







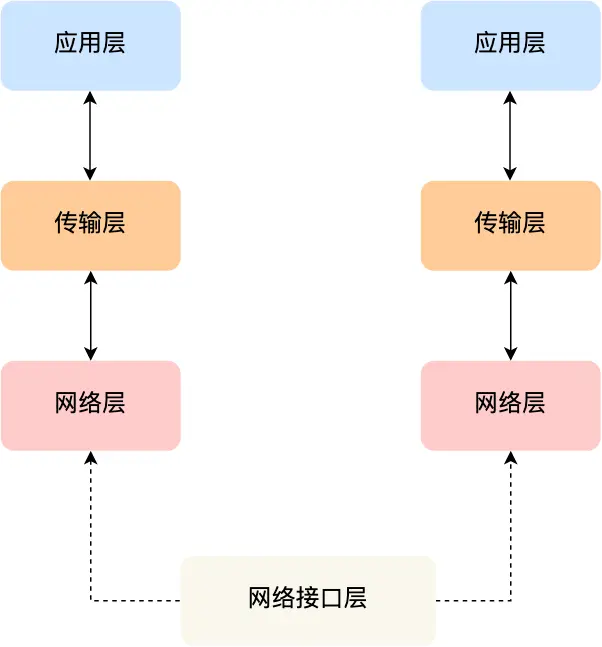
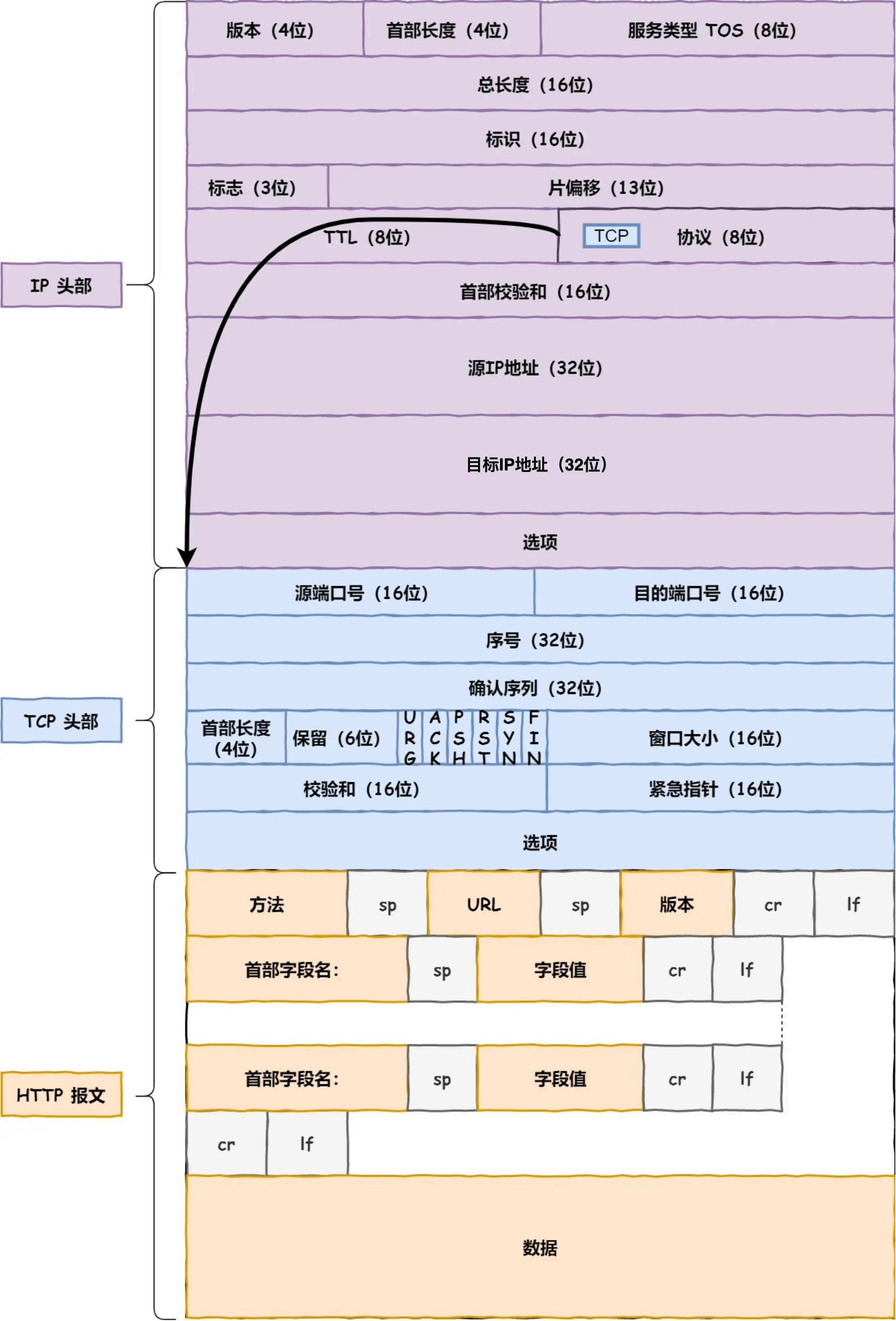
1.TCP/IP 网络模型有哪几层?
对于同⼀台设备上的进程间通信,有很多种⽅式,⽐如有管道、消息队列、共享内存、信号等⽅式,⽽对
于不同设备上的进程间通信,就需要⽹络通信,⽽设备是多样性的,所以要兼容多种多样的设备,就协商
出了⼀套通⽤的⽹络协议。这个⽹络协议是分层的,每⼀层都有各⾃的作⽤和职责。
从上到下分为应用层,传输层,网络层,接口层
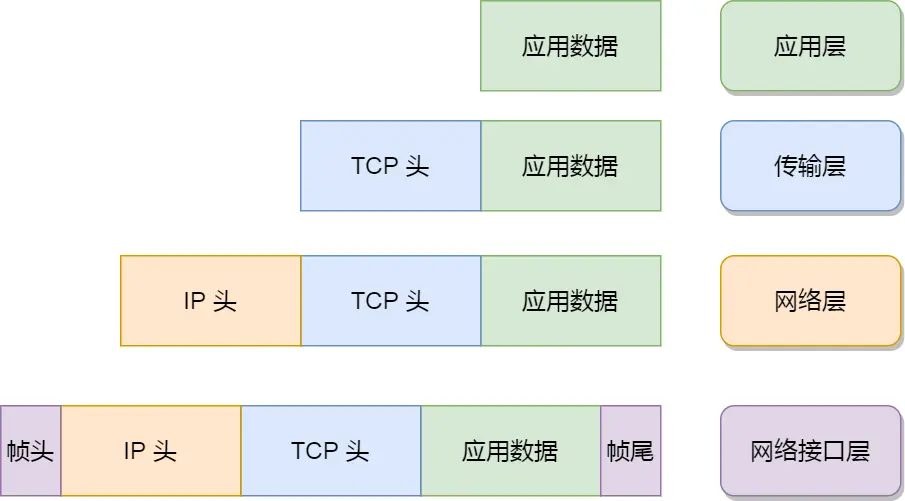
⽹络接⼝层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段
(segment),HTTP 的传输单位则是消息或报⽂(message)。但这些名词并没有什么本质的区分,可以
统称为数据包。
2.简单介绍应用层
最上层的,也是我们能直接接触到的就是应⽤层(Application Layer),我们电脑或⼿机使⽤的应⽤软件
都是在应⽤层实现。那么,当两个不同设备的应⽤需要通信的时候,应⽤就把应⽤数据传给下⼀层,也就
是传输层。
所以,**应⽤层只需要专注于为⽤户提供应⽤功能,⽐如 HTTP、FTP、Telnet、DNS、SMTP**等。
应⽤层是不⽤去关⼼数据是如何传输的,就类似于,我们寄快递的时候,只需要把包裹交给快递员,由他
负责运输快递,我们不需要关⼼快递是如何被运输的。
⽽且应⽤层是⼯作在操作系统中的⽤户态,传输层及以下则⼯作在内核态。
3.简单介绍传输层
应⽤层的数据包会传给传输层,传输层(Transport Layer)是为应⽤层提供⽹络⽀持的。
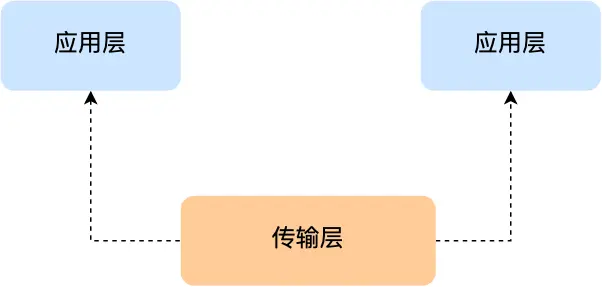
在传输层会有两个传输协议,分别是 TCP 和 UDP。
TCP 的全称叫传输控制协议(Transmission Control Protocol),⼤部分应⽤使⽤的正是 TCP 传输层协
议,⽐如 HTTP 应⽤层协议。TCP 相⽐ UDP 多了很多特性,⽐如流量控制、超时重传、拥塞控制等,这
些都是为了保证数据包能可靠地传输给对⽅。
UDP 相对来说就很简单,简单到只负责发送数据包,不保证数据包是否能抵达对⽅,但它实时性相对更
好,传输效率也⾼。当然,UDP 也可以实现可靠传输,把 TCP 的特性在应⽤层上实现就可以,不过要实
现⼀个商⽤的可靠 UDP 传输协议,也不是⼀件简单的事情。
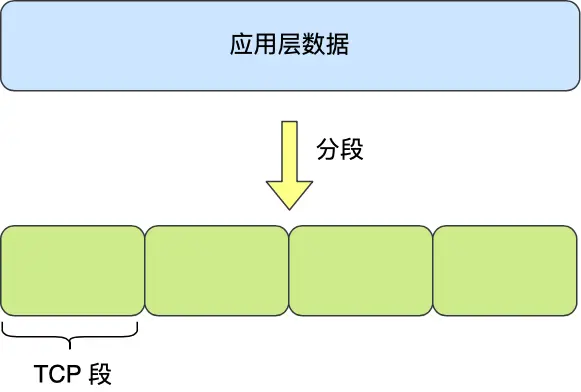
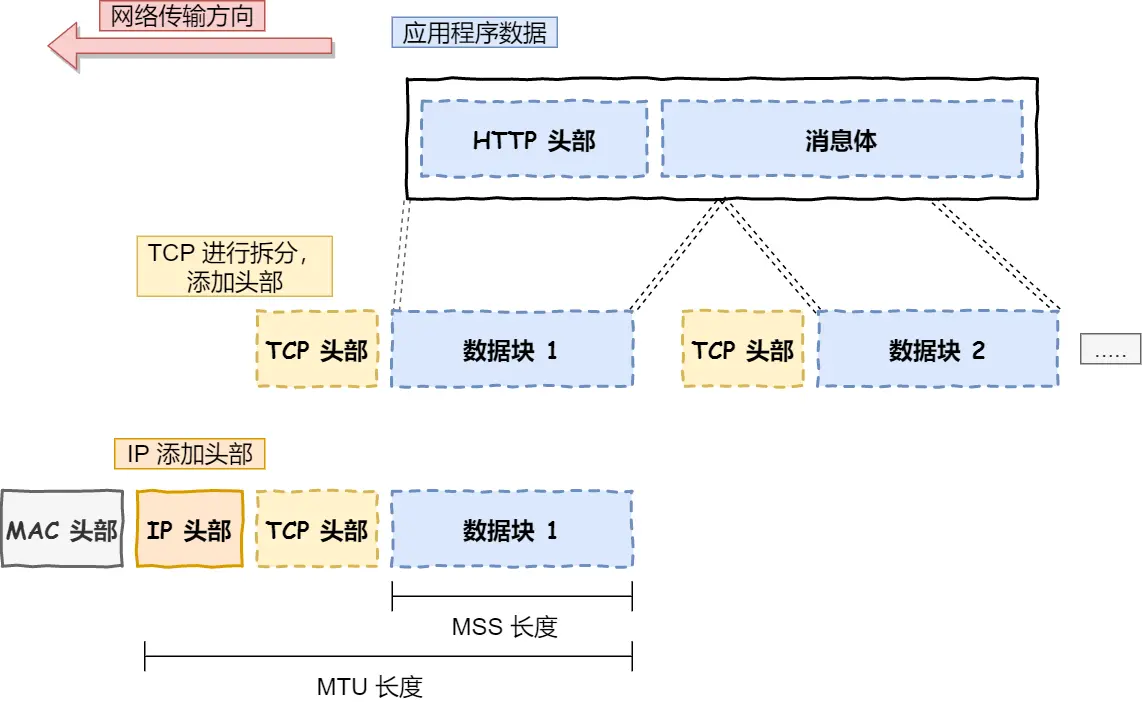
应⽤需要传输的数据可能会⾮常⼤,如果直接传输就不好控制,因此当传输层的数据包⼤⼩超过 MSS
(TCP 最⼤报⽂段⻓度) ,就要将数据包分块,这样即使中途有⼀个分块丢失或损坏了,只需要᯿新发送
这⼀个分块,⽽不⽤᯿新发送整个数据包。在 TCP 协议中,我们把每个分块称为⼀个 TCP 段(TCP
Segment)。
当设备作为接收⽅时,传输层则要负责把数据包传给应⽤,但是⼀台设备上可能会有很多应⽤在接收或者
传输数据,因此需要⽤⼀个编号将应⽤区分开来,这个编号就是端⼝。
⽐如 80 端⼝通常是 Web 服务器⽤的,22 端⼝通常是远程登录服务器⽤的。⽽对于浏览器(客户端)中的
每个标签栏都是⼀个独⽴的进程,操作系统会为这些进程分配临时的端⼝号。
由于传输层的报⽂中会携带端⼝号,因此接收⽅可以识别出该报⽂是发送给哪个应⽤。
4.简单介绍网络层
传输层可能⼤家刚接触的时候,会认为它负责将数据从⼀个设备传输到另⼀个设备,事实上它并不负责。实际场景中的⽹络环节是错综复杂的,中间有各种各样的线路和分叉路⼝,如果⼀个设备的数据要传输给
另⼀个设备,就需要在各种各样的路径和节点进⾏选择,⽽传输层的设计理念是简单、⾼效、专注,如果
传输层还负责这⼀块功能就有点违背设计原则了。
也就是说,我们不希望传输层协议处理太多的事情,只需要服务好应⽤即可,让其作为应⽤间数据传输的
媒介,帮助实现应⽤到应⽤的通信,⽽实际的传输功能就交给下⼀层,也就是⽹络层(Internet Layer)
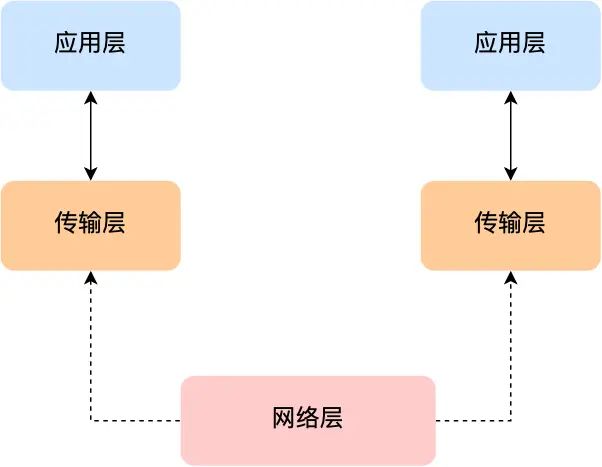
⽹络层最常使⽤的是 IP 协议(Internet Protocol),IP 协议会将传输层的报⽂作为数据部分,再加上 IP 包
头组装成 IP 报⽂,如果 IP 报⽂⼤⼩超过 MTU(以太⽹中⼀般为 1500 字节)就会再次进⾏分⽚,得到⼀
个即将发送到⽹络的 IP 报⽂。
⽹络层负责将数据从⼀个设备传输到另⼀个设备,世界上那么多设备,⼜该如何找到对⽅呢?因此,⽹络
