







我一直认为用C语言来描述数据结构(尤其是这种简单的)是一个非常不错的方式。
C语言在表示数据,存取数据,表现数据结构里都没有那么多“捷径”可以走,所以用C语言写基础的数据结构的代码,是非常方便读者理解的。
毕竟,C语言极有可能成为一个程序员的入门语言。
题目描述

小哼和小哈一同坐飞机去旅游,他们现在位于1号城市,目标是5号城市,可是1号城市并没有到5号城市的直航。不过小哼已经收集了很多航班的信息,现在小哼希望找到一种乘坐方式,使得转机的次数最少,如何解决呢?

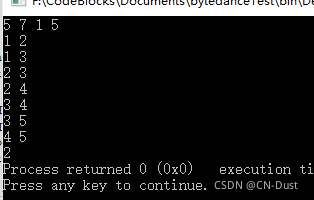
输入:
5 7 1 5
1 2
1 3
2 3
2 4
3 4
3 5
4 5
输出
2
题解
这是一个典型的广度优先查找,查找从A点到B点的最少转机次数。
一开始不喜欢DFS,喜欢BFS,觉得递归实在是太复杂了。做完这题发现,BFS要理解好那个存储状态的队列也不容易。比如下面代码的que里面的s,在数组里每个s会是什么样子的呢?s什么时候+1呢?+1的时候是基于什么的呢?这里逻辑就有点绕了。
不过机智的我还是弄明白了,对于每次s要+1的时候,取决于现在的头指针指向的哪个点(即本次转机的出发机场是哪里)。
最后,输出尾指针-1(因为尾指针每次都要++以指向下一个空格子)里的s属性的值就可以。
具体可以看代码。
#include<stdio.h>
int a[2000][2000], book[2000];
struct note
{
int x;//城市编号
int s;//转机次数
};
struct note que[2000];
int main()
{
int i, j, n, m, x, y, start, end;
int cur, head, tail;
scanf("%d %d %d %d", &n, &m, &start, &end);
for (i = 1; i <= n; i++)
for (j = 1; j <= n; j++)
if (i == j)
a[i][j] = 0;
else
a[i][j] = 99999999;
for (i = 1; i <= m; i++)
{
scanf("%d %d", &x, &y);
a[x][y] = 1;
a[y][x] = 1;
}
head = 1;
tail = 1;
que[tail].x = start;
que[tail].s = 0;
book[1] = start;
tail++;
int flag = 0;
while (head < tail)
{
//当前正在访问的顶点的编号
cur = que[head].x;
// 从1~n进行尝试
for (i = 1; i <= n; i++)
{
if (a[cur][i] != 99999999 && book[i] == 0)
{
que[tail].x = i;
que[tail].s = que[head].s + 1; //转机次数+1,基于的是头指针下的s
tail++;
book[i] = 1;
}
//如果tail>n则表示所有顶点都被访问过
if (que[tail].x == n)
{
flag = 1;
break;
}
}
if (flag == 1)
break;
//这里不要忘记,拓展完之后,要将头指针+1
head++;
}
printf("%d ", que[tail - 1].s);
return 0;
}
输出结果:














 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









