







目录
来源:ACL2020
机构:哈尔滨工业大学
论文认为存在的问题:
NQ数据集要求模型得到两个粒度的答案,分别是涵盖推断答案所需的所有信息的长答案(Long Answer),以及使用一个或者多个实体回答问题的短答案(Short Answer)。对于长答案,问答系统需要在给定的长答案候选项中进行选择,短答案则是在长答案内部得到。
下图给出了NQ数据集中的一个例子。

目前解决NQ任务的两类方法主要可以分为两大类,如下图所示,第一类是Pipeline方法,模型首先在长答案候选集合中选出长答案,然后再在选中的长答案内部抽取短答案;第二类是基于BERT的方法,模型直接在文档抽取短答案,然后直接在长答案候选集中选出包含短答案的长答案。

然而,以上两种方法都是将长短答案两个子任务独立考虑,而并没有想办法建模两个粒度答案之间的联系。由于长答案是文档中的段落,短答案是词片段,这里可以很自然用文档使用层次结构(文档->段落->句子->词)表示,并且用段落和词来建模两个粒度答案。由此,论文提出了基于图注意力网络和BERT的多粒度阅读理解框架,并且通过联合训练来建模两个粒度答案之间的联系。
数据处理:
由于NQ中文档的长度很长,和其他基于BERT的阅读理解模型一样,我们首先将问题和文档进行切分,然后将文档切成多个片段进行处理。由于我们的做法基于BERT,所以忽略掉维基百科文章中的所有HTML标签,然后在每个长答案候选项之前添加特殊标识符,形式如“[Paragraph=N]”,“[Table=N]”以及“[List=N]”。
通过判断文档片段中是否存在长答案和短答案,我们将训练数据的答案类别分为以下五类,分别是:
1)文档片段中包含所有短答案实体;2)文档片段中包含长答案,短答案为“yes”;3)文档片段中包含长答案,短答案为“no”;4)文档片段只包含长答案,没有短答案;5)文档不包含任何答案。
通过这种处理方式,我们得到的训练数据绝大部分都为第五种答案类型,为了平衡训练样本的类别,我们将这种不包含答案的样例随机筛选掉97%,最后得到大约660,000训练样例,其中有350,000条训练样例包含长答案,270,000条训练样例包含短答案。
模型框架:

我们针对这种NQ数据集提出了一个新的框架,整体系统架构如上图所示,我们将问题以及文档的每个片段独立的输入到模型中,通过BERT编码器进行编码,得到问题和文档片段的初步表示,然后用我们提出的图编码器用得到的表示进一步建模,最终得到一系列结构化的表示,汇总到答案选择模块得到答案。

上图出了我们图编码器的内部结构。每一层编码器都由三个自注意力(Self-attention)层,一个图信息整合(Graph Integration)层,以及一个前馈神经网络(Feed-forward)层组成。
多粒度文档建模思想:
该思想主要来源于文档自身的层次结构特性,通常来讲,文档可以被分解成一系列段落,而段落可以进一步被分解成句子以及词,所以可以很自然的将文档先表示为树结构,分别有以上四种粒度的节点。由于长答案都是文档中的段落,短答案都是文档中的词片段,所以段落粒度节点的信息可以表示长答案,短答案的信息也可以从词粒度节点中获得。
在以上得到的树结构基础上,我们进一步的加入了词粒度节点和段落粒度节点的边,词粒度节点和文档级别粒度的边,以及句子粒度节点到文档粒度节点的边,这些边在图中都是双向边。通过将树结构进一步建模成图结构,图中的每两个节点的距离都小于等于2,也就是说信息可以在两步之内进行传递。
补充:有关self-attention的一些数学推导:

如上图,在self-attention layer 里,每一个 input 都乘上3个不同的 transformation (不同的 matrix),产生三个不同量:,
和
。
得到,
和
之后,
就拿每个 query q 去对每个 key k 做 attention 。 如下图。

Scaled Dot-Product Attention:
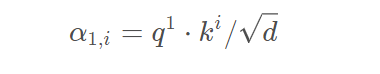

如上图,接下来对 做 softmax 处理,得到

如上,再通过如下运算,可得到考虑了全局信息的序列(中的第一个元素)。
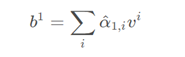
如果让只考虑前三个输入的影响,如何做呢?很简单,让其余的
在运算时为0即可。
,
...这些可以同时计算(Can be parallell computed)。
推理过程如下

如上,用大写符号,
,
,
代表变量叠加后的矩阵。

Multi-head Self-attention:

如上,使用 2 个 head 进行举例。得到了两个.