层需要有区分设备的编号。
我们⼀般⽤ IP 地址给设备进⾏编号,对于 IPv4 协议, IP 地址共 32 位,分成了四段(⽐如,
192.168.100.1),每段是 8 位。只有⼀个单纯的 IP 地址虽然做到了区分设备,但是寻址起来就特别麻
烦,全世界那么多台设备,难道⼀个⼀个去匹配?这显然不科学。
因此,需要将 IP 地址分成两种意义:
-
⼀个是⽹络号,负责标识该 IP 地址是属于哪个「⼦⽹」的;
-
⼀个是主机号,负责标识同⼀「⼦⽹」下的不同主机;
-
怎么分的呢?这需要配合⼦⽹掩码才能算出 IP 地址 的⽹络号和主机号。
举个例⼦,⽐如 10.100.122.0/24,后⾯的 /24 表示就是 255.255.255.0 ⼦⽹掩码,255.255.255.0 ⼆进
制是「11111111-11111111-11111111-00000000」,⼤家数数⼀共多少个1?不⽤数了,是 24 个1,为
了简化⼦⽹掩码的表示,⽤/24代替255.255.255.0。
知道了⼦⽹掩码,该怎么计算出⽹络地址和主机地址呢?
将 10.100.122.2 和 255.255.255.0 进⾏按位与运算,就可以得到⽹络号,如下图:
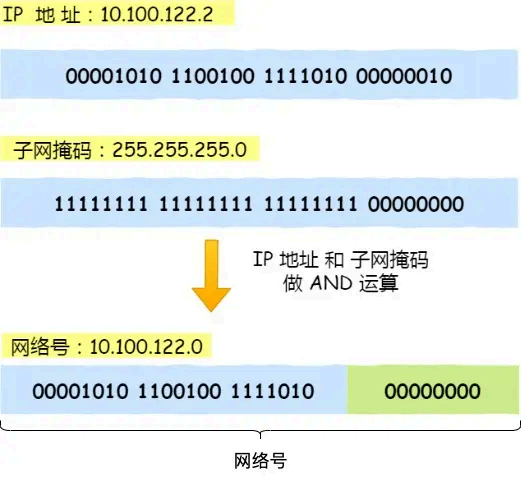
将 255.255.255.0 取反后与IP地址进⾏进⾏按位与运算,就可以得到主机号
那么在寻址的过程中,先匹配到相同的⽹络号(表示要找到同⼀个⼦⽹),才会去找对应的主机。
除了寻址能⼒, IP 协议还有另⼀个᯿要的能⼒就是**路由**。实际场景中,两台设备并不是⽤⼀条⽹线连接起
来的,⽽是通过很多⽹关、路由器、交换机等众多⽹络设备连接起来的,那么就会形成很多条⽹络的路
径,因此当数据包到达⼀个⽹络节点,就需要通过路由算法决定下⼀步⾛哪条路径。
路由器寻址⼯作中,就是要找到⽬标地址的⼦⽹,找到后进⽽把数据包转发给对应的⽹络内
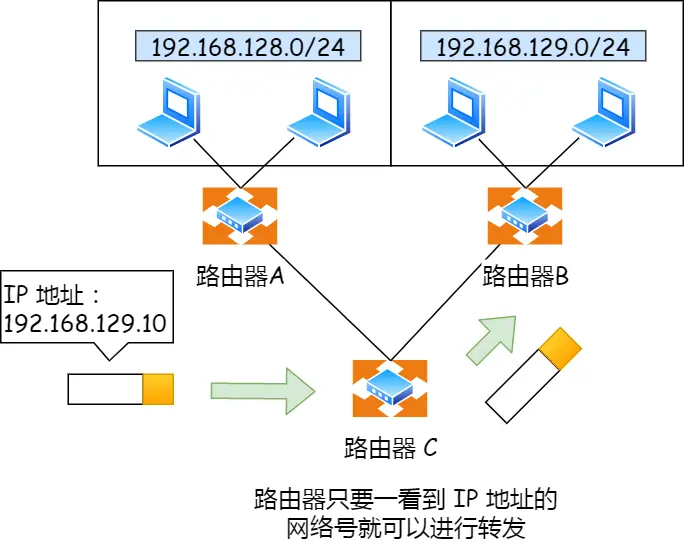
所以,IP 协议的寻址作⽤是告诉我们去往下⼀个⽬的地该朝哪个⽅向⾛,路由则是根据「下⼀个⽬的地」
选择路径。寻址更像在导航,路由更像在操作⽅向盘。
5.简单介绍网络接口层
⽣成了 IP 头部之后,接下来要交给⽹络接⼝层(Link Layer)在 IP 头部的前⾯加上 MAC 头部,并封装成
数据帧(Data frame)发送到⽹络上。
IP 头部中的接收⽅ IP 地址表示⽹络包的⽬的地,通过这个地址我们就可以判断要将包发到哪⾥,但在以太
⽹的世界中,这个思路是⾏不通的。
什么是以太⽹呢?电脑上的以太⽹接⼝,Wi-Fi接⼝,以太⽹交换机、路由器上的千兆,万兆以太⽹⼝,还
有⽹线,它们都是以太⽹的组成部分。以太⽹就是⼀种在「局域⽹」内,把附近的设备连接起来,使它们
之间可以进⾏通讯的技术。
以太⽹在判断⽹络包⽬的地时和 IP 的⽅式不同,因此必须采⽤相匹配的⽅式才能在以太⽹中将包发往⽬的
地,⽽ MAC 头部就是⼲这个⽤的,所以,在以太⽹进⾏通讯要⽤到 MAC 地址。
MAC 头部是以太⽹使⽤的头部,它包含了接收⽅和发送⽅的 MAC 地址等信息,我们可以通过 ARP 协议
获取对⽅的 MAC 地址。
所以说,⽹络接⼝层主要为⽹络层提供「链路级别」传输的服务,负责在以太⽹、WiFi 这样的底层⽹络上
发送原始数据包,⼯作在⽹卡这个层次,使⽤ MAC 地址来标识⽹络上的设备。
键⼊⽹址到⽹⻚显示,期间发⽣了什么?
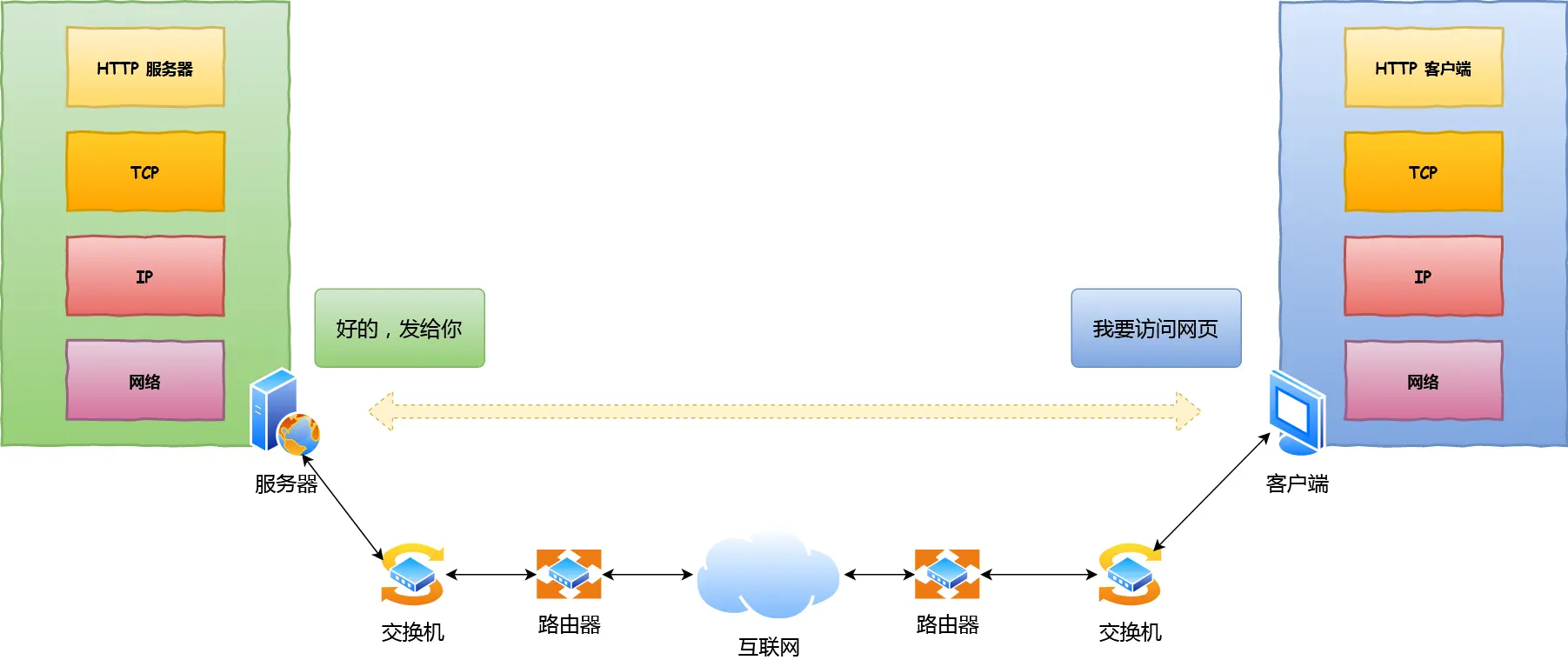
数据包抵达服务器后,服务器会先扒开数据包的 MAC 头部,查看是否和服务器⾃⼰的 MAC 地址符合,符
合就将包收起来。
接着继续扒开数据包的 IP 头,发现 IP 地址符合,根据 IP 头中协议项,知道⾃⼰上层是 TCP 协议。
于是,扒开 TCP 的头,⾥⾯有序列号,需要看⼀看这个序列包是不是我想要的,如果是就放⼊缓存中然后
返回⼀个 ACK,如果不是就丢弃。TCP 头部⾥⾯还有端⼝号, HTTP 的服务器正在监听这个端⼝号。
于是,服务器⾃然就知道是 HTTP 进程想要这个包,于是就将包发给 HTTP 进程。服务器的 HTTP 进程看到,原来这个请求是要访问⼀个⻚⾯,于是就把这个⽹⻚封装在 HTTP 响应报⽂
⾥。
HTTP 响应报⽂也需要穿上 TCP、IP、MAC 头部,不过这次是源地址是服务器 IP 地址,⽬的地址是客户
端 IP 地址。
穿好头部⾐服后,从⽹卡出去,交由交换机转发到出城的路由器,路由器就把响应数据包发到了下⼀个路
由器,就这样跳啊跳。
最后跳到了客户端的城⻔把守的路由器,路由器扒开 IP 头部发现是要找城内的⼈,于是⼜把包发给了城内
的交换机,再由交换机转发到客户端。
客户端收到了服务器的响应数据包后,同样也⾮常的⾼兴,客户能拆快递了!
