










为什么写这篇文章
- 上篇文章是用 makefile 进行编译的。感觉 makefile 也算是个老东西了,这次准备用 CMake 工具。
- 上次的代码过于简单,也没有包含实际的头文件,库文件。
- 不久前在 Windows 下写了一个并发服务器,作为一个并发服务器怎么没有 Linux 版本呢
- 上篇文章对 gdb 的使用还不够
这个服务器的构成
- 这个服务器的网络模型是 IOCP/epoll,
- 有一个定时器
- 用到协程 boost::coroutine2
- 数据库使用 MySQL
MySQL安装
为了和 Windows 版本统一,我这里安装的是 8.1 版本
下载的文件
mysql-server:
mysql-community-server-8.1.0-1.el8.x86_64.rpm
mysql-community-client-8.1.0-1.el8.x86_64.rpm
mysql-community-icu-data-files-8.1.0-1.el8.x86_64.rpm
mysql-community-common-8.1.0-1.el8.x86_64.rpm
mysql-community-client-plugins-8.1.0-1.el8.x86_64.rpm
mysql-community-libs-8.1.0-1.el8.x86_64.rpm
注:server 下面的都是它依赖,得先安装它们,注意顺序
mysql-connect-C++:
mysql-connector-c++-8.1.0-1.el8.x86_64.rpm
配置
注:字符串用单引号 ' 包围起来
解决 mysql 密码认证失败:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '12345678';
MySQL设计
由于是多个 Game 同时连 DB,所以对 MySQL 部分表的操作需要同步。但同步工作MySQL替我完成了。因为 MySQL 对于插入带有自增字段的一行时,MySQL保证每次 insert 操作同步进行。包括这个服务器中创建用户,创建角色操作。
表
t_user: 用户
t_role: 游戏角色
t_rank: 游戏角色排行
t_system_mail: 系统邮件
t_role_system_mail
t_role_mail:
安装 boost 库
为了统一,我再次使用和 Windows 一样的 1.77 版本。另外boost是个很大的库,我这次只用到其中一小部分,所以我也只编译这一步库。它们是:context、coroutine、thread
./bootstrap.sh --show-libraries //查看 boost 包含的库内容
./bootstrap.sh --with-libraries=context,coroutine,thread //限定编译库
服务器架构
项目目录
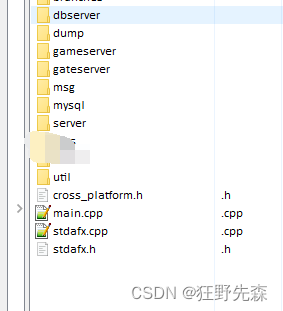
目录说明
msg: 消息定义,为适应 C#客户端,以及中文,使用 Unicode
mysql: 一些封装,对 MySQL api 的封装 可以参考我之前的文章
server: 基础的服务器类
util: 工具函数,包含定时器,调度器,字符串处理
gameserver:
gateserver:
dbserver:
其他文件
main 就是启动服务器的,没什么可说的
stdafx 预编译文文件
cross_platform 包含了一些特定系统的头文件,为了便于使用 Socket ,
抽象定 Socket 以及相关操作函数
Gate
连接所有 Game
用于平衡各个 Game 玩家人数的
一个 Gate Server 负责平均将客户端连接分配到不同 Game Server
n 个 Game Server,在硬件性能足够的情况下,每增加一个Game Server,同样的客户端连接数量下,相比单个Game Server,相应延迟可以预期降低为 1/n
找出最小负载 Game
方式1:
创建 N 个协程(N为 Game 个数),每个协程暂停1次,继续 1次
for (auto& [_, sock] : sd_Games)
{
shared_ptr<sReqMsg_Gate_To_Game_Get_Online_Count> msg =
make_shared<sReqMsg_Gate_To_Game_Get_Online_Count>();
shared_ptr<Co_Req> req = make_shared<Co_Req>(msg);
auto tmp_socket = sock;
req->SetFunc(
([=](shared_ptr<Co_Req> curr_req)
{
sendMsgToGame(msg, tmp_socket);
// myprintf("after send mst to game %d \n", tmp_socket);
curr_req->Pause();//
