









CNN主要的经典结构包括:LeNet、AlexNet、ZFNet、VGG、NIN、GoogleNet、ResNet、SENet等,其发展过程如下图所示。(下图来自刘昕博士《CNN的近期进展与实用技巧》)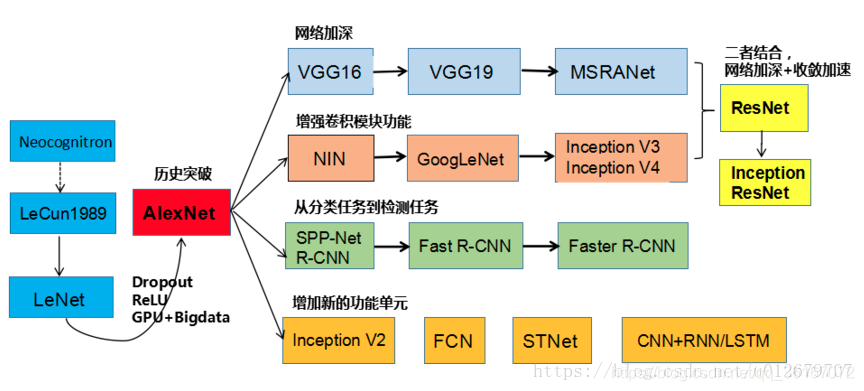
1、LeNet-5
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。1998年的LeNet5[4]标注着CNN的真正面世,但是这个模型在后来的一段时间并未能火起来,主要原因是费机器(计算跟不上),而且其他的算法(SVM)也能达到类似的效果甚至超过。但是LeNet最大的贡献是:定义了CNN的基本结构,是CNN的鼻祖。
LeNet-5的结构:
LeNet-5包含Input、卷积层1、池化层1、卷积层2、池化层2、全连接层、输出层共7层。
卷积层(Convolutional layer):卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
池化层(Pooling):它实际上一种形式的向下采样。有多种不同形式的非线性池化函数,而其中最大池化(Max pooling)和平均(Avg Pooling)采样是最为常见的。
pooling层的作用:Pooling层相当于把一张分辨率较高的图片转化为分辨率较低的图片;pooling层可进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
全连接层(Full connection):与普通神经网络一样的连接方式,一般都在最后几层。
INPUT: [28x28x1] weights: 0
CONV5-32: [28x28x32] weights: (5*5*1+1)*32
POOL2: [14x14x32] weights: 2*2*1
CONV5-64: [14x14x64] weights: (5*5*32+1)*64
POOL2: [7x7x64] weights: 2*2*1
FC: [1x1x1024] weights: (7*7*64+1)*1024
FC: [1x1x10] weights: (1*1*512+1)*10
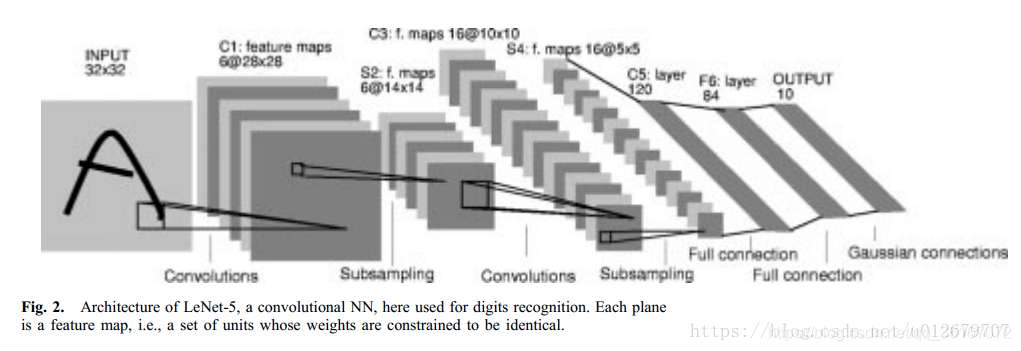
LeNet-5的特点::
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征(起初被称为感受野,未提“卷积”二字)
- 降采样(Subsample)的平均池化层(Average Pooling)
- 双曲正切(Tanh)的激活函数
- MLP作为最后的分类器
- 层与层之间的稀疏连接减少计算复杂性
LeNet-5的局限性:
CNN能够得出原始图像的有效表征,这使得CNN能够直接从原始像素中,经过极少的预处理,识别视觉上面的规律。然而,由于当时缺乏大规模训练数据,计算机的计算能力也跟不上,LeNet-5 对于复杂问题的处理结果并不理想。
LeNet-5的具体实现,可戳:https://blog.csdn.net/u012679707/article/details/80365599(感谢大大!!!)