最后,可以再对两个 head 进行如上操作。
之所以用 Multi-head ,是希望每个 head 的关注点不同:有些看长时间的,有些看短期内的。
Positional Encoding:

李老师提供了一种讲法,先讲 concat ,最后达到了与原论文相同的效果(转化回原论文的式子)。

Transformer的encoder 多层叠加起来就是bert。

数据的输入
定义六元组:,声明
为文章的第i个document 片段
表示在
中长答案的候选集,
说明它是在
中的候选实例。
为目标答案的位置指针。
是答案的类型。
如果包含多个短答案,把指向第一个答案的最左端,
指向最后一个答案的最右端。
我们的目标是让model知道那个是长答案,以及短答案的位置
在
中。最后能够进行分数评估。
Graph Encoder 讲解
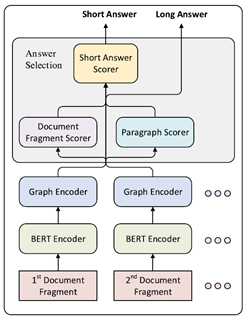
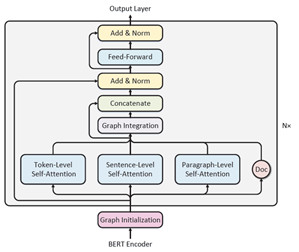
我们再看回上面两个图,开始大概讲下Graph Encoder。
定义一个图,图是由节点
,节点features
,和一组有向边集合
(其中k为边的数量)组成。每个representation
(
),
是模型的hidden size。
图中的self-attention是multi-head attention,论文中描述其中一个attention heads。如果边从j到i,则系数计算公式如下:
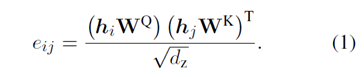
计算出所有的之后,softmax所有与i相邻的边j系数
。同时也允许self-loop更新。
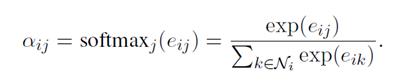
之后输出attention head
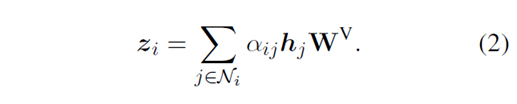
上面出现的 、
和
,其中
是其中一个head的size,即
。
最后我们得到的multi-head attention 结果。
用m个head结果串联起来的。
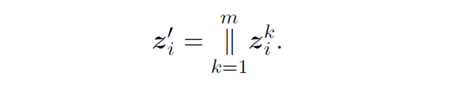
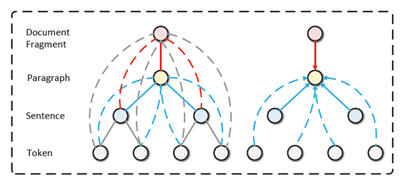
上图左边的图表是Graph Integration layer。右边的图表显示更新paragraph
node时传入信息的更新示图。实线表示文档层次树结构中的边,虚线表示我们额外添加的边。
我们利用Integration layer,意味着不同粒度级别的embedding可以利用其他节点的embedding。该层可以构建不同粒度节点答案之间的依赖性。
最后我们把Integration layer的输出和输入concatenate起来,输入feed-forward layer
Forward layer包含了两个线性转换函数中间加个GELU(Gaussian Error Linear Unit)激活函数。
论文受到positional encoding的启发,论文引入了一种新的关系embedding为了对多粒度文档结构中节点之间的相对位置信息进行建模。
我们让边附带上相对位置的信息。并修改了和
的公式:
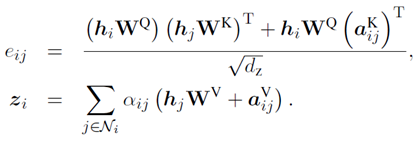
上面公式中的、
,代表learnable embedding。我们的关系向量主要加入了文档的结构信息,比如段落节点在接受信息时会考虑另外的节点是这个段落的第几个句子或者词。通过这种方式,我们将文档的结构信息在模型的表示中进一步的加强。
Graph Initialization layer,该层主要提供一个在文档的树结构上自底向上的average-pooling的初始化,因为bert只能提供token-level的embedding,主要是用来获得其他粒度的初始表示。论文使用代表不同类型的节点i,分别代表token、sentence、paragraph以及document。初始化公式为:
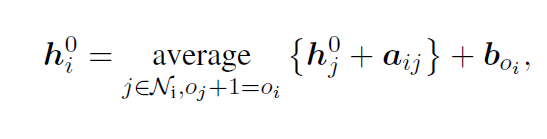
,
,分别代表了relational embedding和node type embedding。
Output layer 目标函数的预测分布定义为负对数概率之和,最后取平均。计算公式如下:

、
、
、
各自代表了短答案的开始结束位置的概率,长答案的概率,答案的类型的概率
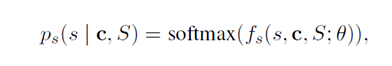
计算概率的公式如上,其中 是打分函数,来自graph encoder的最后一层。相似的,其他不同粒度也有类似的打分函数。如果没有短答案,我们将把s和e的索引设置为[CLS]的token,同时将[CLS]标记作为第一个句子和段落,如果没有长答案论文也将段落级的[CLS]作为长答案。
之后获取doc的分数,长答案
,短答案
。

论文会用和
的和来选择高分数的长答案,
考虑作为doc文本的一个偏置。我们会使用
去选择最后的短答案在被选择长答案的区间内。
最后,论文依赖于官方的NQ评估脚本来设置阈值,将长答案和短答案的预测区分为正面和负面。
到这里,Graph Encoder大致就讲完了
实验结果:
在得到这些不同粒度的表示后,我们通过对这些表示进行打分,再进行模型预测。我们进行预测时使用Pipeline策略:先预测长答案,再预测短答案,与之前基于BERT的方法中预测短答案再从长答案候选项中选择不同,我们在实验部分将后者视为基线模型。
使用了三种模型:Model-I: A BERT baseline
Model-II: pipeline model 只有graph initialization,method去获得sentence、paragraph、document的representation.
Model-III: 在Model-II的基础上增加了两层 graph encoder
Bert encoder 使用了:
bert-base-uncased:BERT-base-uncased model finetuned on SQuAD 2.0
bert-large-uncased:a BERT-large-uncased model finetuned on SQuAD 2.0
bert-syn:Google’s BERT-large-uncased model pre-trained on SQuAD2.0 with N-Gram Masking and Synthetic Self-Training.


由于NQ数据集不提供sentence层面的信息,我们额外使用spacy工具包作为句子切分器来获取句子的边界。
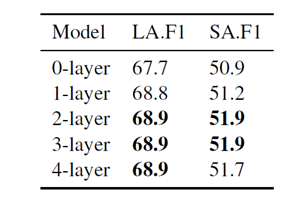
上图评估model的层数对F1的影响, 0层设置意味着只使用initialization
method来获取graph representations。我们将其归因于我们提出的图中每两个节点之间的信息可以通过不超过两条边,增加随机初始化参数的大小可能不利于BERT的fine-tuning.

上图中下面都是减去的layer做贡献度分析,对结果的影响。
下一步工作:
改进表示文档的graph structure以及document-level pretraining
tasks也是我们未来的研究目标。此外,当前存在的方法实际上无法在不截断或将其切片为片段的情况下处理长文档。如何对长文档建模仍然是一个需要解决的问题。















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