shared_ptr < sRespMsg_Game_To_Gate_Get_Online_Count > resp =
static_pointer_cast<sRespMsg_Game_To_Gate_Get_Online_Count>(req->get_resp_data());
if ((uint16_t)e_Req_Result::e_Req_Success != resp->rtCode)
{
myprintf("req failed! rtCode : %d \n", resp->rtCode);
return;
}
myprintf("Game: %d 人数: %d\n", resp->sid, resp->count);
}));
}分析:
假定 2 个 Game,那么这种方式就创建了 2 个协程函数,这样的写法代码较为清晰易读。但坏处在于不好汇总数据,
这两个协程是并行且乱序的,实际测试中,两个协程几乎同时从 curr_req->Pause(); 的下面一行继续执行,各自修改 std::map<uint16_t, uint64_t> gameCount 不同的 key 的值(map 已提前插入key,无须加锁)。尽管我选择最后1个协程修改完 map 时,尝试读取 map ,但读取到的map仍然是不完整的,另外一个协程有可能在读的时候,正在修改它的key。这样就读到老旧的数据。
为了拿到完整的 map ,我们需要等所有协程结束,问题是等多久?无论等多久,都不可避免会影响到其他消息的处理。这样的方式不是很好。
方式2
无论有多少个 Game 只创建 1 个协程
uint8_t GameServerCount = sd_Games.size();
shared_ptr<sReqMsg_Gate_To_Game_Get_Online_Count> msg =
make_shared<sReqMsg_Gate_To_Game_Get_Online_Count>();
shared_ptr<Co_Req> req = make_shared<Co_Req>(msg);
req->SetFunc(
([=]
(shared_ptr<Co_Req> curr_req)
{
std::map<uint16_t, uint64_t> gameCount; //sid 人数
for (auto& [srv_id, sock] : sd_Games)
{
auto tmp_socket = sock;
auto tmp_srv_id = srv_id;
sendMsgToGame(msg, tmp_socket);
curr_req->Pause();//
shared_ptr < sRespMsg_Game_To_Gate_Get_Online_Count > resp
=static_pointer_cast<sRespMsg_Game_To_Gate_Get_Online_Count>(curr_req->get_resp_data());
uint8_t g_sid = 0;
uint64_t g_count = 0;
if (resp)
{
g_sid = resp->sid;
g_count = resp->count;
myprintf("Game: %d 人数: %d\n", resp->sid, resp->count);
}
else
{
myprintf("req time out!\n");
break;
}
if (0 != g_sid)
gameCount[g_sid] = g_count;//汇总数据
}
}));分析
和上面最大的区别就是,所有请求都作为了 1 个协程,当 for 循环中的所有请求完成后,可以就在协程中一并将汇总的数据,很轻松就能找到最小负载的 Game。不过,这样的修改需要对原有的协程类能够暂停多次,相比第一种方式,每个Game的访问时按先后顺序的,这会明显增加客户端的登录所需要的时间,Game 越多,登录时间越长。
这里我请求了2次,暂停了2次,并且继续了2次
Game
当前有两个 Game ,都连接 DB
DB
一个 DB Server,由他直连 mysql 数据库,支持并发操作数据库
Center
允许不同 Game 的玩家聊天、交互,全服信息储存
HTTP
为服务器提供 网页访问支持,这个服务器不再使用 C++ 编写,使用 Go ,这部分内容就不在这篇文章展示了,会新开一篇文章
对于游戏里面的玩家发送的邮件,系统发送的邮件。如果不读入内存,那么从 MySQL 获取邮件的速度体验想必不会很好。若是直接读入 Game 那么无遗会增加 Game 的内存占用,同时玩家读取邮件还会降低 Game 对于玩家游玩游戏的响应能力。所以决定增设一个单独的服务器用来专门处理邮件!这个服务器也是连 DB 的。
邮件分为系统发给游戏角色邮件、角色发给角色的邮件,对于系统邮件只存储一份,不过需要额外一张表存储游戏角色对于系统邮件的读取、提取情况。当一封系统邮件因过期被删除时,游戏角色也不再记录对这封邮件的读取情况
其他服务器
如果跨服聊天是否还需要增加一个专门用于处理聊天的 Chat Server?
