







没有任务落后:多任务学习的知识跟踪和选项跟踪更好的学生评估

摘要
学生评价是人工智能教育(AIEd)领域最基本的任务之一。最常见的学生评估方法之一是知识追踪(KT),它通过预测学生是否会正确回答给定的问题来评估学生的知识状态。然而,在选择题(多选题)的情况下,传统的KT方法有局限性,它们只考虑二元(二分)的正确性标签(即正确或错误),而忽略学生选择的具体选项。选项跟踪(OT)试图通过预测学生在给定的问题上会选择哪个选项来模拟学生,但忽略了正确性信息。在本文中,我们提出了一种结合KT和OT的多任务学习框架(DichotomousPolytomous Multi-Task Learning, DP-MTL),以更精确地评估学生。特别是,我们展示了KT目标作为DP-MTL框架中OT的正则化项,并提出了一个适当的架构,用于将我们的方法应用于现有的基于深度学习的KT模型之上。我们通过实验证实,DP-MTL显著提高了KT和OT性能,也有利于下游任务,如评分预测(SP)。
1 引言
人工智能教育(AIEd)领域致力于开发有助于人类学习的人工智能系统,并有潜力以负担得起的成本为更广泛的受众提供个性化教育。学生评价是对学生知识水平进行评价的过程,是AIEd最基本的任务之一。然后,适当的学生评估可以用于许多下游教育任务,如分数预测(SP) (Su等人2018;Yin等人2019;Choi等人2021年)和个性化内容推荐(Chen、Lee和Chen 2005;王2008;Wang et al. 2016;Ai et al. 2019)。
知识追踪(KT) (Corbett and Anderson 1994)通过预测学生是否能正确回答给定的问题来模拟学生的知识状态。由于该方法的简单性和领域不可预测性,KT已被广泛用于AIEd中的学生评估(Choi et al. 2020a;Piech et al. 2015)。但是,对于涉及多项选择题(polytomous)的教育内容,KT只考虑正确性的二进制(二分法)标签,而不考虑学生的选项。因此,KT无法区分那些回答错误的学生,而在现实中,一个学生的答案可能比另一个学生的答案更接近正确答案。
选项跟踪(OT)(高希,拉斯帕特和Lan 2021;Thissen和Steinberg 1984)是一种明确模拟学生回答的方法,即选择题。OT考虑了学生的选项选择信息,但没有考虑学生的正确性。因此,OT可能无法正确跟踪学生的知识状态。这激发了一种多任务学习方案,能够利用了正确性标签和选项标签。
在本文中,我们提出了二分多任务学习(DP-MTL),该模型学习预测学生对给定问题的正确性和选项选择。这样,DP-MTL就可以在更细粒度的层次上跟踪学生的知识状态。在我们的实验中,我们证明了DP-MTL确实提高了KT、OT和SP性能。我们期望DP-MTL能够实现更精确的学生表征学习,这反过来也将有利于许多其他下游教育任务。
本文的主要贡献如下:
- 我们引入了DP-MTL,并表明,在这个框架中,KT目标作为OT的正则化项。
- 此外,我们提出了一种架构设计,用于在现有KT模型上组合KT和OT。
- 我们通过实验证实,我们的方法在基于两个不同数据集的三个流行KT模型上应用时,显著提高了KT、OT和SP性能。
据我们所知,这是第一个结合KT和OT来更好地评估学生的工作。
2 相关工作
知识追踪
知识追踪(KT)是通过预测学生是否能正确回答给定问题来模拟学生知识状态的一种学生评估任务。二分式项目反应理论(D-IRT)模型(Kingston和Dorans 1982;Way和Reese 1990;Chen, Lee, and Chen 2005)利用提取的用户参数和项目参数预测学生答案的正确性,其中用户参数和项目参数分别对应于用户的技能和问题的难度。