于是,客户端开始扒⽪,把收到的数据包的⽪扒剩 HTTP 响应报⽂后,交给浏览器去渲染⻚⾯,⼀份特别
的数据包快递,就这样显示出来了!
最后,客户端要离开了,向服务器发起了 TCP 四次挥⼿,⾄此双⽅的连接就断开了。
5.浏览器如何解析URL的
⾸先浏览器做的第⼀步⼯作就是要对 URL 进⾏解析,从⽽⽣成发送给 Web 服务器的请求信息。
让我们看看⼀条⻓⻓的 URL ⾥的各个元素的代表什么,⻅下图:
6.要是url中的路径名都省略了,那应该是请求哪个⽂件呢?
当没有路径名时,就代表访问根⽬录下事先设置的默认⽂件,也就是 /index.html 或者 /default.html 这
些⽂件,这样就不会发⽣混乱了。
7.如何生产HTTP请求信息
URL 进⾏解析之后,浏览器确定了 Web 服务器和⽂件名,接下来就是根据这些信息来⽣成 HTTP 请求消息了。
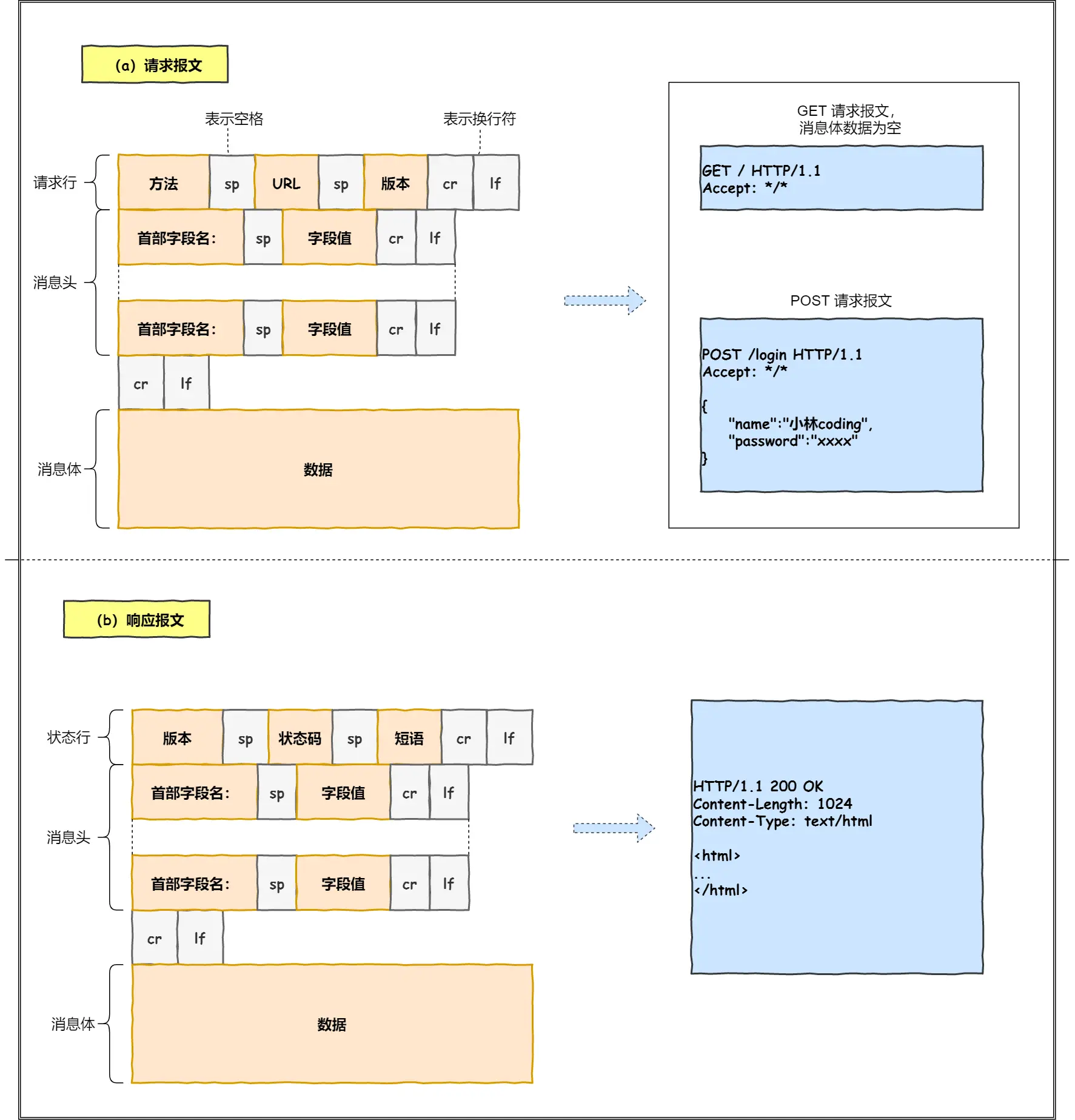
8.如何通过DNS查询真实地址
通过浏览器解析 URL 并⽣成 HTTP 消息后,需要委托操作系统将消息发送给 Web 服务器。
但在发送之前,还有⼀项⼯作需要完成,那就是查询服务器域名对应的 IP 地址,因为委托操作系统发送消
息时,必须提供通信对象的 IP 地址。
⽐如我们打电话的时候,必须要知道对⽅的电话号码,但由于电话号码难以记忆,所以通常我们会将对⽅
电话号 + 姓名保存在通讯录⾥。
所以,有⼀种服务器就专⻔保存了 Web 服务器域名与 IP 的对应关系,它就是 DNS 服务器。
9.域名的层级关系是怎样的
DNS 中的域名都是⽤句点来分隔的,⽐如 www.server.com ,这⾥的句点代表了不同层次之间的界限。
在域名中,越靠右的位置表示其层级越⾼。
毕竟域名是外国⼈发明,所以思维和中国⼈相反,⽐如说⼀个城市地点的时候,外国喜欢从⼩到⼤的⽅式
顺序说起(如 XX 街道 XX 区 XX 市 XX 省),⽽中国则喜欢从⼤到⼩的顺序(如 XX 省 XX 市 XX 区 XX 街
道)。
实际上域名最后还有⼀个点,⽐如 www.server.com. ,这个最后的⼀个点代表根域名。
也就是, . 根域是在最顶层,它的下⼀层就是 .com 顶级域,再下⾯是 server.com 。
所以域名的层级关系类似⼀个树状结构:
-
根 DNS 服务器(.)
-
顶级域 DNS 服务器(.com)
-
权威 DNS 服务器(server.com)
-
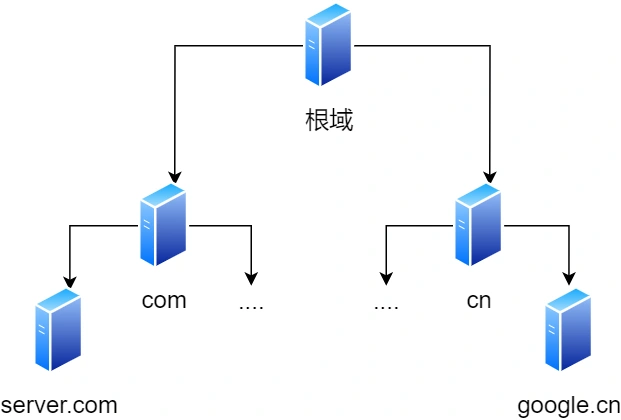
根域的 DNS 服务器信息保存在互联⽹中所有的 DNS 服务器中。
这样⼀来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。
因此,客户端只要能够找到任意⼀台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再⼀路顺藤
摸⽠找到位于下层的某台⽬标 DNS 服务器
10.域名解析的⼯作流程是怎样的
- 客户端⾸先会发出⼀个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就
是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存⾥的表格能找到 www.server.com,则它直接返回 IP
地址。如果没有,本地 DNS 会去问它的根域名服务器:“⽼⼤, 能告诉我 www.server.com 的 IP 地
址吗?” 根域名服务器是最⾼层次的,它不直接⽤于域名解析,但能指明⼀条道路。
- 根 DNS 收到来⾃本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com
区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。”
- 本地 DNS 收到顶级域名服务器的地址后,发起请求问“⽼⼆, 你能告诉我 www.server.com 的 IP 地
址吗?”