……
其他内容
CMakeLists.txt
cmake_minimum_required (VERSION 3.8)
project ("CppServers_cross")
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED On)
add_compile_options(-g)
add_compile_options(-O2)
#第三方库
include_directories(dep/include)
include_directories(dep/include/mysql)
link_directories(dep/libs)
#项目头文件
include_directories(util)
#……
#项目源文件
aux_source_directory(${CMAKE_CURRENT_SOURCE_DIR} othersrc)
aux_source_directory(util util) #util dir , util variable
aux_source_directory(msg msg)
aux_source_directory(server server)
#……
#项目源文件
set(SOURCE
${othersrc}
${util}
#……
)
add_executable (CppServers_cross ${SOURCE})# 将源代码添加到此项目的可执行文件。
find_package(Threads REQUIRED)#补上线程?
#项目静态库
target_link_libraries(CppServers_cross boost_context boost_coroutine boost_thread mysqlclient Threads::Threads)
#预编译头文件
set(HEADER_FILES
"stdafx.h")
target_precompile_headers(CppServers_cross PRIVATE ${HEADER_FILES})
关于 GDB 调试
gdb main core //
file main.cpp //切换文件
l 2 //跳转到当前代码上下文第 2 行
l EPOLL::init() //跳转到改符号处
b 2 //在 第二行 设置一个断点
run 2 //运行程序,遇到断点处会中断,可带参数
bt
print a //输出 a 的信息
n //执行下一句代码,会跳过函数
s //执行下一句代码,会进入函数
attach 1343306 //附加到进程
注意:attach 后程序会暂停 c/ cont 让程序持续运行
https://web.mit.edu/gnu/doc/html/gdb_9.html
Chapter 20. Debugging a Running Application Red Hat Enterprise Linux 7 | Red Hat Customer Portal
Shell脚本
大部分的命令都是通过 send_cmd 程序,走共享内存到达,目标服务器程序的
Windows 和 Centos 的不同
字符编码
Windows下是 gb2312,Centos下是UTF-8,为了让两边都能正常输出中文,统一选择UTF-8,另外单字符转多字符只在Windows上进行
处理用户输入
有窗口的Windows,这个不是问题。可在Centos下往往进程都是在后台运行,另外使用信号并不能满足各种指令的需求,选择使用共享内存让Centos下的服务器仍然具备处理复杂指令的能力。
IPC-共享内存
原本是想用 信号的,奈何信号功能简单,选择信号的话。Linux 版本就不能处理复杂指令了,怎么能行呢。
EPOLL_Server 相比 IOCP_Server 在初始化时,需要额外创建一块共享内存区域,从中读取外部程序传进来的指令。共享内存使用头一个字节表示这块内存的状态。
0:空内存,初始状态;1:写入中;2:写入完毕:3:已读取,已废弃;
为了避免阻塞影响到主线程,自然是在某个子线程进行的。
服务器这边阻塞直到状态变为2,从中拷贝指令后,将状态修改为3
外部程序阻塞直到状态变为3,往里写后,将状态修改为2
共享内存由服务器程序创建,在服务器退出时销毁。
多线程切换调度
有这样的一个流程:Game 向 DB 发起一个 mysql 查询请求。Game 将这个任务以协程函数的方式扔给一个子线程,子线程往 DB 发送消息后,暂定该协程函数。收到 DB 回复后,子线程继续执行该协程函数处理消息。