协同过滤(CF)方法等效于多维D-IRT方法(除了没有sigmoid函数)(Vie and Kashima 2019),将每个用户(物品)建模为一个用户(物品)向量,而不是标量值。虽然CF最初是为推荐系统开发的(Koren, Bell和V olinsky 2009),但CF已广泛用于KT (Khosravi, Cooper和Kitto 2017;《Vie and Kashima 2019》)。最近,神经矩阵分解(NMF)方法被提出用神经网络计算取代传统的CF中使用的点乘积(He et al. 2017;Xue et al. 2017)。
序列KT方法对学生的学习轨迹进行建模,而不是像在D-IRT和CF中那样在原子级别对交互进行建模。贝叶斯知识跟踪(BKT) (Corbett和Anderson 1994)是最初的KT方法,它基于隐藏的马尔可夫模型跟踪学生的知识状态。最近,许多研究工作致力于将各种深度学习架构应用于序列KT,包括基于rnn的模型(Piech et al. 2015;Minn 2020),动态Key-V值记忆网络(DKVMN) (Zhang等人2017年),以及基于变压器的模型(Pandey和Karypis 2019;Choi等人。2020a)。
上述所有方法只考虑KT,不执行OT。我们将我们提出的方法DPMTL应用于三种流行的KT方法之上,即(1)DIRT,(2)协同过滤,和(3)基于lstm的KT,并证明DP-MTL在所有考虑的模型上持续改善KT性能。
Option Tracing(选项追踪)
选项追踪(OT) (Ghosh, Raspat, and Lan, 2021)是一项通过预测学生对多项选择题的答案来跟踪学生的知识状态的评估任务。多组分IRT (P-IRT),类似于D-IRT,利用提取的用户参数和项目选项参数预测学生的选项选择。最近,Ghosh、Raspat和Lan(2021年)提出了基于改进的深度KT模型进行OT,以实现更准确的学生评估。然而,(1)他们没有考虑同时进行KT和OT的多任务学习设置;(2)当执行OT时,它们的架构不能考虑细微的细节(例如,排列选项(A,B,C)到(B,A,C)不会改变预测从(pA, pB, pC)到(pB, pA, pC))。我们不仅考虑了KT和OT的多任务学习,而且还相应地提出了一个合适的深度学习架构。
成绩预测
学生成绩预测(SP)是我们在这项工作中考虑的另一个重要的学生评估任务(Sweeney, Lester,和Rangwala 2015;Iqbal等人2017;卢、蔡、黄禹锡2020年)。先验SP方法依赖于协同过滤(Elbadrawy和Karypis 2016;Sweeney et al. 2016)和回归模型(Morsy和Karypis 2017;Ren et al. 2019)。其他最近的方法利用KT算法,并将SP作为下游任务(Liu et al. 2019;Choi等人,2021年)。我们还将SP视为下游任务,并表明DP-MTL可以提高SP的性能。
多任务学习
多任务学习(MTL) (Caruana 1997)是一种训练模型同时执行多个相关任务的机器学习方法。MTL假设来自特定领域的训练信号有助于形成对其他相关任务的归纳偏倚。在这项工作中,我们证明KT和OT是这样的相关任务的一个例子,当同时执行时,是互利的。
3 所提方法
在本节中,我们提出了同时学习KT和OT的二分多任务学习(DP-MTL)。特别地,我们表明,在DP-MTL框架中,多任务学习目标有一个可解释的解释:KT损失作为OT的正则化术语。此外,我们还提出了在现有KT模型上应用DP-MTL所必需的架构设计。
传统的二分模型是通过最小化观察交互的负对数似然来训练的,交互由用户、物品和对应的正确性组成。这相当于根据学生交互数据最大化用户对项目正确/错误响应的条件概率。换句话说,
5 实验结论
DP-MTL 的影响:λ消融
由于不同的任务和数据集产生显著不同规模的性能指标,配置级性能等级为11 λ值(0.0,0.1,…, 1.0)在不同的数据集和模型上取平均值。结果如图3所示。每条线对应SP、KT、OT的不同任务。平均秩y轴值越小,说明性能相对较好。例如,对于所有三个任务,使用λ值为0或1的表现明显不如λ值为接近0.5的表现。这种凸性为我们提出的DP-MTL框架优于KT和OT两种极端基线方法提供了强有力的经验证据。我们强调任务A (KT)和任务B (OT)的多任务学习不仅改善了下游任务C (SP)的指标,而且也改善了原始任务A和任务B的指标。
