







出发点:当前的语义分割方法存在限制,多阶段的空间池化和卷积操作通常会使最终的图像预测的维度降低,丢失许多精细的图像结构。
- 通过反卷积滤波器进行上采样操作无法恢复卷积过程中下采样时丢失的信息
- 利用中间层的特征生成高分辨率预测缺少充分的空间信息
基础框架:ResNet
ResNet
理论上而言,具有更深层次的深度模型能够捕捉到更多特征信息,识别准确率至少不降低。实验中发现,在深度模型中添加更多的层可能会导致更高的训练误差。
神经网络中层的数量增加时会出现:

-
梯度消失
-
梯度爆炸
设想:在层数较少的原模型中增加恒等映射的多个层次,模型效果应与原模型相同,与实验经验相矛盾。
猜测:深度模型中,通过多个非线性层来渐进表示恒等映射可能存在难度。
注:x为模块输入,δ(F(x)+x)为模块输出,设F(x)为残差函数(即第二个激活函数前的结果与模块输入之间的差值)。

如果想要找到的最优函数更接近于恒定映射而不是零映射,那么学习残差函数应当比将映射过程作为一个新的函数来学习要容易。
模块的公式表示:
公式(1)为ResNet的核心思想,公式(2)是当模块中有两个层次时F的表示,公式(3)为模块的最终输出。其中,Wi为深度模型中需要学习的参数,δ为ReLU函数。
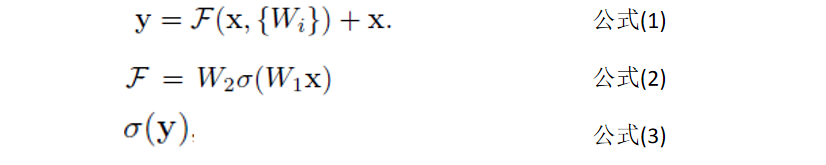

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