- 顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能
问到”。
- 本地 DNS 于是转向问权威 DNS 服务器:“⽼三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和⽬标建⽴连接。
⾄此,我们完成了 DNS 的解析过程。现在总结⼀下,整个过程我画成了⼀个图。
DNS 域名解析的过程蛮有意思的,整个过程就和我们⽇常⽣活中找⼈问路的过程类似,只指路不带路。
那是不是每次解析域名都要经过那么多的步骤呢?当然不是了,还有缓存这个东⻄的嘛。
浏览器会先看⾃身有没有对这个域名的缓存,如果有,就直接返回,如果没有,就去问操作系统,操作系
统也会去看⾃⼰的缓存,如果有,就直接返回,如果没有,再去 hosts ⽂件看,也没有,才会去问「本地
DNS 服务器」。
11.协议栈是什么,如何工作的
通过 DNS 获取到 IP 后,就可以把 HTTP 的传输⼯作交给操作系统中的协议栈。
协议栈的内部分为⼏个部分,分别承担不同的⼯作。上下关系是有⼀定的规则的,上⾯的部分会向下⾯的
部分委托⼯作,下⾯的部分收到委托的⼯作并执⾏。
应⽤程序(浏览器)通过调⽤ Socket 库,来委托协议栈⼯作。协议栈的上半部分有两块,分别是负责收发
数据的 TCP 和 UDP 协议,这两个传输协议会接受应⽤层的委托执⾏收发数据的操作。
协议栈的下⾯⼀半是⽤ IP 协议控制⽹络包收发操作,在互联⽹上传数据时,数据会被切分成⼀块块的⽹络
包,⽽将⽹络包发送给对⽅的操作就是由 IP 负责的。
此外 IP 中还包括 ICMP 协议和 ARP 协议。
-
ICMP ⽤于告知⽹络包传送过程中产⽣的错误以及各种控制信息。
-
ARP ⽤于根据 IP 地址查询相应的以太⽹ MAC 地址。
IP 下⾯的⽹卡驱动程序负责控制⽹卡硬件,⽽最下⾯的⽹卡则负责完成实际的收发操作,也就是对⽹线中
的信号执⾏发送和接收操作。
12.介绍一下TCP报文头部
HTTP 是基于 TCP 协议传输的,所以在这我们先了解下 TCP 协议。
我们先看看 TCP 报⽂头部的格式
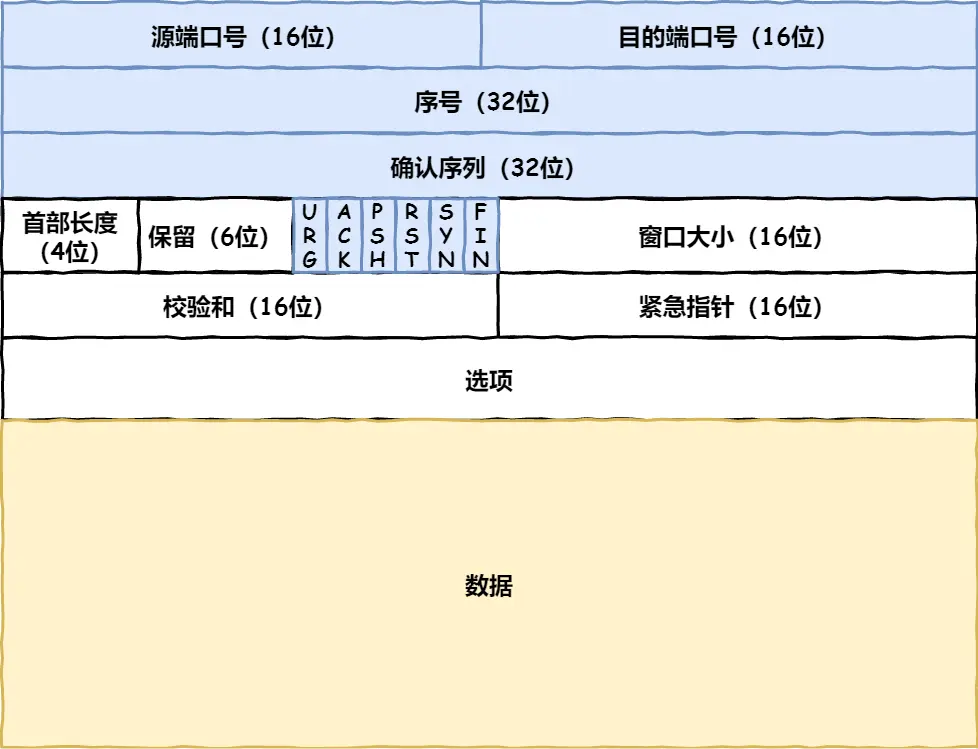
⾸先,源端⼝号和⽬标端⼝号是不可少的,如果没有这两个端⼝号,数据就不知道应该发给哪个应⽤。
接下来有包的序号,这个是为了解决包乱序的问题。
还有应该有的是确认号,⽬的是确认发出去对⽅是否有收到。如果没有收到就应该᯿新发送,直到送达,
这个是为了解决丢包的问题。
接下来还有⼀些状态位。例如 SYN 是发起⼀个连接, ACK 是回复, RST 是᯿新连接, FIN 是结束
连接等。TCP 是⾯向连接的,因⽽双⽅要维护连接的状态,这些带状态位的包的发送,会引起双⽅的状态
变更。
还有⼀个᯿要的就是窗⼝⼤⼩。TCP 要做流量控制,通信双⽅各声明⼀个窗⼝(缓存⼤⼩),标识⾃⼰当
前能够的处理能⼒,别发送的太快,撑死我,也别发的太慢,饿死我。
除了做流ᰁ控制以外,TCP还会做拥塞控制,对于真正的通路堵⻋不堵⻋,它⽆能为⼒,唯⼀能做的就是
控制⾃⼰,也即控制发送的速度。不能改变世界,就改变⾃⼰嘛。
13.三次握手是什么,目的是什么
TCP 传输数据之前,要先三次握⼿建⽴连接
在 HTTP 传输数据之前,⾸先需要 TCP 建⽴连接,TCP 连接的建⽴,通常称为三次握⼿。
这个所谓的「连接」,只是双⽅计算机⾥维护⼀个状态机,在连接建⽴的过程中,双⽅的状态变化时序图
就像这样。
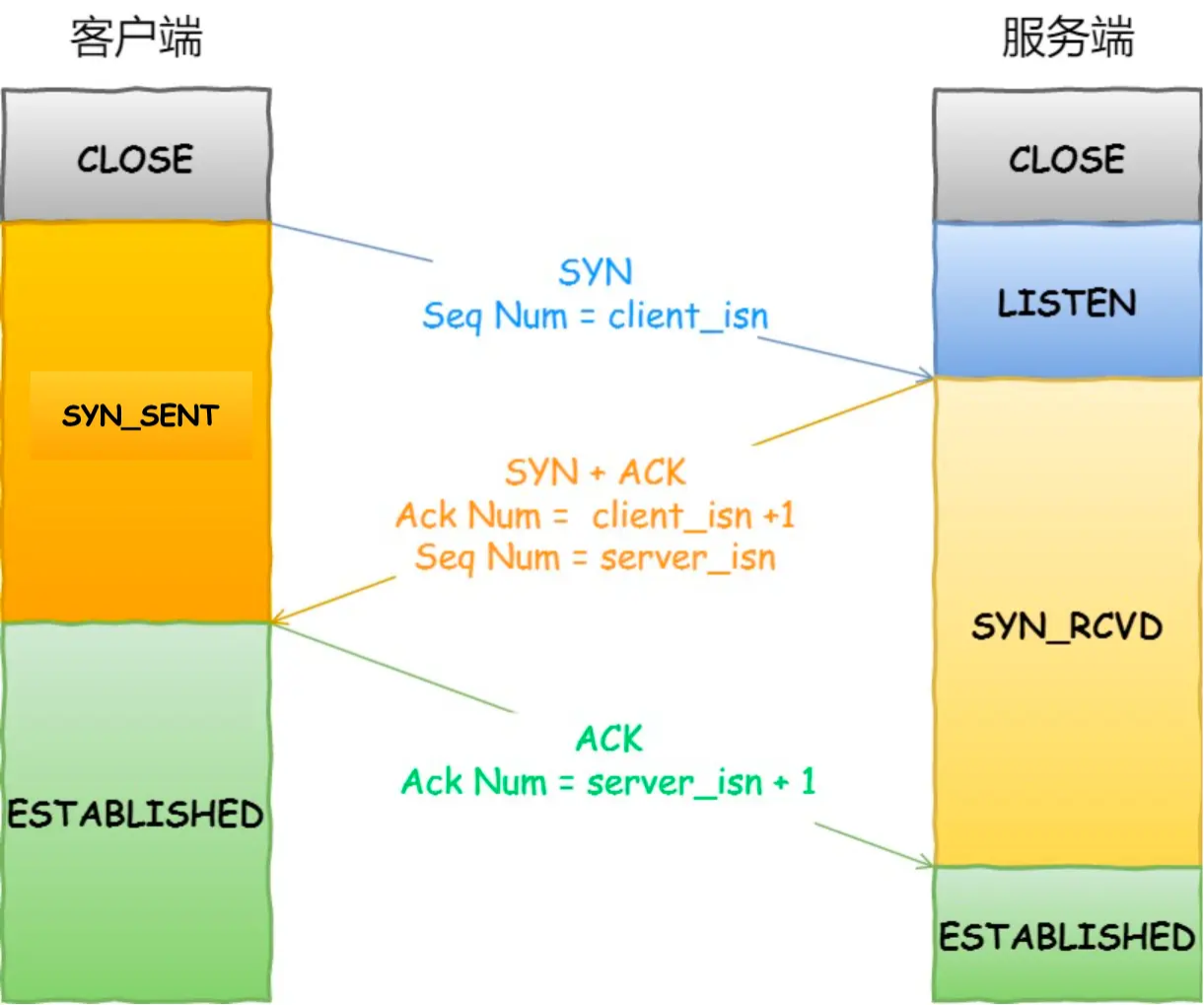
- ⼀开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端⼝,处于 LISTEN 状
态。
-
然后客户端主动发起连接 SYN ,之后处于 SYN-SENT 状态。
-
服务端收到发起的连接,返回 SYN ,并且 ACK 客户端的 SYN ,之后处于 SYN-RCVD 状态。
-
客户端收到服务端发送的 SYN 和 ACK 之后,发送对 SYN 确认的 ACK ,之后处于
ESTABLISHED 状态,因为它⼀发⼀收成功了。