windows10
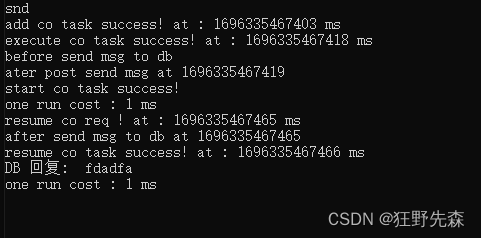
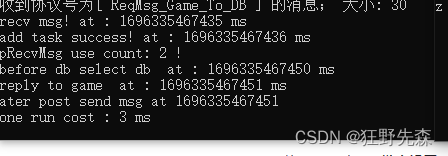
由于服务器 16ms 处理一次收到的消息,其中流程共计有 2 次收消息所以大约 32ms 是少不了的花费。不过它上边共计 花费 48ms,从添加子线程任务到执行,居然花费 15ms,多出来的大部分时间就花在这里,这次还是比较幸运的,DB 从添加查询任务到子线程执行并没有花费太多时间。
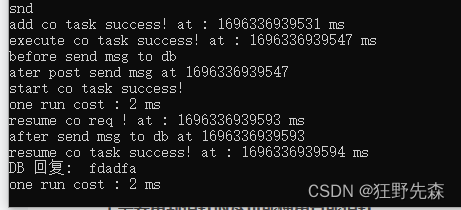

这一次共计花费了 63 ms,原因是,DB 收到Game 请求时,DB 从添加查询任务到子线程执行也花了近 16ms 。
Centos8
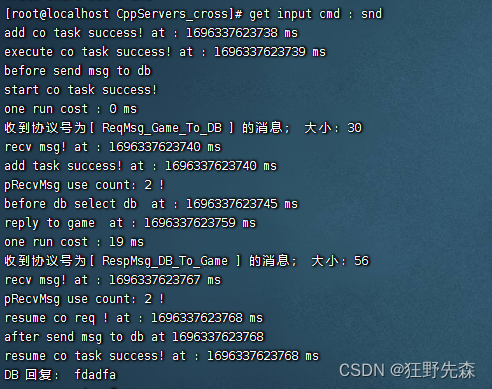
这边花费的时间就十分符合预期了,共计花费 30ms,从添加任务到子线程执行不怎么花时间。
这是否能说明,在线程调度方面 Linux 比 Windows 优秀不少呢
预防内存泄漏
1.需要用到指针时尽可能使用智能指针
shared_ptr<Server_C> theServer; //服务器实例
shared_ptr<sMsg> pRecvMsg; //消息包
注意:shared_ptr 在作为一般函数参数传递时,use_count 会进入函数以及离开函数时正常增减。在 boost::coroutine lambda 函数中,值捕获 shared_ptr<>时,若频繁重入协程函数会导致引用计数增加,从而导致引用计数异常,无法正常释放。另外,把智能指针放进容器中也是会增加1次 use_count 的。
传递引用,方便知道引用增减情况
2.使用 string 替代 char*
每一次 new char[] 都需要手动释放,这怎么能行。
char m_char[len] ={0};
string str(m_char);3.还有众所周知的 虚析构 函数了
相关测试
iocp服务器:13个消息线程,1个监听线程
epoll服务器:1个线程处理监听+消息
注:当前的所有测试当中,客户端以及服务器都没有锁定帧数
短时间大量连接测试
20000连接
IOCP 用时 2283ms
epoll用时 1825ms
处理短时间的大量连接请求,这两个差距并不是很大。
单次请求响应时间测试
将每个线程视为一个客户端,每个客户端发送一条消息到接收到消息并处理完毕视为一次响应

随着线程的增多,IOCP的平均单次请求响应时间明显增加了,性能下滑很严重啊。
测试的时候,我注意到epoll write 发送十分干脆一次就发送完了。反观 IOCP 在提交发送请求时,很多时候虽然提交了,但一个字节也没发出去,之后才发送完成。IOCP的发送(写)操作完成时是会充当一个完成事件挤占了其他读完成事件处理,并且每次事件完成后相比 epoll 额外需要提交一个关注操作(要么读,要么写),还有由于IOCP是多个线程处理读写,用锁同步它们操作消息队列也是一笔开销。
如果不使用锁,能提高服务器的响应速度吗
我将消息接受队列换为 boost::lockfree::queue 后,不再使用互斥量同步线程操作,结果有点意外。同样的请求测试下,IOCP 变化不大,不好不坏。epoll的响应速度就明显变慢了。

使用 boost::lockfree::queue 替换 std::queue 并没有有效降低服务器的响应延迟呢
响应速度的瓶颈
其实这个服务器的响应瓶颈不在消息的接收端,接受是并发的。可是处理消息是在单线程,而且是有时间先后要求的,瓶颈就在于此,这也难怪换无锁队列没有提升。问题是我这个服务器是奔着游戏服务器方向去的,如果开多个逻辑线程来处理消息,这个代码会有多么复杂我都不敢想,并发处理消息,暂时我是不考虑咯。
当然在软件层面也不是完全没有办法了,可以创建多个服务器,把这些客户端平均的分配在各个服务器上,通过减少单个服务器单位时间内需要处理的消息来提高响应速度。
另外,当前的服务器是在主线程中使用协程发起远程请求的,这不会让主线程阻塞。但是在面对大量消息时,需要主线程在各个协程之间来回切换,由于服务器之间的请求多数是无关业务的,可以考虑将协程放到多线程里。如果有 N 个线程以启动协程的方式处理远程请求,那么理想情况下,忽略各个线程之间的同步的话,处理这些请求所需要的时间可以接近 1/N.