2 AlexNet
Alex在2012年提出的alexnet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。2012年,Hinton的学生Alex Krizhevsky在寝室用GPU死磕了一个Deep Learning模型,一举摘下了视觉领域竞赛ILSVRC 桂冠,在百万量级的ImageNet数据集合上,效果大幅度超过传统的方法,从传统的70%多提升到80%多。这个Deep Learning模型就是后来大名鼎鼎的AlexNet模型。
AlexNet为何能耐如此之大?有三个很重要的原因:
- (1)大量数据,Deep Learning领域应该感谢李飞飞团队搞出来如此大的标注数据集合ImageNet;
- (2)GPU,这种高度并行的计算神器确实助了洪荒之力,没有神器在手,Alex估计不敢搞太复杂的模型;
- (3)算法的改进,包括网络变深、数据增强、ReLU、Dropout等
AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深度学习(深度卷积网络)在计算机视觉的统治地位,同时也推动了深度学习在语音识别、自然语言处理、强化学习等领域的拓展。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。网络架构如下图:
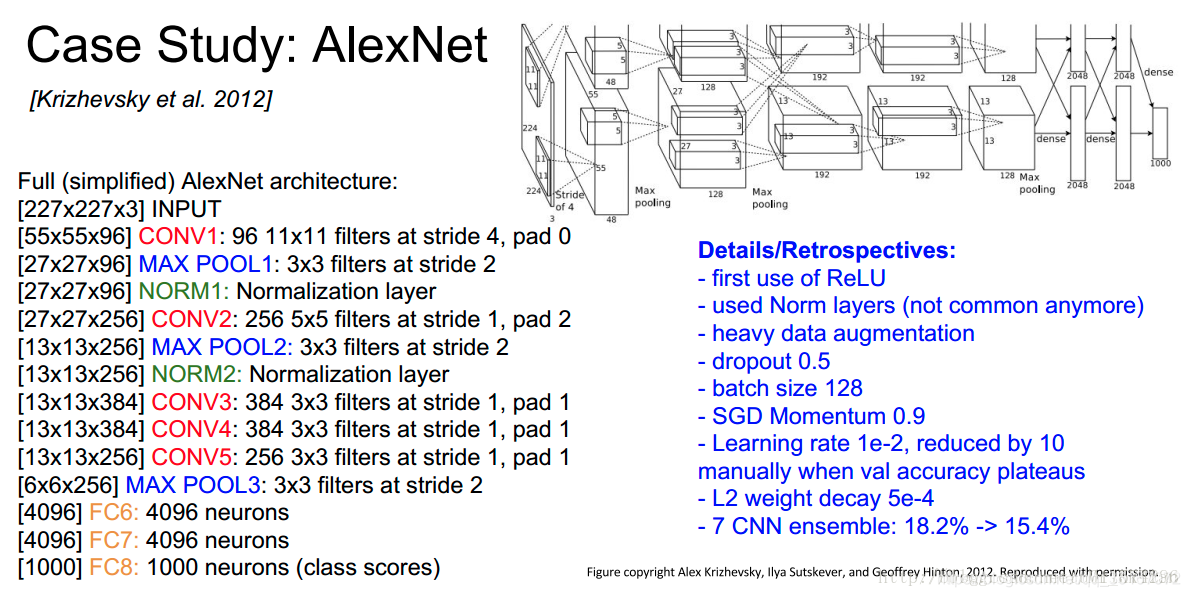
总体概述下:
- AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层,lexNet最后一层是有1000类输出的Softmax层用作分类;学习参数有6千万个,神经元有650,000个
- AlexNet在两个GPU上运行;
- AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接;
- LRN层第1,2个卷积层后;
- Max pooling层在LRN层以及第5个卷积层后。
- ReLU在每个卷积层以及全连接层后。
AlexNet的特点:
- (1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题,此外,加快了训练速度,因为训练网络使用梯度下降法,非饱和的非线性函数训练速度快于饱和的非线性函数。。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
- (2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
- (3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- (4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- (5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。AlexNet使用了两块GTX?580?GPU进行训练,单个GTX?580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。
- (6)数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)*(256-224)*2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。
AlexNet具体的tensorflow实现,可戳:https://blog.csdn.net/u012679707/article/details/80793916(感谢大大!!!)