- 服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也⼀发⼀收了。
所以三次握⼿⽬的是保证双⽅都有发送和接收的能⼒。
14.如何查看 TCP 的连接状态?
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。

15.TCP 为什么分割数据
如果 HTTP 请求消息⽐较⻓,超过了 MSS 的⻓度,这时 TCP 就需要把 HTTP 的数据拆解成⼀块块的数
据发送,⽽不是⼀次性发送所有数据。
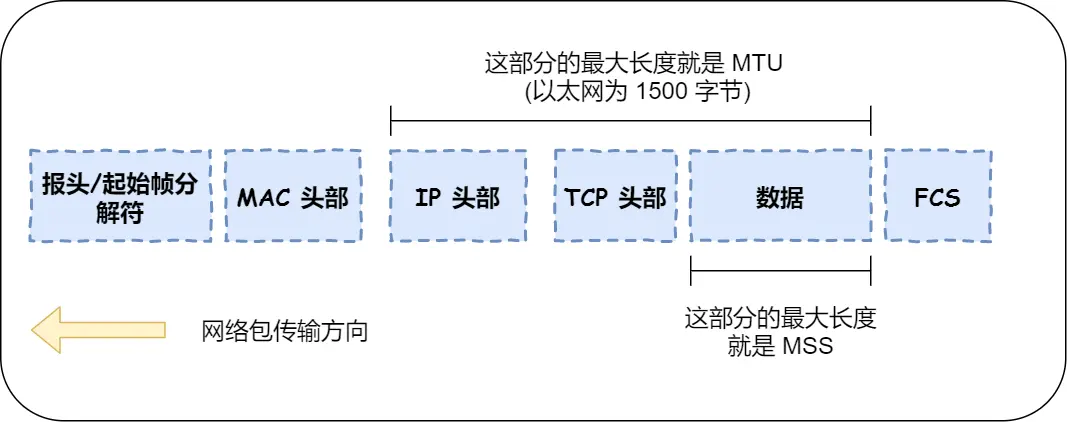
-
MTU :⼀个⽹络包的最⼤⻓度,以太⽹中⼀般为 1500 字节。
-
MSS :除去 IP 和 TCP 头部之后,⼀个⽹络包所能容纳的 TCP 数据的最⼤⻓度。
数据会被以 MSS 的⻓度为单位进⾏拆分,拆分出来的每⼀块数据都会被放进单独的⽹络包中。也就是在
每个被拆分的数据加上 TCP 头信息,然后交给 IP 模块来发送数据。
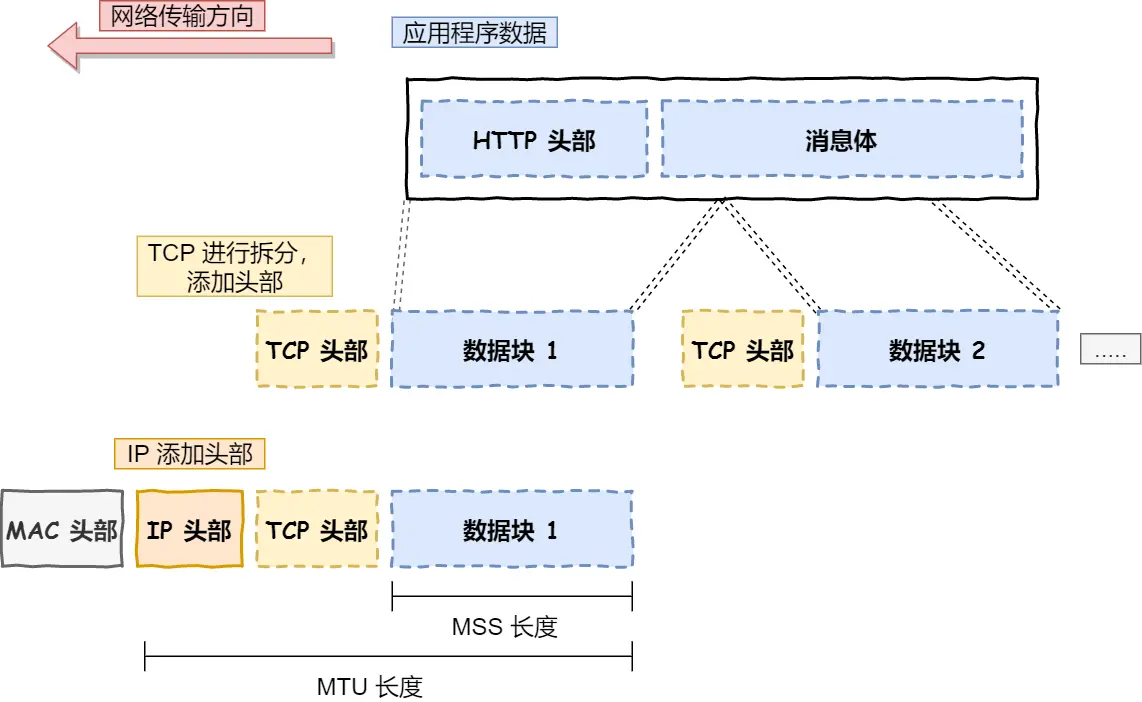
16.TCP报文如何生成的
TCP 协议⾥⾯会有两个端⼝,⼀个是浏览器监听的端⼝(通常是随机⽣成的),⼀个是 Web 服务器监听
的端⼝(HTTP 默认端⼝号是 80 , HTTPS 默认端⼝号是 443 )。
在双⽅建⽴了连接后,TCP 报⽂中的数据部分就是存放 HTTP 头部 + 数据,组装好 TCP 报⽂之后,就需
交给下⾯的⽹络层处理。
⾄此,⽹络包的报⽂如下图。
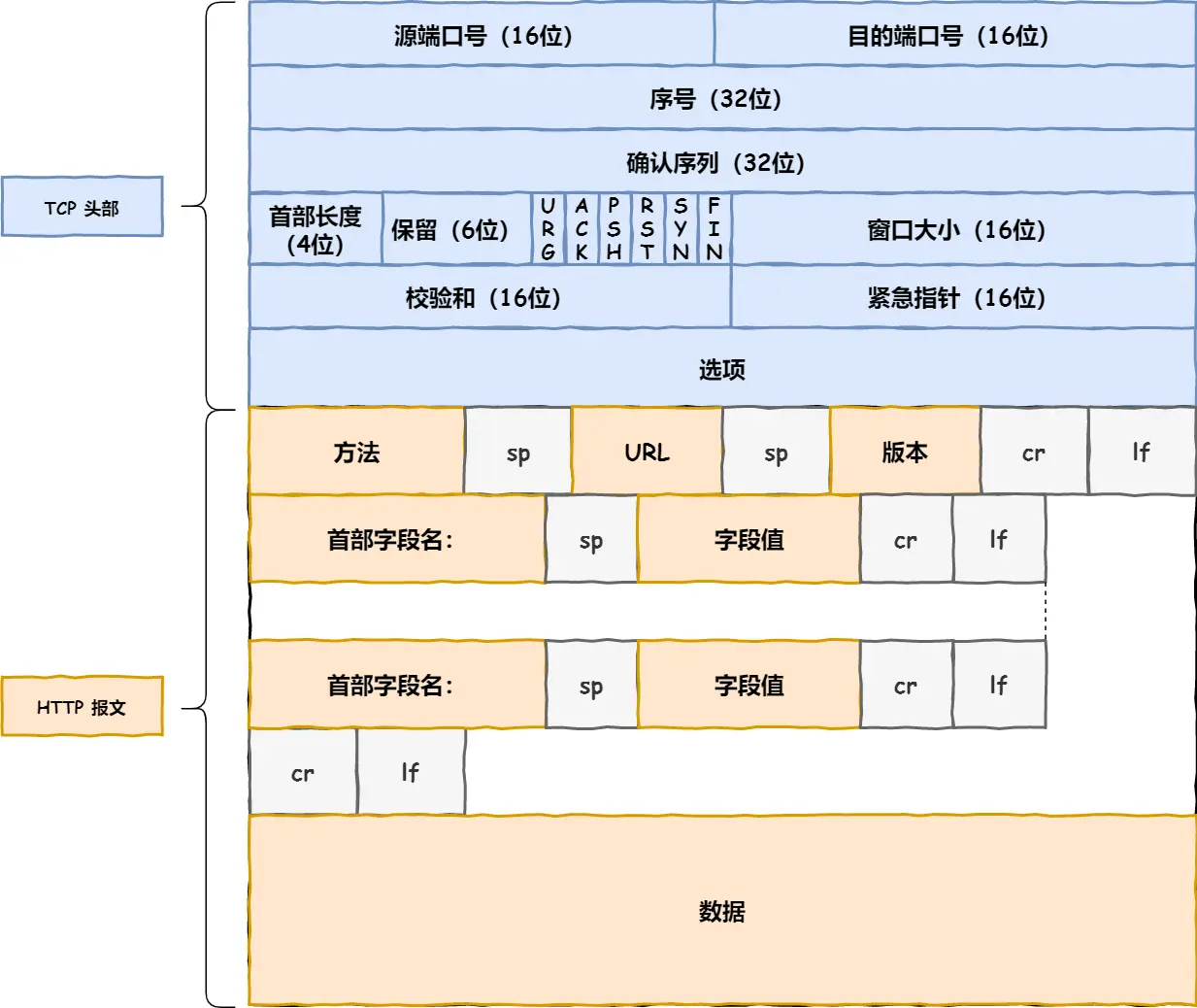
17.介绍一下IP包头格式
TCP 模块在执⾏连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成⽹络包发送给通信对
象。
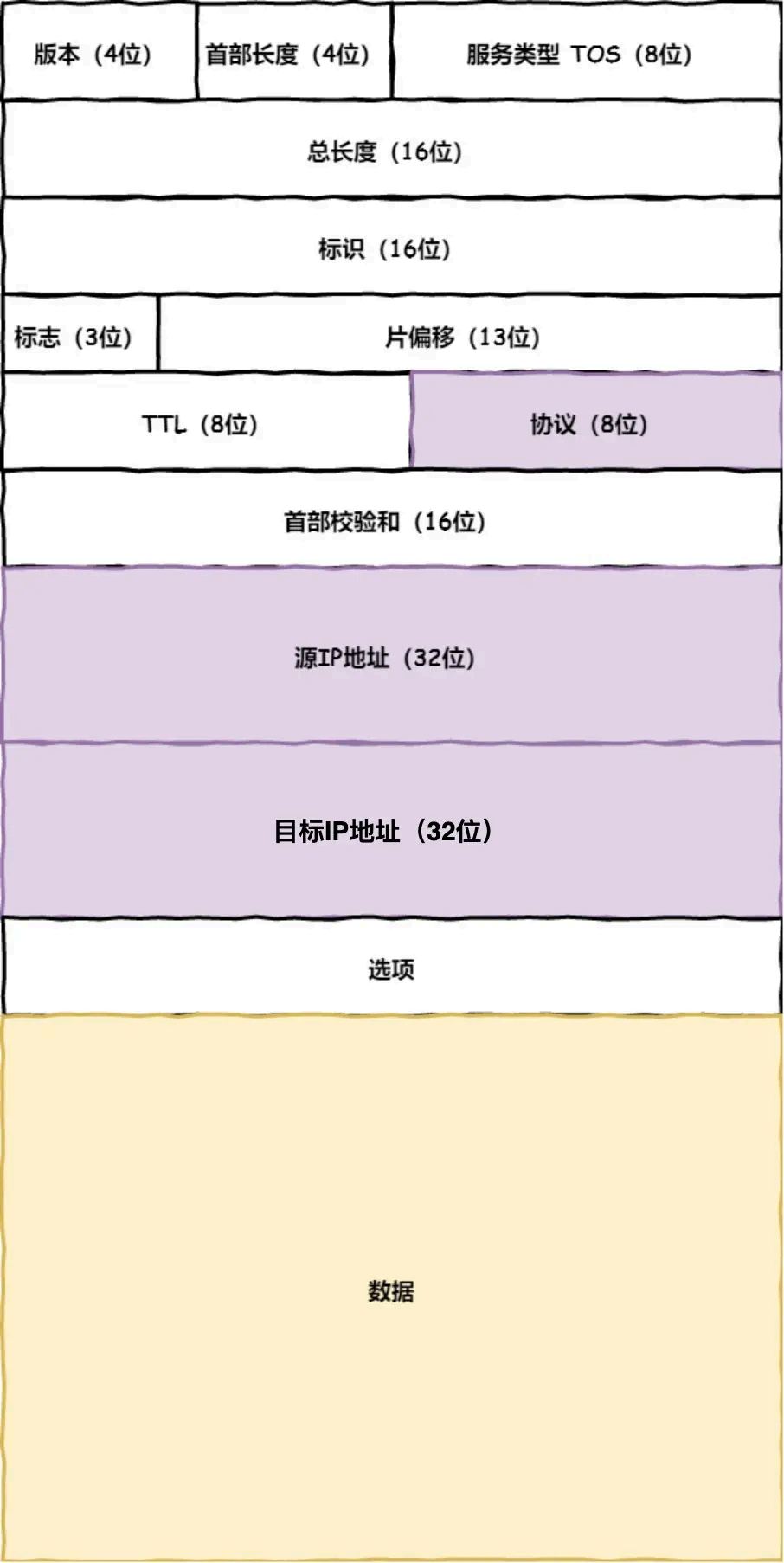
在 IP 协议⾥⾯需要有源地址 IP 和 ⽬标地址 IP:
-
源地址IP,即是客户端输出的 IP 地址;
-
⽬标地址,即通过 DNS 域名解析得到的 Web 服务器 IP。
因为 HTTP 是经过 TCP 传输的,所以在 IP 包头的协议号,要填写为 06 (⼗六进制),表示协议为
TCP。
18.假设客户端有多个⽹卡,就会有多个 IP 地址,那 IP 头部的源地址应该选择哪个 IP 呢?
当存在多个⽹卡时,在填写源地址 IP 时,就需要判断到底应该填写哪个地址。这个判断相当于在多块⽹卡
中判断应该使⽤哪个⼀块⽹卡来发送包。
这个时候就需要根据路由表规则,来判断哪⼀个⽹卡作为源地址 IP。
在 Linux 操作系统,我们可以使⽤ route -n 命令查看当前系统的路由表
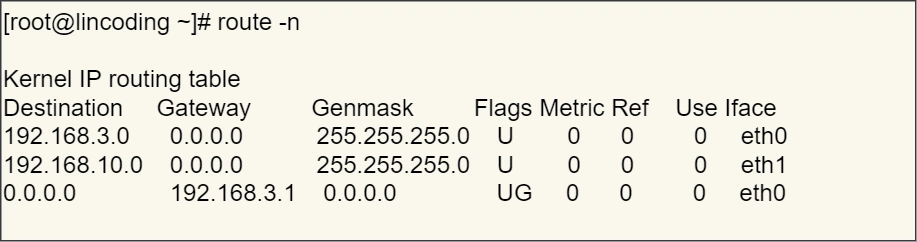
举个例⼦,根据上⾯的路由表,我们假设 Web 服务器的⽬标地址是 192.168.10.200 。
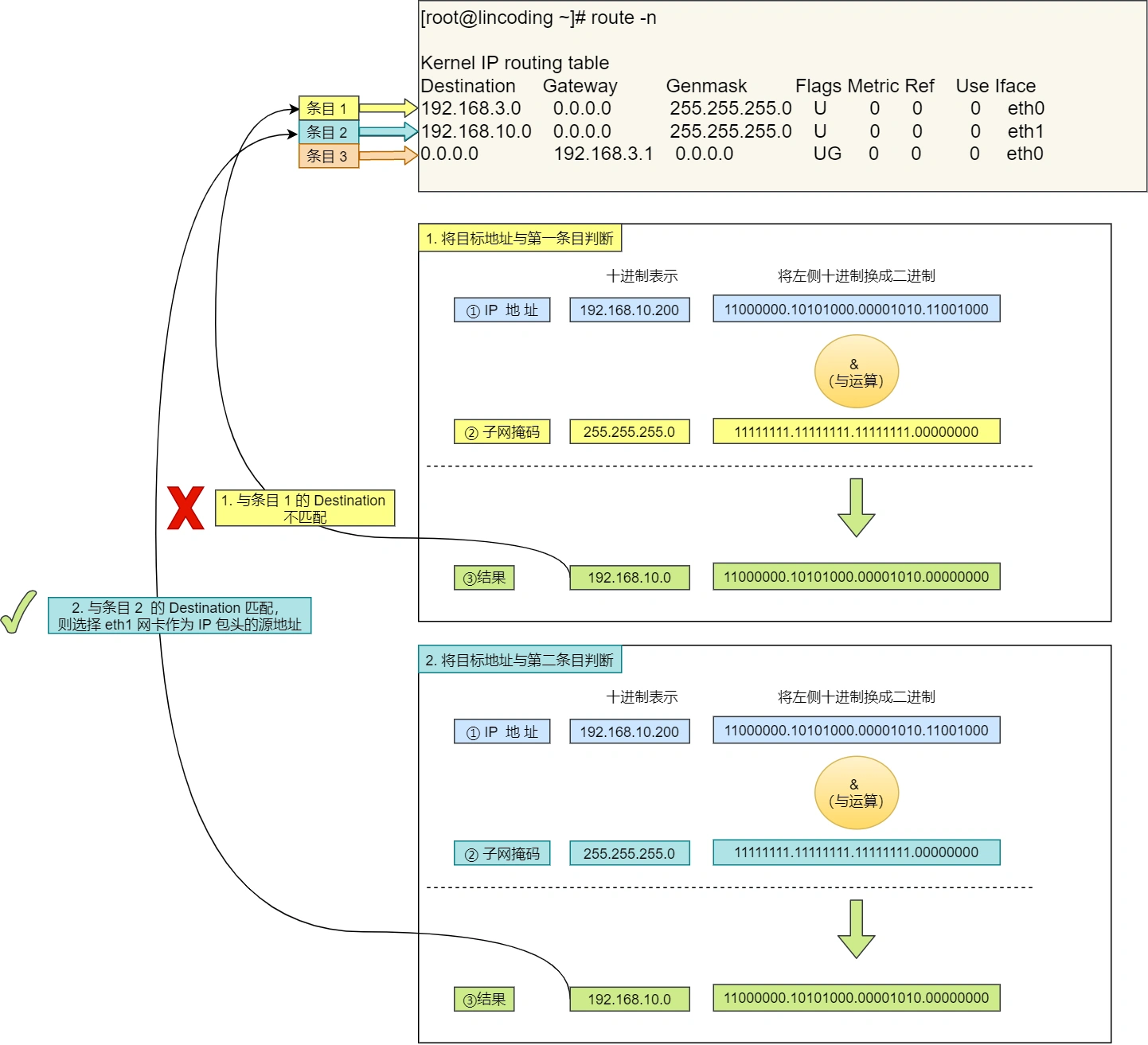
⾸先先和第⼀条⽬的⼦⽹掩码( Genmask )进⾏ 与运算,得到结果为 192.168.10.0 ,但是第⼀个
条⽬的 Destination 是 192.168.3.0 ,两者不⼀致所以匹配失败。
- 再与第⼆条⽬的⼦⽹掩码进⾏ 与运算,得到的结果为 192.168.10.0 ,与第⼆条⽬的 Destination192.168.10.0 匹配成功,所以将使⽤ eth1 ⽹卡的 IP 地址作为 IP 包头的源地址。
那么假设 Web 服务器的⽬标地址是 10.100.20.100 ,那么依然依照上⾯的路由表规则判断,判断后的结
果是和第三条⽬匹配。
第三条⽬⽐较特殊,它⽬标地址和⼦⽹掩码都是 0.0.0.0 ,这表示默认⽹关,如果其他所有条⽬都⽆法匹
配,就会⾃动匹配这⼀⾏。并且后续就把包发给路由器, Gateway 即是路由器的 IP 地址。
19.IP报文如何生成的
⾄此,⽹络包的报⽂如下图
此时,加上了 IP 头部的数据包表示 :“有 IP ⼤佬给我指路了,感谢 IP 层给我加上了 IP 包头,让我有了远程
定位的能⼒!不会害怕在浩瀚的互联⽹迷茫了!可是⽬的地好远啊,我下⼀站应该去哪呢?”