优化:使用多个 Game
这里测试 2 个 Game 的效果,图中时间为平均单次响应时间,100,500,1000分别是并发客户端数量,每个客户端共计请求 500 次。
| 100 | 500 | 1000 | |
| 1个Game-Win10 | 227ms | 1174ms | 2346ms |
| 1个Game-Centos8 | 27ms | 184ms | 330ms |
| 2个Game-Win10 | 109ms | 585ms | 1159ms |
| 2个Game-Centos8 | 10ms | 102ms | 243ms |
可以看待在 Windows 下,增加 1 个 Game,平均单次响应所需要的时间比之前的 1/2 还要好一些,我想之所以会是这样的数据。不仅仅是因为每个 Game 处理的消息数量降为 1/2 并且数据量减少也减小的各个线程之间数据竞争的强度。
至于 在 Centos 下,看上去平均单次响所需要的时间,只有在 100 客户端时响应时间降低为预期的 1/2 ,在更多的客户端以及数据量时节约的时间并不太客观。由于 Game 会输出不少信息到终端,那么在并发测试时,就有 2 个Game竞相向终端输出信息,数据量大所节约的时间不符合预期,是否和这个有关呢?
优化:以多线程启动协程
可以改善各个服务器之间通信速度,这部分优化无法降低 Game 本身的延迟。
实际负载能力
如果服务器锁定 60 帧,客户端锁定 60 帧,并且要求平均单次响应延迟在 50ms 以内,好奇这个服务器能承载多少个客户端并发请求呢。
测试配置
Gate: 1 个
Game: 4 个
客户端:本地运行
服务器:本地运行
CPU:7700k
内存:8g
本地测试结果
能容纳的并发客户端数量:1514 个
由于,服务器是运行在 Linux 虚拟机下,再加上客户端也是和服务器使用同样的物理资源。如果客户端和服务器分别是不同的计算机,服务器能容纳的客户端数量按理来说会比这个数据高吧!
部分代码
Server 类
class Server_C : public RealServer ,
public std::enable_shared_from_this <Server_C>
{
public:
virtual bool handleCommand();
virtual void HandleDisconnect(Socket fd) {};
void handleRecvMsg();
virtual void handleRecvMsg(shared_ptr<sMsg> pRecvMsg) {};
virtual void ConnectToServers() {};
virtual bool connectToMySql() { return true; };
public:
Server_C() = delete;
Server_C(eSrvType type, uint8_t id);
bool init();
void run();
bool endServer();
void sendMsgToClient(shared_ptr<sMsg> pMsg, Socket socket); //发送消息
void sendMsgToDB(shared_ptr<sMsg> pMsg);
void sendMsgToGame(shared_ptr<sMsg> pMsg, Socket socket);
void replyTo(shared_ptr<sMsg> pMsg, Socket socket);
};在 Windows 下 RealServer是 class IOCP_Server,在CentOS 下是 EPOLL_Server
定时器类
class Timer
{
private:
priority_queue < shared_ptr<Task>> pq_tasks; //用于执行
set<uint64_t> sTask; //用于删除
//初始为 0
thread worker[MAX_TIMER_WORKER_THREAD];
std::mutex task_mutex;
void addTask(shared_ptr<Task> t);
uint64_t taskid;
bool isClose;
public:
Timer();
virtual ~Timer();
uint64_t addTask(uint64_t interval, std::function<void()> proc,
bool isInfinite = false);
void removeTask(uint64_t tid);
void doTask();
void init(int threadCount);
void close();
};任务都放在最小堆结构里,为了保证有效让定时器任务失效,额外用了一个set。删除某个任务时在 set 打上标记,当时间轮到它时,我们有标记信息,不执行它的任务函数,简单pop就行,当然set是需要删除的。
另外,为了准时。使用了多个线程从任务队列中取任务,遇到循环任务,先加入一个任务再取执行。
协程请求类-boost::coroutine2
class Co_Req : public std::enable_shared_from_this<Co_Req>
{
private:
inline static uint64_t start_req_id = 0;
inline static std::map<uint64_t, shared_ptr<Co_Req>> co_reqs;
inline static std::mutex mutex_co_reqs;
shared_ptr<asymmetric_coroutine<void>::push_type> req;
asymmetric_coroutine<void>::pull_type* sink;//用于暂停异步请求,指向栈上对象,请勿释放
bool isEnd;
shared_ptr<Msg::sSrvRespMsg> pRespData;
uint64_t id; //req id 用于暂停/继续 关联协程
uint64_t timer_id; //超时处理定时器 id
std::function<void(shared_ptr<Co_Req>) > func;