3、VGG-Nets
VGG-Nets是由牛津大学VGG(Visual Geometry Group)提出,是2014年ImageNet竞赛定位任务的第一名和分类任务的第二名中的基础网络。VGG可以看成是加深版本的AlexNet. 都是conv layer + pooling layer+ FC layer,在当时看来这是一个非常深的网络了,因为层数高达十多层,我们从其论文名字就知道了(《Very Deep Convolutional Networks for Large-Scale Visual Recognition》),当然以现在来看来VGG真的称不上是一个very deep的网络。
VGG-Nets探索了CNN的深度及其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,VGGNet成功的构筑了16-19层深的CNN。VGGNet不好的一点是它耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。后来发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
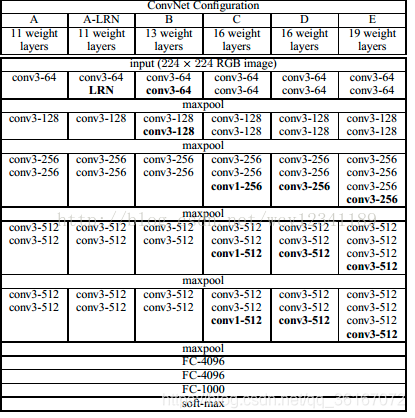
VGGNet结构:
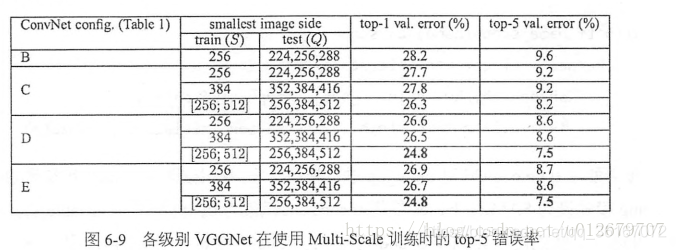
VGGNet有A-E七种结构,从A-E网络逐步变深,但是参数量并没有增长很多(图6-7),原因为:参数量主要消耗在最后3个全连接层,而前面的卷积层虽然层数多,但消耗的参数量不大。不过,卷积层的训练比较耗时,因为其计算量大。

其中,D和E是常说的VGGNet-16和VGGNet-19。C很有意思,相比于B多了几个1*1的卷积层,1*1卷积的意义在于线性变换,而输入的通道数和输出的通道数不同,没有发生降维(作用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。)(降维或升维)。
VGG的性能:
VGGNet网络特点:
- 结构简洁:VGG结构由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大池化)分开,所有隐层的激活单元都采用ReLU函数。
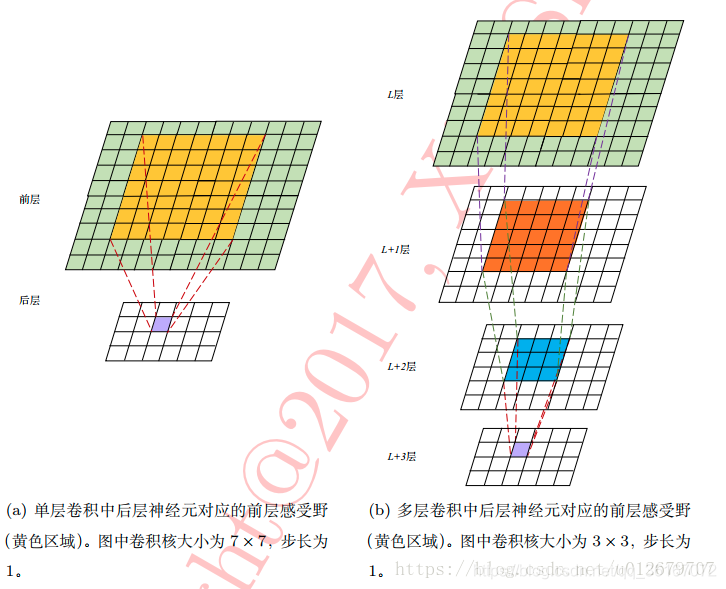
- 小卷积核和多卷积子层:VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射(3个RELU), 也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27)。
- 小池化核 :相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
- 通道数多:VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。每段内的卷积核数量一样,越后边的段内卷积核数量越多,依次为:64-128-256-512-512
- 层数更深、特征图更宽:由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