20.介绍一下MAC包头格式
MAC 头部是以太⽹使⽤的头部,它包含了接收⽅和发送⽅的 MAC 地址等信息。
在 MAC 包头⾥需要发送⽅ MAC 地址和接收⽅⽬标 MAC 地址,⽤于两点之间的传输。
⼀般在 TCP/IP 通信⾥,MAC 包头的协议类型只使⽤:
0800 : IP 协议
0806 : ARP 协议
21.MAC 发送⽅和接收⽅如何确认?
发送⽅的 MAC 地址获取就⽐较简单了,MAC 地址是在⽹卡⽣产时写⼊到 ROM ⾥的,只要将这个值读取
出来写⼊到 MAC 头部就可以了。
接收⽅的 MAC 地址就有点复杂了,只要告诉以太⽹对⽅的 MAC 的地址,以太⽹就会帮我们把包发送过
去,那么很显然这⾥应该填写对⽅的 MAC 地址。
所以先得搞清楚应该把包发给谁,这个只要查⼀下路由表就知道了。在路由表中找到相匹配的条⽬,然后
把包发给 Gateway 列中的 IP 地址就可以了。
此时就需要 ARP 协议帮我们找到路由器的 MAC 地址
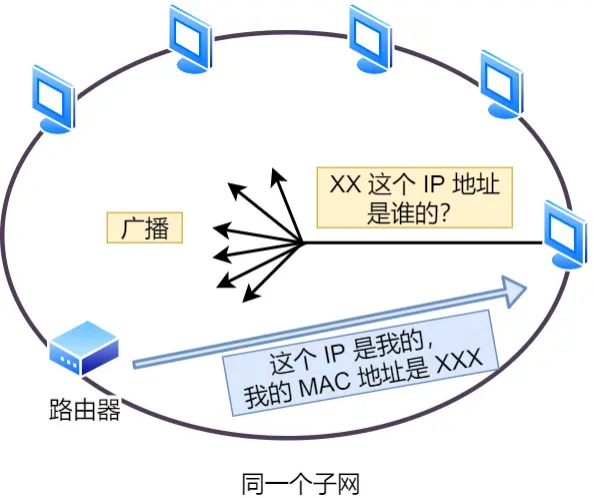
ARP 协议会在以太⽹中以⼴播的形式,对以太⽹所有的设备喊出:“这个 IP 地址是谁的?请把你的 MAC
地址告诉我。然后就会有⼈回答:“这个 IP 地址是我的,我的 MAC 地址是 XXXX”。
如果对⽅和⾃⼰处于同⼀个⼦⽹中,那么通过上⾯的操作就可以得到对⽅的 MAC 地址。然后,我们将这
个 MAC 地址写⼊ MAC 头部,MAC 头部就完成了
在后续操作系统会把本次查询结果放到⼀块叫做 ARP 缓存的内存空间留着以后⽤,不过缓存的时间
就⼏分钟
也就是说,在发包时:
- 先查询 ARP 缓存,如果其中已经保存了对⽅的 MAC 地址,就不需要发送 ARP 查询,直接使⽤ ARP
缓存中的地址。
- ⽽当 ARP 缓存中不存在对⽅ MAC 地址时,则发送 ARP ⼴播查询
22.如何查看 ARP 缓存内容
在 Linux 系统中,我们可以使⽤ arp -a 命令来查看 ARP 缓存的内容
23.MAC报文如何生成的
此时,加上了 MAC 头部的数据包万分感谢,说道 :“感谢 MAC ⼤佬,我知道我下⼀步要去哪了!我现在有
很多头部兄弟,相信我可以到达最终的⽬的地!”。
带着众多头部兄弟的数据包,终于准备要出⻔了。
24.网卡的作用是什么
⽹络包只是存放在内存中的⼀串⼆进制数字信息,没有办法直接发送给对⽅。因此,我们需要将数字信息
转换为电信号,才能在⽹线上传输,也就是说,这才是真正的数据发送过程。
负责执⾏这⼀操作的是⽹卡,要控制⽹卡还需要靠⽹卡驱动程序。
⽹卡驱动获取⽹络包之后,会将其复制到⽹卡内的缓存区中,接着会在其开头加上报头和起始帧分界符,
在末尾加上⽤于检测错误的帧校验序列
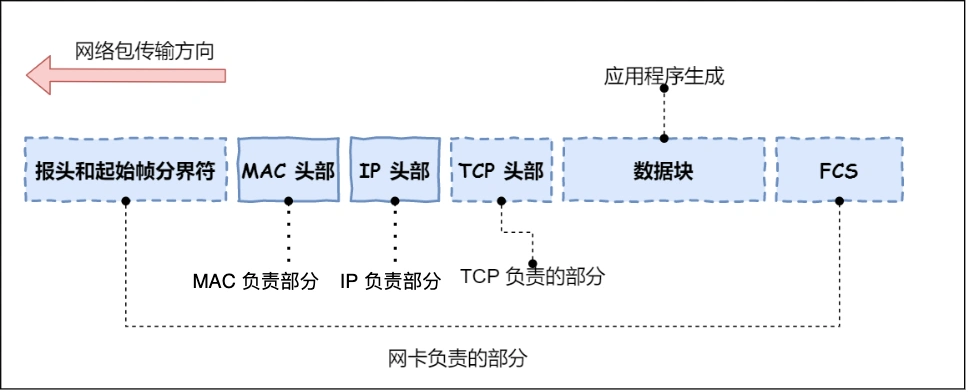
-
起始帧分界符是⼀个⽤来表示包起始位置的标记
-
末尾的 FCS (帧校验序列)⽤来检查包传输过程是否有损坏
最后⽹卡会将包转为电信号,通过⽹线发送出去。
唉,真是不容易,发⼀个包,真是历经千⾟万苦。致此,⼀个带有许多头部的数据终于踏上寻找⽬的地的征
途了
25.交换机的包接受操作是什么
⾸先,电信号到达⽹线接⼝,交换机⾥的模块进⾏接收,接下来交换机⾥的模块将电信号转换为数字信
号。
然后通过包末尾的 FCS 校验错误,如果没问题则放到缓冲区。这部分操作基本和计算机的⽹卡相同,但
交换机的⼯作⽅式和⽹卡不同。
计算机的⽹卡本身具有 MAC 地址,并通过核对收到的包的接收⽅ MAC 地址判断是不是发给⾃⼰的,如果
不是发给⾃⼰的则丢弃;相对地,交换机的端⼝不核对接收⽅ MAC 地址,⽽是直接接收所有的包并存放
**到缓冲区中。**因此,和⽹卡不同,交换机的端⼝不具有 MAC 地址。
将包存⼊缓冲区后,接下来需要查询⼀下这个包的接收⽅ MAC 地址是否已经在 MAC 地址表中有记录了。
交换机的 MAC 地址表主要包含两个信息:
-
⼀个是设备的 MAC 地址,
-
另⼀个是该设备连接在交换机的哪个端⼝上。
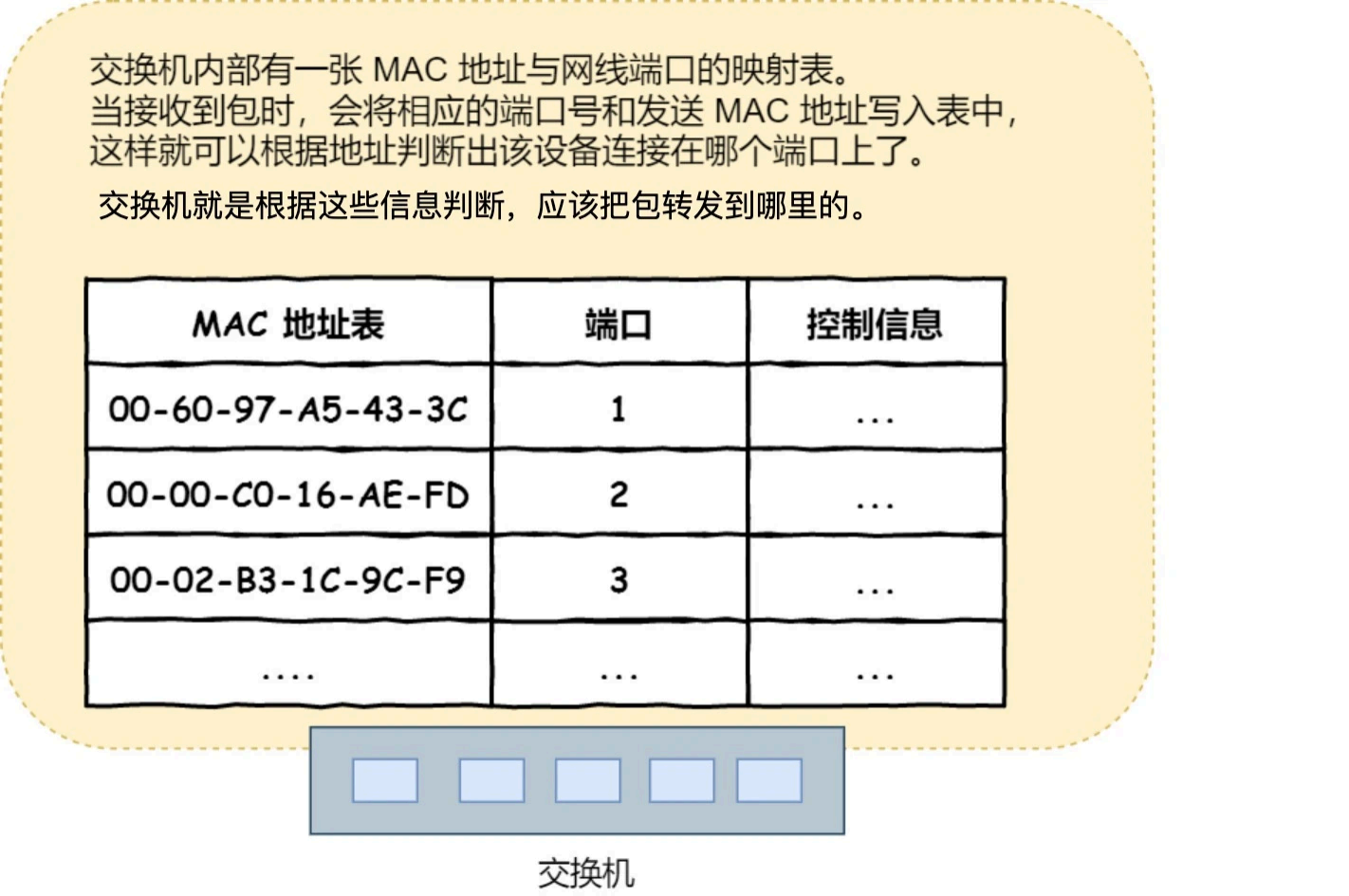
举个例⼦,如果收到的包的接收⽅ MAC 地址为 00-02-B3-1C-9C-F9 ,则与图中表中的第 3 ⾏匹配,根
据端⼝列的信息,可知这个地址位于 3 号端⼝上,然后就可以通过交换电路将包发送到相应的端⼝了。
所以,交换机根据 MAC 地址表查找 MAC 地址,然后将信号发送到相应的端⼝
26.当 MAC 地址表找不到指定的 MAC 地址会怎么样?