public:
static void SaveReq(shared_ptr<Co_Req> req); //from main thread
static shared_ptr<Co_Req> GetReq(uint64_t id);
static void RemoveReq(uint64_t id)
void SetFunc(std::function<void(shared_ptr<Co_Req>) > func);
Co_Req(shared_ptr<Msg::sSrvReqMsg> msg);
void StartCoroutine(asymmetric_coroutine<void>::pull_type& tmpsink);
void Start();
void Resume(shared_ptr<Msg::sSrvRespMsg> p);
inline void Pause() { sink->operator()(); }
//void Pause();
};在向其他服务器发消息时,通过协程可以以同步方式写异步代码,摆脱回调。写大量的回调让代码支离破碎,散落各处,我很不喜欢。这也是写这个服务器的重要原因。
为了简明性,增加了一个 Pause() 专门暂停协程函数
asymmetric_coroutine<void>::pull_type& tmpsink 这个 tmpsink 原本是打算 shared_ptr 进行管理的,结果发现是一个栈上对象。
为了能在 Pause 拿到 tmpsink,这里选择使用一个普通指针,指向它,不能进行释放。
不过话说回来,这 tmpsink 是栈上对象也合理,毕竟一个 tmpsink 总归是要在协程函数内部暂停的。
协程开始
void Util::Co_Req::Start()
{
req = make_shared<asymmetric_coroutine<void>::push_type>
(boost::bind(&Co_Req::StartCoroutine, this, boost::placeholders::_1));
(*req)();
//设置超时处理
auto sptr = shared_from_this();
sptr->timer_id = g_timer->addTask(5000, [=]()
{
/*shared_ptr<sSrvRespMsg> resp = make_shared<sSrvRespMsg>();
resp->req_id = sptr->get_id();
resp->rtCode = (uint16_t)e_Req_Result::e_Req_Time_out;*/
sptr->Resume(nullptr);
});
}协程暂停
inline void Pause() { sink->operator()(); }协程继续
void Util::Co_Req::Resume(shared_ptr<Msg::sSrvRespMsg> p)
{
pRespData = p;
(*req)();
}协程删除
void StartCoroutine(asymmetric_coroutine<void>::pull_type& tmpsink)
{
sink = &tmpsink;
func(shared_from_this());
RemoveReq(id); //从协程合集移除
g_timer->removeTask(timer_id); //移除超时处理
}以同步方式写异步请求代码
发出异步请求
shared_ptr<sReqMsg_Game_To_DB_Get_Name> msg =
make_shared<sReqMsg_Game_To_DB_Get_Name>();
msg->_sub_type = (uint16_t)e_Game_MsgSubtype::e_Req_To_DB_Get_Name;
shared_ptr<Co_Req> req = make_shared<Co_Req>();
msg->req_id = req->get_id();
msg->user_id = 1;
req->SetFunc(
([=]( shared_ptr<Co_Req>req)
{
//往db 发消息
sendMsgToDB(msg);
req->Pause();//发送消息后,立即 暂停
//协程继续
shared_ptr<sRespMsg_DB_To_Game_Get_Name> resp =
static_pointer_cast<sRespMsg_DB_To_Game_Get_Name>(req->get_resp_data());
if ((uint16_t)e_Req_Result::e_Req_Success != resp->rtCode)
{
myprintf("req failed! rtCode : %d \n", resp->rtCode);
return;
}
myprintf("DB 回复: %s\n", resp->name);
//收到消息或者超时,coroutine 继续
}));在这个 lambda 内 shared_from_this() 拿到的并不是 Co_Req,只能传递一个 Co_Req 指针进来,属于是不够简洁咯。
收到回复时协程继续
case e_MsgType::e_RespMsg_DB_To_Game:
case e_MsgType::e_RespMsg_Game_To_Gate:
//其他回复消息可以加在下面
{
shared_ptr<sSrvRespMsg> sCM =
static_pointer_cast<sSrvRespMsg>(pRecvMsg);
auto Req = Co_Req::GetReq(sCM->req_id);
if(Req)
Req->Resume(sCM);
else
myprintf("Req [%d] has been remove\n", sCM->req_id);
}这部分代码是少不了的,毕竟是发往其他服务器的请求消息。需要在接受到回复,从上次协程函数暂停的地方继续执行。














 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









