






Transformer
Transformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型
Attention is All You Need:https://arxiv.org/abs/1706.03762
Transformer使用的是自注意力机制,在这之前我们先来了解什么是注意力机制。
attention
参考了博客
注意力机制(Attention)原理详解
注意力机制(Attention Mechanism)是人们在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。
传统机器翻译

很经典的RNN模型
缺点在于
- 输入句子很长的时候,前面的信息可能不能很好的被encoder记录
- 只能接受历史消息,不能考虑全局。
引入attention机制

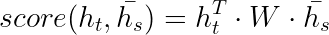


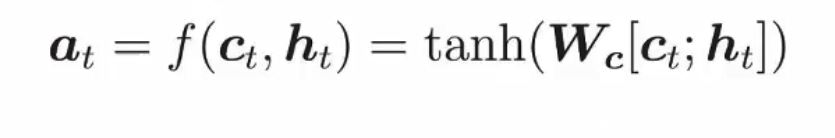
h1 h2 h3所有的隐藏状态。我们可以理解为他包含了说有历史信息。经过这几个公式之后,得出的向量是相关新最高的向量。因为现在都在流行自注意力机制(self-attention),他的流程大致上是相同的。我会在自注意力详细的说。
self-attention
这里强烈安利一个老师,台大李宏毅老师,我就是按照他的课程学习的

通过这张图,其实自注意力想法和注意力的想法都是相同的。对于每一个输入,我们希望考虑到他的全部输入,通过全局的信息来推断这个输出。
具体的内部

(之前还会对数据做一些预处理,如果处理的是文本,音频数据,都会转换成向量的形式)
首先对于一个输入向量,我们会把它映射成三个向量,这里还没说到矩阵呢!q , k ,v 这三个矩阵。转换这三个向量的规则是需要训练的。
关于QKV形象的解释
你有一个问题Q,然后去搜索引擎里面搜,搜索引擎里面有好多文章,每个文章V有一个能代表其正文内容的标题K,然后搜索引擎用你的问题Q和那些文章V的标题K进行一个匹配,看看相关度(QK —>attention值),然后你想用这些检索到的不同相关度的文章V来表示你的问题,就用这些相关度将检索的文章V做一个加权和,那么你就得到了一个新的Q’,这个Q’融合了相关性强的文章V更多信息,而融合了相关性弱的文章V较少的信息。这就是注意力机制,注意力度不同,重点关注(权值大)与你想要的东西相关性强的部分,稍微关注(权值小)相关性弱的部分。
总而言之,现在你有q k v这三个向量了。
- 拿出q与 k1 k2 k3 k4进行点积(向量的点积),点积之后的值用于衡量相关性。
- 加和。这里我当时思考了很久。现在每一个v都代表这个输入在这个方面的特点(接下来将多头只注意里机制的时候,可能会理解的更清晰一点。),点积后的相关系乘上这个v,代表的是这个向量关于a1(假设现在用a1举例),在这个特点上的相似程度。相似程度高就权重更大,影响更大。
一个很重要的点。不知道大家发现没有

自注意力机制是可以一次性全部输入,也就是说自注意力机制是平行输入的,这样相对于RNN他的速度可以快很多。
接下来的东西就是线性代数了




到这里差不多可以说是,把self-attention的基本原理理解透彻了
多头注意力机制,为什么要加上多头的机制呢。因为数据有很多的特点。比如之前在学习CNN卷积神经网络的时候,我们对一张图片有纵向和横向两个维度的特点选取。那么对于文字(我这里拿文字举例,还有音频啥的),有字形,字音,意义的这些特点,如果能综合这三个维度是不是能带来更好的转换结果呢。多头注意力机制就是来处理这个问题的。


核心理论学的差不多,那现在要来看一些边边角角了。我们发现对于语音翻译,我们对于位置这个很关键的信息并没有给出一个很好的规定。
位置的编码有两个方式
Sinusoidal Position Encoding
learned position embedding
两个方法效果差不多,但是第一个不需要经过学习,也是tansformer中使用的
参考博客1
参考博客2
来讲解一下公式
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
model
)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
model
)
(eq.1)
PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{\text{model}}}) \quad PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}})\tag{eq.1}
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)(eq.1)
- pos表示这个字/词在一句话中的位置
- i表示字/词向量的维度
- dmodel词向量/模型的维度
tip:初学的时候我再dmodel和i之间的意思表达的不清楚,其实看代码就一目了然了。
import matplotlib.pyplot as plt
import math
def positional_enc(pos,i):
return math.sin(pos / (10000**(2*i/32)) if i%2==0 else math.cos(pos / (10000**(2*i/32))))
#注意这里的32这个是dmodel的大小
#这个函数,如果给的i是奇数,就用cos,如果是奇数就用sin
plt.figure(figsize=(20,10))#定义画布大小
for pos_value in range(50):#这里range(50)的意思,就相当于定义这句话的词汇量是50个词
embedding_idxs = list(range(0,32))#这里range(0,32)相当于,我们把一次词汇/字映射成32长度的向量,也是dmodel的小
sin_cos_value = [positional_enc(pos_value,i) for i in embedding_idxs]#注意这里的i,从0-31的遍历,这里也能说明i其实就是遍历dmodel的大小
plt.plot(embedding_idxs,sin_cos_value,label=str(pos_value))
plt.xlabel("embedding_idx")
plt.ylabel("sin_value")
plt.legend(loc = 'upper right')
plt.show()

这是运行的结果。那其实可以看到,随着i的增加(一个指数型的增加)到后期值的变化都是相同的,但是前面的差距很大,由这个,我们定义出不同的纹理也就是依靠这不同的曲线获得他的位置信息!
自注意力机制了解了,现在开始学习tansformer到底是个什么东西
transformer
先甩一张每个人学习tansformer都会看到的图

把这张图片吃透,就可以说好好理解了tansformer了
在真正深入的学习tansformer之前,我想先来聊一聊什么是残差网络

残差网络用于解决,深层的神经网络训练效果还没浅层神经网络训练结果的这么一个问题。

这张图片是核心,现在是在X原本输入的基础上,增加一个残差量(可以参考最小二乘法的残差量),而不是直接去改变他本身的值。
先来看看encoder层

- 输出是先embedding过的
- 多头自注意力机制之后还套用了残差网络,并且进行了归一化
- 输入到前馈神经网络的也是经过残差网络处理的
再来看看decoder层

首先decoder的输出是一个分布。有一个词汇表(假设有3000个常用单词),现在用的就是一个分布,看哪个词的输出概率高,就用哪个。对于encoder层的输入,一定要给定一个起始标志。

来介绍一下什么是
Masked multi-Head attention

就是只考虑历史数据,不考虑未来的数据了。为什么这么做呢,取决于decoder特殊的输入,decoder的输入是一个一个的,也就是说decoder的历史数据就是全局数据。
Cross-attention
encoder和decoder之间的联系就是依靠cross-attention来实现的
你可以简单理解为,decoder出一个Q,encoder出K V
Transformer大体上就是这样了















 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