地址表中找不到指定的 MAC 地址。这可能是因为具有该地址的设备还没有向交换机发送过包,或者这个
设备⼀段时间没有⼯作导致地址被从地址表中删除了。
这种情况下,交换机⽆法判断应该把包转发到哪个端⼝,只能将包转发到除了源端⼝之外的所有端⼝上,
⽆论该设备连接在哪个端⼝上都能收到这个包。
这样做不会产⽣什么问题,因为以太⽹的设计本来就是将包发送到整个⽹络的,然后只有相应的接收者才
接收包,⽽其他设备则会忽略这个包。
有⼈会说:“这样做会发送多余的包,会不会造成⽹络拥塞呢?”
其实完全不⽤过于担⼼,因为发送了包之后⽬标设备会作出响应,只要返回了响应包,交换机就可以将它
**的地址写⼊ MAC 地址表,**下次也就不需要把包发到所有端⼝了。
局域⽹中每秒可以传输上千个包,多出⼀两个包并⽆⼤碍。
此外,如果接收⽅ MAC 地址是⼀个⼴播地址,那么交换机会将包发送到除源端⼝之外的所有端⼝。
以下两个属于⼴播地址:
-
MAC 地址中的 FF:FF:FF:FF:FF:FF
-
IP 地址中的 255.255.255.255
27.路由器与交换机的区别是什么
⽹络包经过交换机之后,现在到达了路由器,并在此被转发到下⼀个路由器或⽬标设备。
这⼀步转发的⼯作原理和交换机类似,也是通过查表判断包转发的⽬标。
不过在具体的操作过程上,路由器和交换机是有区别的。
因为路由器是基于 IP 设计的,俗称三层⽹络设备,路由器的各个端⼝都具有 MAC 地址和 IP 地址;
⽽交换机是基于以太⽹设计的,俗称⼆层⽹络设备,交换机的端⼝不具有 MAC 地址。
28.路由器基本原理是什么
路由器的端⼝具有 MAC 地址,因此它就能够成为以太⽹的发送⽅和接收⽅;同时还具有 IP 地址,从这个
意义上来说,它和计算机的⽹卡是⼀样的。
当转发包时,⾸先路由器端⼝会接收发给⾃⼰的以太⽹包,然后路由表查询转发⽬标,再由相应的端⼝作
为发送⽅将以太⽹包发送出去。
29.路由器的包接收操作是什么
⾸先,电信号到达⽹线接⼝部分,路由器中的模块会将电信号转成数字信号,然后通过包末尾的 FCS 进
⾏错误校验。
如果没问题则检查 MAC 头部中的接收⽅ MAC 地址,看看是不是发给⾃⼰的包,如果是就放到接收缓冲区
中,否则就丢弃这个包。
总的来说,路由器的端⼝都具有 MAC 地址,只接收与⾃身地址匹配的包,遇到不匹配的包则直接丢弃。
30.路由器如何查询路由表确定输出端口
完成包接收操作之后,路由器就会去掉包开头的 MAC 头部。
MAC 头部的作⽤就是将包送达路由器,其中的接收⽅ MAC 地址就是路由器端⼝的 MAC 地址。因此,当
包到达路由器之后,MAC 头部的任务就完成了,于是 MAC 头部就会被丢弃。
接下来,路由器会根据 MAC 头部后⽅的 IP 头部中的内容进⾏包的转发操作。
转发操作分为⼏个阶段,⾸先是查询路由表判断转发⽬标。
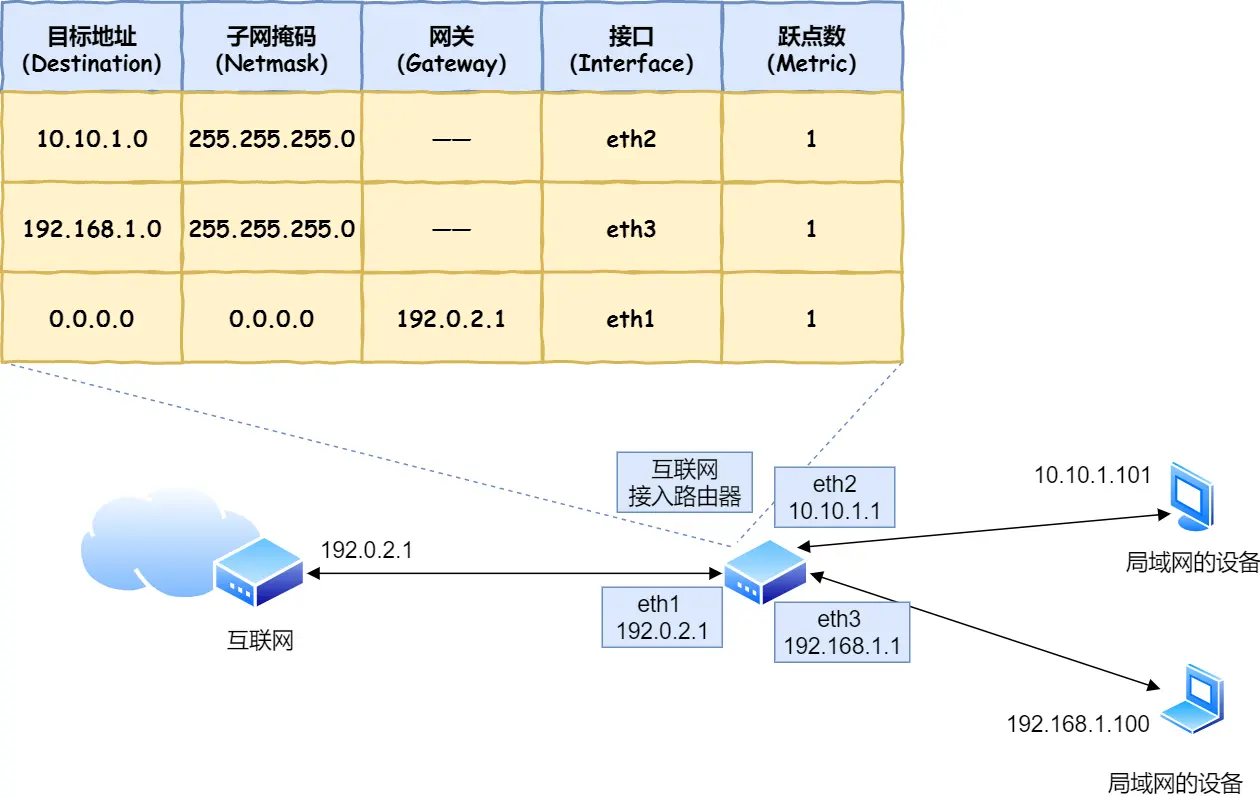
具体的⼯作流程根据上图,举个例⼦。假设地址为 10.10.1.101 的计算机要向地址为 192.168.1.100 的服务器发送⼀个包,这个包先到达图中
的路由器。
判断转发⽬标的第⼀步,就是根据包的接收⽅ IP 地址查询路由表中的⽬标地址栏,以找到相匹配的记录。
路由匹配和前⾯讲的⼀样,每个条⽬的⼦⽹掩码和 192.168.1.100 IP 做 & 与运算后,得到的结果与对应
条⽬的⽬标地址进⾏匹配,如果匹配就会作为候选转发⽬标,如果不匹配就继续与下个条⽬进⾏路由匹
配。
如第⼆条⽬的⼦⽹掩码 255.255.255.0 与 192.168.1.100 IP 做 & 与运算后,得到结果是 192.168.1.0
,这与第⼆条⽬的⽬标地址 192.168.1.0 匹配,该第⼆条⽬记录就会被作为转发⽬标。
实在找不到匹配路由时,就会选择默认路由,路由表中⼦⽹掩码为 0.0.0.0 的记录表示「默认路由」。
31.路由器的发送操作是什么
接下来就会进⼊包的发送操作。
⾸先,我们需要根据路由表的⽹关列判断对⽅的地址。
如果⽹关是⼀个 IP 地址,则这个IP 地址就是我们要转发到的⽬标地址,还未抵达终点,还需继续需
要路由器转发。
如果⽹关为空,则 IP 头部中的接收⽅ IP 地址就是要转发到的⽬标地址,也是就终于找到 IP 包头⾥的
⽬标地址了,说明已抵达终点。
知道对⽅的 IP 地址之后,接下来需要通过 ARP 协议根据 IP 地址查询 MAC 地址,并将查询的结果作为
接收⽅ MAC 地址。
路由器也有 ARP 缓存,因此⾸先会在 ARP 缓存中查询,如果找不到则发送 ARP 查询请求。
接下来是发送⽅ MAC 地址字段,这⾥填写输出端⼝的 MAC 地址。还有⼀个以太类型字段,填写 0800
(⼗六进制)表示 IP 协议。
⽹络包完成后,接下来会将其转换成电信号并通过端⼝发送出去。这⼀步的⼯作过程和计算机也是相同
的。
发送出去的⽹络包会通过交换机到达下⼀个路由器。由于接收⽅ MAC 地址就是下⼀个路由器的地址,所
以交换机会根据这⼀地址将包传输到下⼀个路由器。
接下来,下⼀个路由器会将包转发给再下⼀个路由器,经过层层转发之后,⽹络包就到达了最终的⽬的
地。
不知你发现了没有,在⽹络包传输的过程中,源 IP 和⽬标 IP 始终是不会变的,⼀直变化的是 MAC 地
址,因为需要 MAC 地址在以太⽹内进⾏两个设备之间的包传输。
Linux系统是如何收发网络包的
32.什么是七层OSI网络模型和四层TCP/IP网络模型
由于 OSI 模型实在太复杂,提出的也只是概念理论上的分层,并没有提供具体的实现⽅案。事实上,我们⽐较常⻅,也⽐较实⽤的是四层模型,即 TCP/IP ⽹络模型,Linux 系统正是按照这套⽹络模
型来实现⽹络协议栈的。