- 全连接转卷积(测试阶段):这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。如输入图像是224x224x3,若后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。而“全连接转卷积”,替换过程如下:
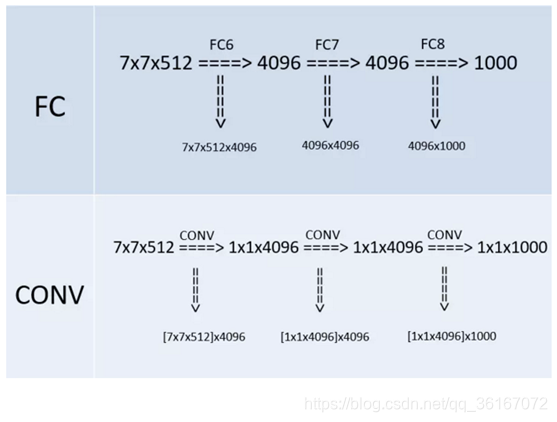
例如7x7x512的层要跟4096个神经元的层做全连接,则替换为对7x7x512的层作通道数为4096、卷积核为1x1的卷积
- 越深的网络效果越好。(图6-9)
- LRN层作用不大(作者结论)
VGGNet的贡献:
其突出贡献在于证明使用很小的卷积(3*3),增加网络深度可以有效提升模型的效果,而且VGG-Nets对其他数据集具有很好的泛化能力。到目前为止,VGG-Nets依然经常被用来提取图像特征。
VGG-Nets的tensorflow具体实现:https://blog.csdn.net/u012679707/article/details/80807406(感谢大大!!!)
4、GoogLeNet
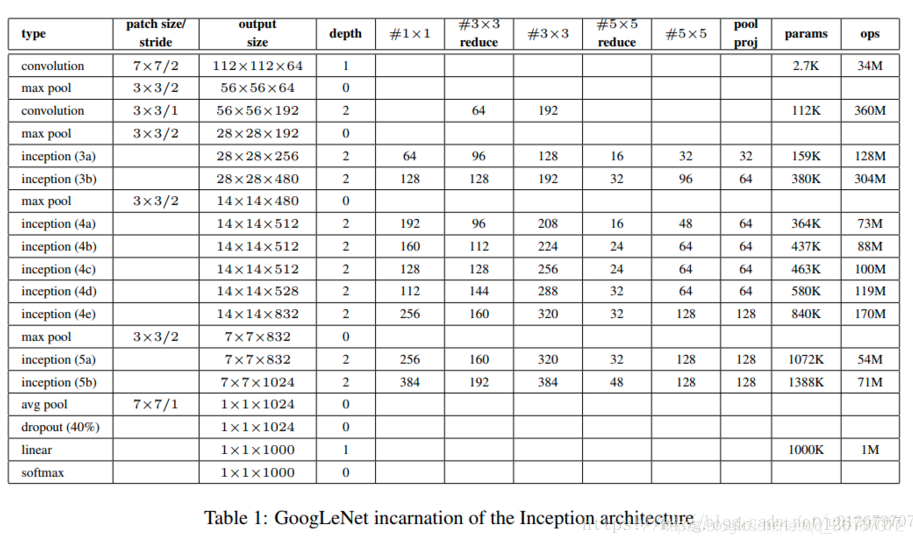
Google Inception Net首次出现在ILSVRC2014的比赛中(和VGGNet同年),以较大的优势获得冠军。那一届的GoogLeNet通常被称为Inception V1,Inception V1的特点是控制了计算量和参数量的同时,获得了非常好的性能-top5错误率6.67%, 这主要归功于GoogleNet中引入一个新的网络结构Inception模块,所以GoogleNet又被称为Inception V1(后面还有改进版V2、V3、V4)架构中有22层深,V1比VGGNet和AlexNet都深,但是它只有500万的参数量,计算量也只有15亿次浮点运算,在参数量和计算量下降的同时保证了准确率,可以说是非常优秀并且实用的模型。
googleNet系列介绍:Google Inception Net是一个大家族,包括:
- 2014年9月的《Going deeper with convolutions》提出的Inception V1.这是GoogLeNet的最早版本,出现在2014年的《Going deeper with convolutions》。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬
- 2015年2月的《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的Inception V2
- 2015年12月的《Rethinking the Inception Architecture for Computer Vision》提出的Inception V3
- 2016年2月的《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》提出的Inception V4
