







栈(stack )又称堆栈,它是运算受限的线性表,其限制是仅允许在表的一端进行插入
和删除操作,不允许在其他任何位置进行插入、查找、删除等操作。表中进行插入、删除操
作的一端称为 栈顶(top) ),栈顶保存的元素称为 栈顶元素。相对的,表的另一端称为栈底
当栈中没有数据元素时称为空栈;向一个栈插入元素又称为 进栈或 入栈;从一个栈中删
除元素又称为 出栈或 退栈。由于栈的插入和删除操作仅在栈顶进行,后进栈的元素必定先出
栈,所以又把堆栈称为 后进先出表(Last In First Out,简称 LIFO)。图 4-1 显示了一个堆栈
及数据元素插入和删除的过程。
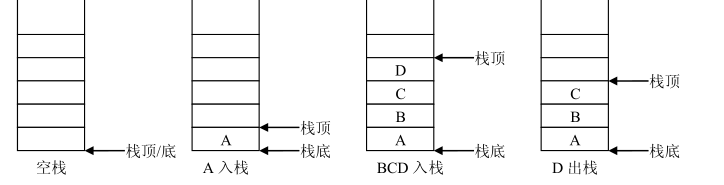
当 ABCD 均已入栈之后,出栈时得到的序列为 DCBA,这就是“后进先出”。
在解决实际问题时,如果碰到了数据的使用具有“后进先出”的特性,就预示着可以使用堆
栈来存储和使用这些数据。
堆栈的基本操作除了进栈、出栈操作外,还有判空、取栈顶元素等操作。下面给出堆栈
的抽象数据类型定义。

栈的顺序存储实现
和线性表类似,堆栈也有两种基本的存储结构:顺序存储结构和链式存储结构。
顺序栈是使用顺序存储结构实现的堆栈,即利用一组地址连续的存储单元依次存放堆栈
中的数据元素。由于堆栈是一种特殊的线性表,因此在线性表的顺序存储结构的基础上,选
择线性表的一端作为栈顶即可。根据数组操作的特性,选择数组下标大的一端,即线性表顺
序存储的表尾来作为栈顶,此时入栈、出栈等操作可以在Ο(1)时间完成。
由于堆栈的操作都在栈顶完成,因此在顺序栈的实现中需要附设一个指针 top 来动态的
指示栈顶元素在数组中的位置。通常 top 可以用栈顶元素所在数组下标来表示,top= -1 时表
示空栈。图 4-1 就可以看成是一个顺序栈。
堆栈在使用过程中所需的最大空间很难估计,因此,一般来说在构造堆栈时不应设定堆
栈的最大容量。一种合理的做法和线性表的实现类似,先为堆栈分配一个基本容量,然后在
实际的使用过程中,当堆栈的空间不够时再倍增存储空间,这个过程所需的时间均摊到每个
数据元素时间为Θ(1),不会影响操作实现的时间复杂度。
public class StackArray implements Stack{
private Object[] data;
private int top ; //指针指向数组的下标
public StackArray() {
top =-1;
data = new Object[10];
}
public Object[] getData() {
return data;
}
public void setData(Object[] data) {
this.data = data;
}
public int getTop() {
return top;
}
public void setTop(int top) {
this.top = top;
}
@Override
public int getSize() {
return top+1;
}
@Override
public boolean isEmpty() {
return top<0;
}
//入栈
@Override
public void push(Object e) {
group(e);
data[++top] = e;
}
private void group(Object e) {
if((top+1)==data.length){
Object[] objects = new Object[data.length<<1];
for(int i=0;i<data.length;i++){
objects[i] = data[i];
}
//重新定义数组
data = objects;
}
}
//出栈
@Override
public Object pop() {
if(isEmpty()){
throw new RuntimeException("现在没有数据");
}
Object pop= data[top--];
data[top--]=null; //出栈后将改元素下标置为空
return pop;
}
//得到栈顶元素但是不出栈
@Override
public Object peek() {
return data[top];
}
}
总结:给数组扩容的时候注意重新指向新数组
出栈的时候元素的数组位置应该置为null
栈的链式存储实现
链栈即采用链表作为存储结构实现的栈。当采用单链表存储线性表后,根据单链表的操
作特性选择单链表的头部作为栈顶,此时,入栈、出栈等操作可以在Ο(1)内完成。由于堆
栈的操作只在线性表的一端进行,在这里使用带头结点的单链表或不带头结点的单链表都可
以。使用带头结点的单链表时,结点的插入和删除都在头结点之后进行;使用不带头结点的
单链表时,结点的插入和删除都在链表的首结点上进行。
下面以不带头结点的单链表为例实现堆栈,读者可以对照完成使用带头结点的单链表的
实现。图 4-2 给出了使用不带头结点的单链表实现堆栈的示意图。

public class StackArrayLinked {
private DubbloNode head = new DubbloNode(); //伪头节点
private DubbloNode tail = new DubbloNode(); //伪尾节点
private int size;
public StackArrayLinked() {
head.setNext(tail);
tail.setPre(head);
}
public void push(Object e){
DubbloNode node = new DubbloNode(e);
node.setNext(head.getNext());
node.setPre(head);
head.setNext(node);
head.getNext().setPre(node);
size++;
}
public Object pop(){
DubbloNode node = head.getNext();
DubbloNode newnode = node;
head.setNext(node.getNext());
return newnode;
}
public int size(){
return size;
}
}















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