所有三个单独的模型分别显示了与λ参数有关的秩平均度量的理想凸形状,如图4所示。DPNMF模型对KT和OT基线的改进程度最大,可训练参数的数量相对于其他两种模型较大。
我们还注意到,不同的模型显示了不同的趋势的最优λ关于数据稀疏性。对于DP-NMF,大多数λ超参数选择为0.6和0.7,一致。图5显示了在每个稀疏比设置中标准化的ENEM数据集的SP-MAE指标的热图。小MAE的大连续蓝色区域强调了引入λ跨越稳定范围和不同数据稀疏率的优势。与DP-NMF相反,DP-BiDKT的最优λ值随着数据集稀疏性的增加而逐渐减小。提出的DP-MTL框架允许模型在KT和OT之间调整其注意力。
知识追踪和选项追踪
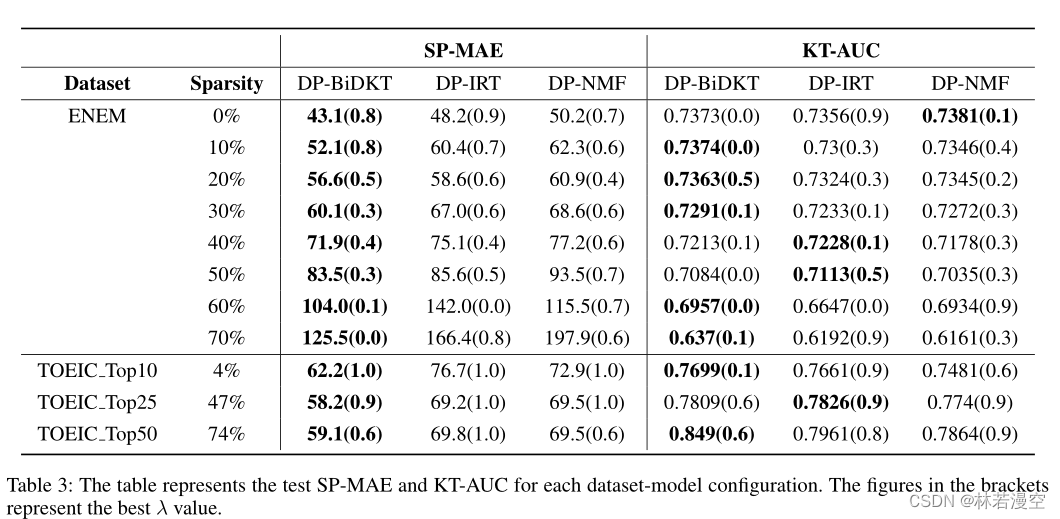
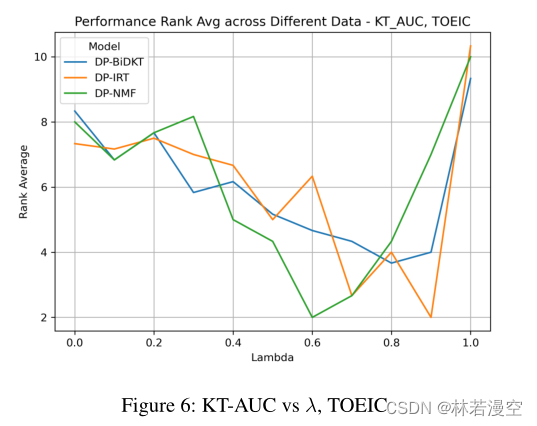
从表3的KT-AUC块中,ENEM数据集中的最优λ值接近于0,而不是1。换句话说,在ENEM数据集的KT-AUC方面,单独处理OT任务会产生更好的结果。这一趋势在TOEIC数据集中尤其明显,如图6所示。三种模型中,仅关注KT(第10位)的KT- auc性能不如仅关注OT(第8位),λ值介于0.6 ~ 0.9之间时,性能得到了显著提升(第2-4位)。
模型比较
基于从验证集性能中选择的超参数配置,表3提供了ENEM和TOEIC数据集的测试性能指标。第一个区块代表Score Prediction-Mean Absolute Error (SP-MAE)的结果,第二个区块代表Knowledge Tracing-Area Under ROC Curve (KT-AUC)。对于每个任务,性能最好的模型条目以粗体突出显示,括号中的数字表示在我们的DP-MTL框架中选择的λ参数。我们重申,λ = 1对应KT/D-IRT情景,λ = 0对应OT/P-IRT情景。
分数预测
KT和OT
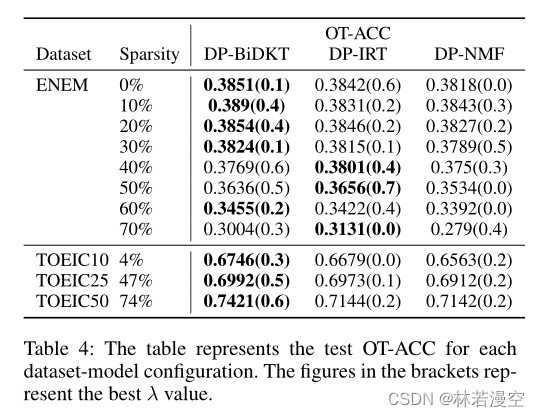
虽然DPBiDKT模型的优势不如分数预测任务显著,但无论是在知识跟踪任务还是选项跟踪任务中,DPBiDKT模型在大多数设置下都取得了最好的结果。(选项跟踪结果见附录表4)此外,在最稀疏的TOEIC Top50数据集中,DP-BiDKT模型在KT和OT任务指标上比亚军分别提高了6.6%和3.9%。
综上所述,实证结果有力地支持了DP-MTL框架对所有三个评估用户物品表征质量的任务的有效性。KT和OT的多任务学习方法不仅对下游的SP任务产生最优解,而且对KT和OT本身也产生最优解。此外,我们的DP-BiDKT体系结构通过有效的参数缩减/重用和新颖的用户交互序列编码,比标准基线算法取得了显著的改进。
结论
本研究提出了一个多任务学习框架,包括(a)反应正确性和(b)学生的特定反应选择,提供了一个更全面的学生评估模型,优于现有的单任务基准。来自两个数据集和三个任务的大量实证结果(1)显示了对现有模型(IRT, CF, NMF)的显著改进,(2)揭示了各种数据稀疏条件下KT和OT之间的有趣关系。此外,在我们的DP-MTL框架下,为了进一步提高参数效率和简化输入编码,我们提出了定制的DP-BiDKT架构,在大多数实验设置下都取得了最好的性能。
除了提高KT/OT性能之外,这项研究还提供了一个例子,在这个例子中,更好的用户项表示可以有利于单独的下游任务,如学生成绩预测。其他潜在的未来应用包括个性化教育内容推荐和基于学生和教育内容改进表征学习的弱点识别。















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