GoogLeNet被称为Inception-v1,加入batch normalization之后被称为Inception-v2,加入factorization的idea之后,改进为Inception-v3。
GoogLeNet结构:

对上图做如下说明:
- 显然GoogLeNet采用了模块化的结构,方便增添和修改;
- 网络最后采用了average pooling来代替全连接层,想法来自NIN,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家finetune;
- 虽然移除了全连接,但是网络中依然使用了Dropout ;
- 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
GoogleNet的特点:
- Inception V1中精心设计的Inception Module提高了参数的利用率;在先前的网络中,全连接层占据了网络的大部分参数,很容易产生过拟合现象;Inception V1去除了模型最后的全连接层,用全局平均池化层代替(将图片尺寸变为1x1)。
-
1x1卷积层:对特征降维,一方面可以解决计算瓶颈,同时限制网络的参数大小,可以将网络做的更「宽」和更「深」。
-
线性激活:整个GoogLeNet的卷积层和Inception单元内部,都是采用线性激活函数。
-
单元结构:
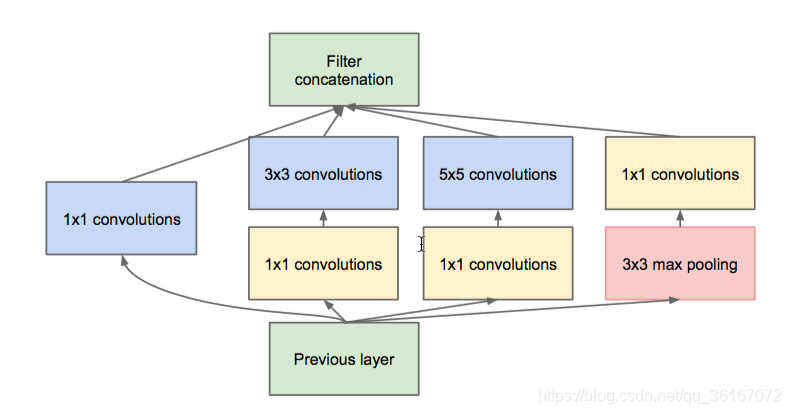
GoogLeNet Inception V1分享:
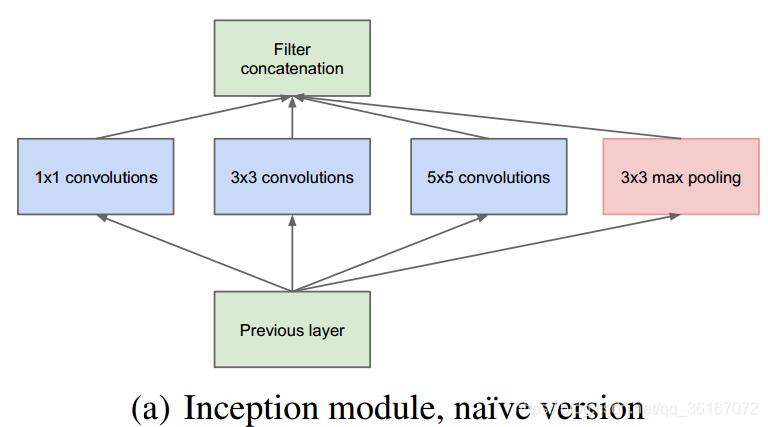
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。 作者首先提出下图这样的基本结构:
对上图做以下说明:
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
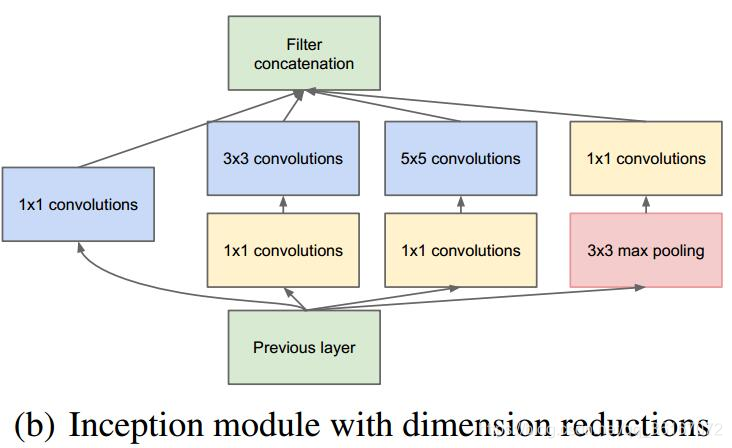
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:
闪光点:
- 引入Inception结构,这是一种网中网(Network In Network)的结构,即原来的结点也是一个网络。
- 中间层的辅助LOSS单元,GoogLeNet网络结构中有3个LOSS单元,这样的网络设计是为了帮助网络的收敛。在中间层加入辅助计算的LOSS单元,目的是计算损失时让低层的特征也有很好的区分能力,从而让网络更好地被训练。在论文中,这两个辅助LOSS单元的计算被乘以0.3,然后和最后的LOSS相加作为最终的损失函数来训练网络。
- 后面的全连接层全部替换为简单的全局平均pooling,将后面的全连接层全部替换为简单的全局平均pooling,在最后参数会变的更少。而在AlexNet中最后3层的全连接层参数差不多占总参数的90%,使用大网络在宽度和深度上允许GoogleNet移除全连接层,但并不会影响到结果的精度,在ImageNet中实现93.3%的精度,而且要比VGG还要快。
GoogLeNet Inception V2:
