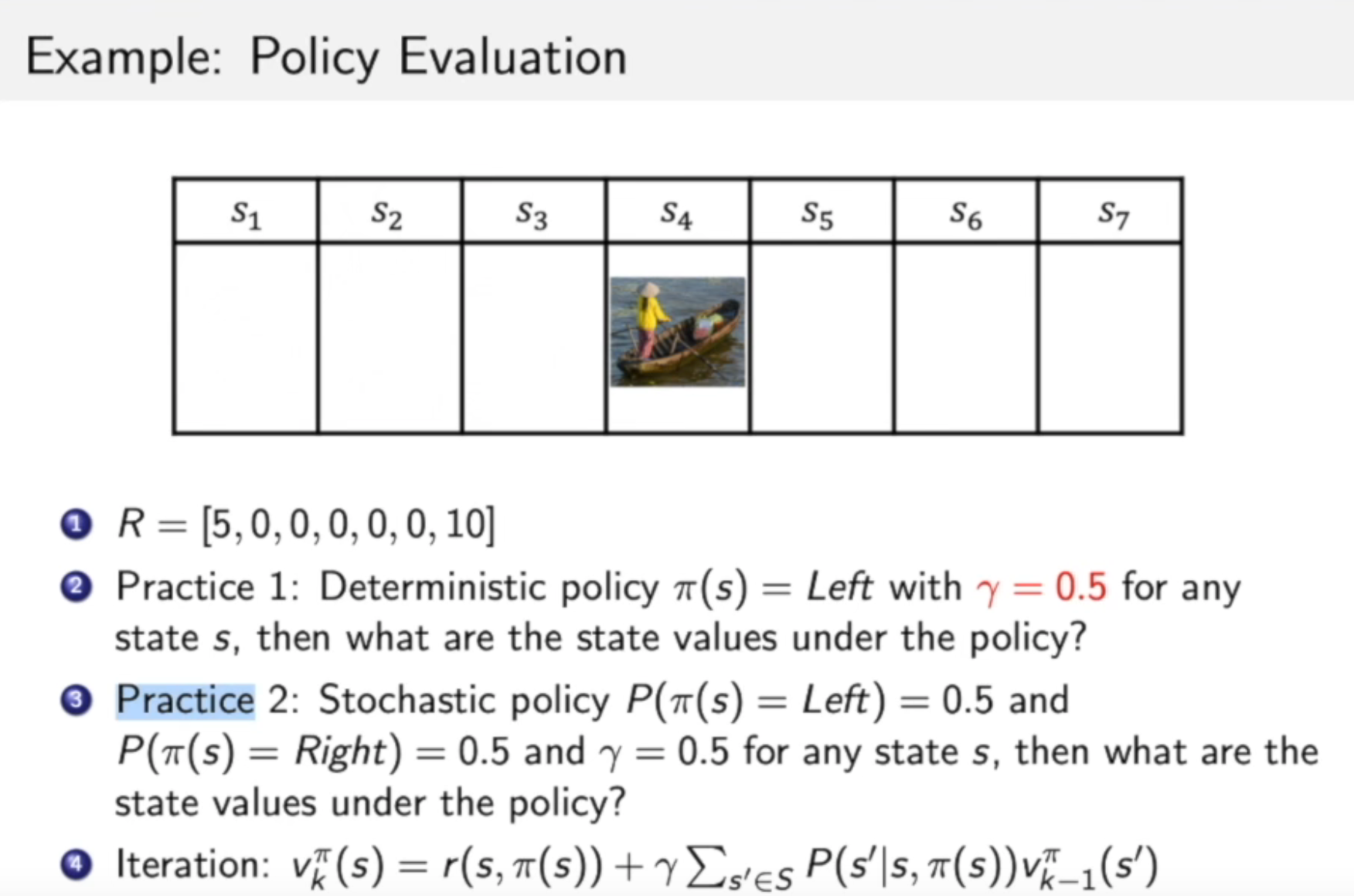
MDP中的决策
- prediction(给定policy,评估每个状态的价值)
- control 输入MDP,输出optimal value function v ∗ v^* v∗ 和 optimal policy π ∗ π^* π∗
- 上述两种需求可以通过动态规划(dynamic programming)的方法来解决
















 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