V2提出了BN,http://blog.csdn.net/app_12062011/article/details/57083447有介绍,另外, BN的反向传导:http://www.jianshu.com/p/4270f5acc066.softmax 梯度计算:http://blog.csdn.net/u014313009/article/details/51045303
GoogLeNet Inception V3:
GoogLeNet凭借其优秀的表现,得到了很多研究人员的学习和使用,因此Google团队又对其进行了进一步发掘改进,产生了升级版本的GoogLeNet。这一节介绍的版本记为V3,文章为:《Rethinking the Inception Architecture for Computer Vision》。
14年以来,构建更深的网络逐渐成为主流,但是模型的变大也使计算效率越来越低。这里,文章试图找到一种方法在扩大网络的同时又尽可能地发挥计算性能。GoogLeNet的表现很好,但是,如果想要通过简单地放大Inception结构来构建更大的网络,则会立即提高计算消耗。此外,在V1版本中,文章也没给出有关构建Inception结构注意事项的清晰描述。因此,在文章中作者首先给出了一些已经被证明有效的用于放大网络的通用准则和优化方法。这些准则和方法适用但不局限于Inception结构。
- General Design Principles
下面的准则来源于大量的实验,因此包含一定的推测,但实际证明基本都是有效的。
1 . 避免表达瓶颈,特别是在网络靠前的地方。 信息流前向传播过程中显然不能经过高度压缩的层,即表达瓶颈。从input到output,feature map的宽和高基本都会逐渐变小,但是不能一下子就变得很小。比如你上来就来个kernel = 7, stride = 5 ,这样显然不合适。另外输出的维度channel,一般来说会逐渐增多(每层的num_output),否则网络会很难训练。(特征维度并不代表信息的多少,只是作为一种估计的手段)这种情况一般发生在pooling层,字面意思是,pooling后特征图变小了,但有用信息不能丢,不能因为网络的漏斗形结构而产生表达瓶颈,解决办法是作者提出了一种特征图缩小方法,更复杂的池化。
2 . 高维特征更易处理。 高维特征更易区分,会加快训练。
3. 可以在低维嵌入上进行空间汇聚而无需担心丢失很多信息。 比如在进行3x3卷积之前,可以对输入先进行降维而不会产生严重的后果。假设信息可以被简单压缩,那么训练就会加快。
4 . 平衡网络的宽度与深度。
上述的这些并不能直接用来提高网络质量,而仅用来在大环境下作指导。
- Factorizing Convolutions with Large Filter Size
大尺寸的卷积核可以带来更大的感受野,但也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,(保持感受野范围的同时又减少了参数量)如下图(这个其实在VGG里面提出过了)
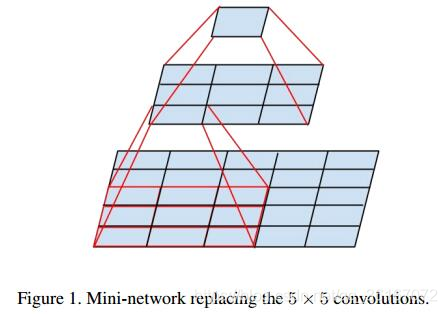
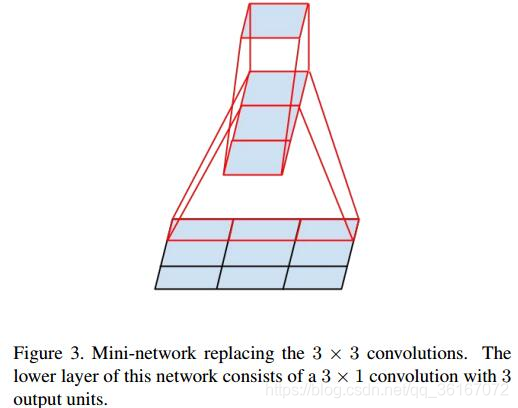
然后就会有2个疑问:
1 . 这种替代会造成表达能力的下降吗?
后面有大量实验可以表明不会造成表达缺失;
2 . 3x3卷积之后还要再加激活吗?
作者也做了对比试验,表明添加非线性激活会提高性能。
从上面来看,大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核。
如上右图所示的取代3x3卷积:
于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好。(对于mxm大小的feature map,建议m在12到20之间)。
总结如下图:
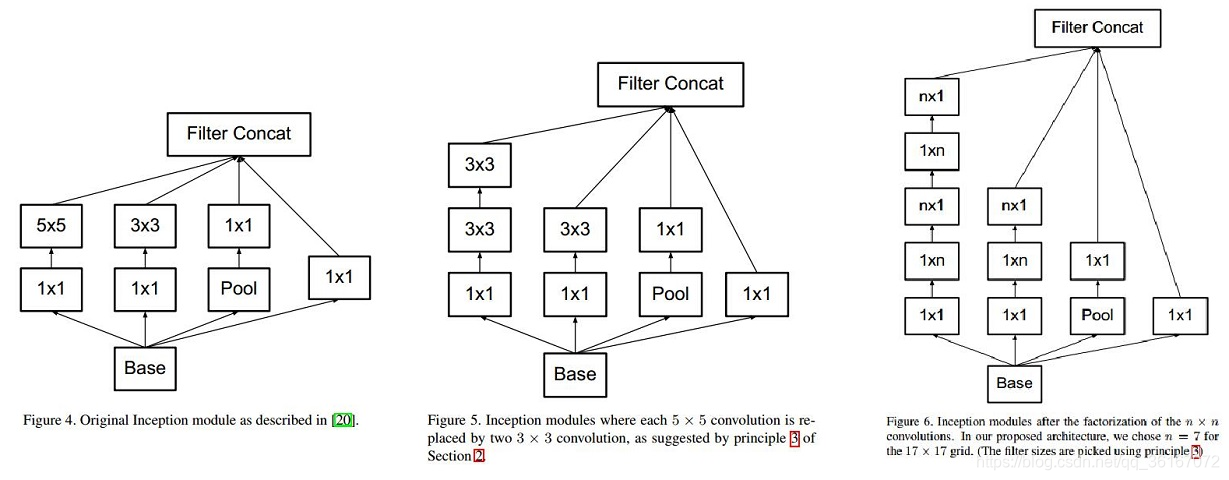
- 图4是GoogLeNet V1中使用的Inception结构;
- 图5是用3x3卷积序列来代替大卷积核;
- 图6是用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。即非对称个卷积核,其实类似于卷积运算中,二维分解为1维计算,提高了计算速度。
-
优化标签
深度学习用的labels一般都是one hot向量,用来指示classifier的唯一结果,这样的labels有点类似信号与系统里的脉冲函数,或者叫“Dirac delta”,即只在某一位置取1,其它位置都是0。Labels的脉冲性质会引发两个不良后果:一是over-fitting,另外一个是降低了网络的适应性。我对Label smooth理解是这样的,它把原来很突兀的one_hot_labels稍微的平滑了一点,枪打了出头鸟,削了立于鸡群那只鹤的脑袋,分了点身高给鸡们,避免了网络过度学习labels而产生的弊端。
googlenet具体tensorflow实现:https://blog.csdn.net/u012679707/article/details/80824889(感谢大大!!!)














 4587
4587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