TCP/IP ⽹络模型共有 4 层,分别是应⽤层、传输层、⽹络层和⽹络接⼝层,每⼀层负责的职能如下:
-
应⽤层,负责向⽤户提供⼀组应⽤程序,⽐如 HTTP、DNS、FTP 等;
-
传输层,负责端到端的通信,⽐如 TCP、UDP 等;
-
⽹络层,负责⽹络包的封装、分⽚、路由、转发,⽐如 IP、ICMP 等;
-
⽹络接⼝层,负责⽹络包在物理⽹络中的传输,⽐如⽹络包的封帧、 MAC 寻址、差错检测,以及通
过⽹卡传输⽹络帧等;
TCP/IP ⽹络模型相⽐ OSI ⽹络模型简化了不少,也更加易记,它们之间的关系如下图
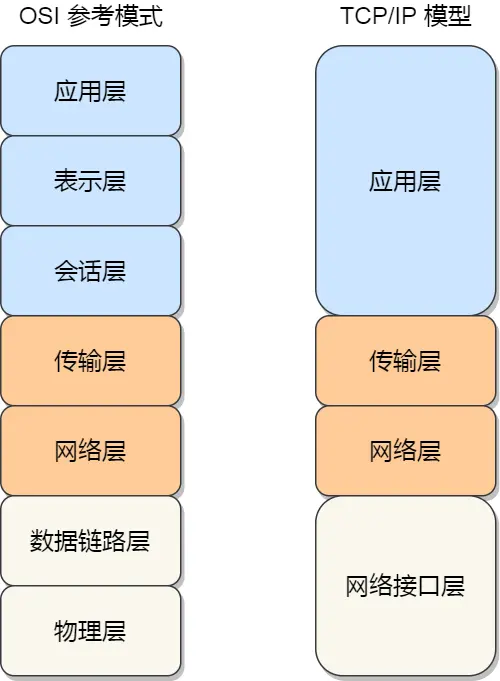
不过,我们常说的七层和四层负载均衡,是⽤ OSI ⽹络模型来描述的,七层对应的是应⽤层,四层对应的是传输层
33.什么是Linux网络协议栈
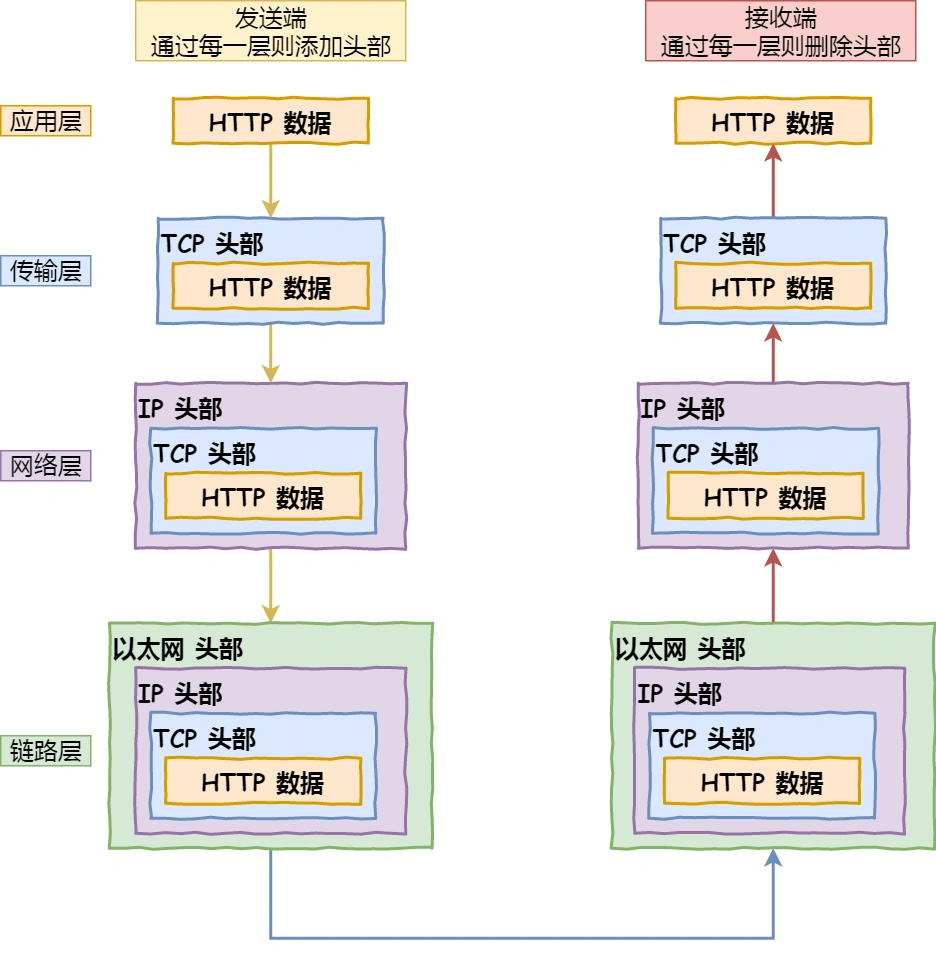
我们可以把⾃⼰的身体⽐作应⽤层中的数据,打底⾐服⽐作传输层中的 TCP 头,外套⽐作⽹络层中 IP
头,帽⼦和鞋⼦分别⽐作⽹络接⼝层的帧头和帧尾。在冬天这个季节,当我们要从家⾥出去玩的时候,⾃然要先穿个打底⾐服,再套上保暖外套,最后穿上帽
⼦和鞋⼦才出⻔,这个过程就好像我们把 TCP 协议通信的⽹络包发出去的时候,会把应⽤层的数据按照⽹
络协议栈层层封装和处理。
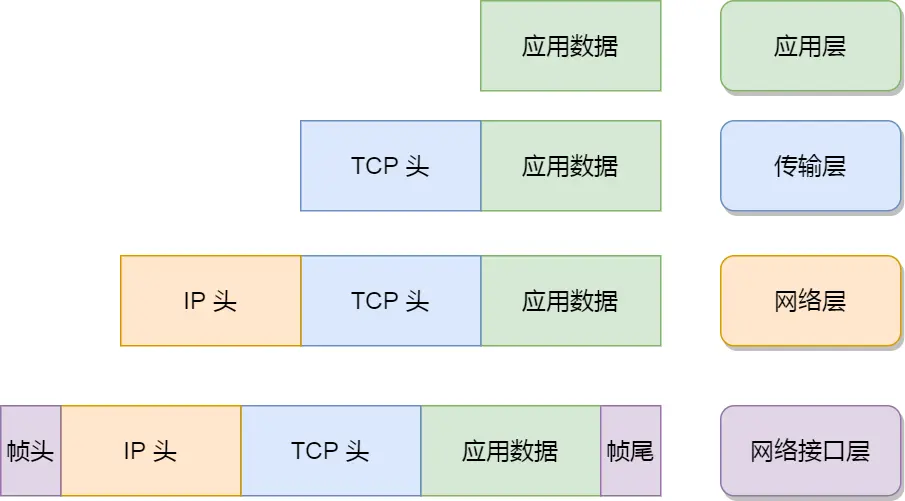
其中:
传输层,给应⽤数据前⾯增加了 TCP 头;
⽹络层,给 TCP 数据包前⾯增加了 IP 头;
⽹络接⼝层,给 IP 数据包前后分别增加了帧头和帧尾;
这些新增的头部和尾部,都有各⾃的作⽤,也都是按照特定的协议格式填充,这每⼀层都增加了各⾃的协
议头,那⾃然⽹络包的⼤⼩就增⼤了,但物理链路并不能传输任意⼤⼩的数据包,所以在以太⽹中,规定
了最⼤传输单元(MTU)是 1500 字节,也就是规定了单次传输的最⼤ IP 包⼤⼩。
当⽹络包超过 MTU 的⼤⼩,就会在⽹络层分⽚,以确保分⽚后的 IP 包不会超过 MTU ⼤⼩,如果 MTU 越
⼩,需要的分包就越多,那么⽹络吞吐能⼒就越差,相反的,如果 MTU 越⼤,需要的分包就越少,那么
⽹络吞吐能⼒就越好。
知道了 TCP/IP ⽹络模型,以及⽹络包的封装原理后,那么 Linux ⽹络协议栈的样⼦,你想必猜到了⼤概,
它其实就类似于 TCP/IP 的四层结构:
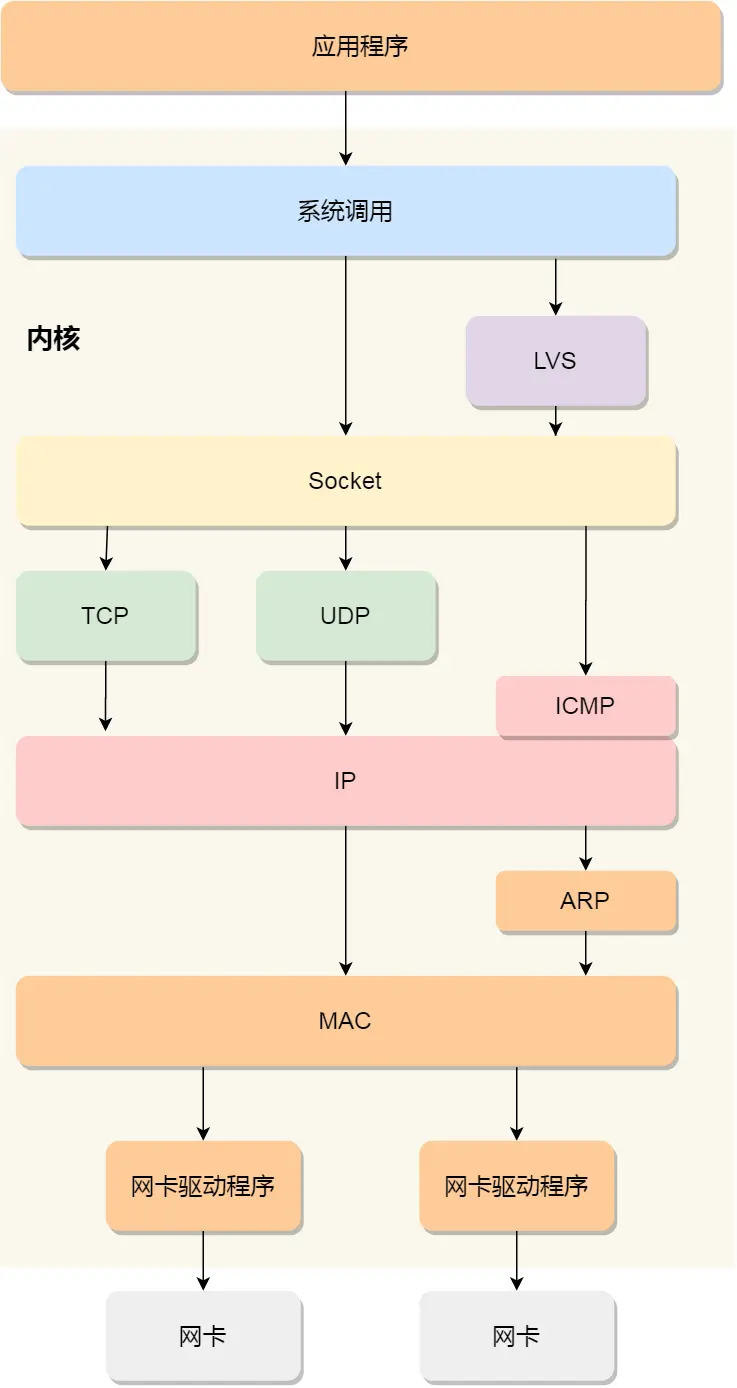
从上图的的⽹络协议栈,你可以看到:
应⽤程序需要通过系统调⽤,来跟 Socket 层进⾏数据交互;
Socket 层的下⾯就是传输层、⽹络层和⽹络接⼝层;
最下⾯的⼀层,则是⽹卡驱动程序和硬件⽹卡设备;
34.Linux 接收⽹络包的流程是什么
⽹卡是计算机⾥的⼀个硬件,专⻔负责接收和发送⽹络包,当⽹卡接收到⼀个⽹络包后,会通过 DMA 技****术,将⽹络包写⼊到指定的内存地址,也就是写⼊到 Ring Buffer ,这个是⼀个环形缓冲区,接着就会告诉操作系统这个⽹络包已经到达。
那应该怎么告诉操作系统这个⽹络包已经到达了呢?
最简单的⼀种⽅式就是触发中断,也就是每当⽹卡收到⼀个⽹络包,就触发⼀个中断告诉操作系统。
但是,这存在⼀个问题,在⾼性能⽹络场景下,⽹络包的数ᰁ会⾮常多,那么就会触发⾮常多的中断,要
知道当 CPU 收到了中断,就会停下⼿⾥的事情,⽽去处理这些⽹络包,处理完毕后,才会回去继续其他事情,那么频繁地触发中断,则会导致 CPU ⼀直没完没了的处理中断,⽽导致其他任务可能⽆法继续前进,从⽽影响系统的整体效率。
所以为了解决频繁中断带来的性能开销,Linux 内核在 2.6 版本中引⼊了 NAPI 机制,它是混合「中断和轮询」的⽅式来接收⽹络包,它的核⼼概念就是不采⽤中断的⽅式读取数据,⽽是⾸先采⽤中断唤醒数据接收的服务程序,然后 poll 的⽅法来轮询数据。
因此,当有⽹络包到达时,会通过 DMA 技术,将⽹络包写⼊到指定的内存地址,接着⽹卡向 CPU 发起硬件中断,当 CPU 收到硬件中断请求后,根据中断表,调⽤已经注册的中断处理函数。
硬件中断处理函数会做如下的事情:
-
需要先「暂时屏蔽中断」,表示已经知道内存中有数据了,告诉⽹卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提⾼效率,避免 CPU 不停的被中断。
-
接着,发起「软中断」,然后恢复刚才屏蔽的中断。
⾄此,硬件中断处理函数的⼯作就已经完成。
硬件中断处理函数做的事情很少,主要耗时的⼯作都交给软中断处理函数了。
内核中的 ksoftirqd 线程专⻔负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据。
ksoftirqd 线程会从 Ring Buffer 中获取⼀个数据帧,⽤ sk_buff 表示,从⽽可以作为⼀个⽹络包交给⽹络协议栈进⾏逐层处理。
⾸先,会先进⼊到⽹络接⼝层,在这⼀层会检查报⽂的合法性,如果不合法则丢弃,合法则会找出该⽹络
包的上层协议的类型,⽐如是 IPv4,还是 IPv6,接着再去掉帧头和帧尾,然后交给⽹络层。
到了⽹络层,则取出 IP 包,判断⽹络包下⼀步的⾛向,⽐如是交给上层处理还是转发出去。当确认这个⽹络包要发送给本机后,就会从 IP 头⾥看看上⼀层协议的类型是 TCP 还是 UDP,接着去掉 IP 头,然后交给传输层。
传输层取出 TCP 头或 UDP 头,根据四元组「源 IP、源端⼝、⽬的 IP、⽬的端⼝」 作为标识,找出对应的 Socket,并把数据放到 Socket 的接收缓冲区。
最后,应⽤层程序调⽤ Socket 接⼝,将内核的 Socket 接收缓冲区的数据「拷⻉」到应⽤层的缓冲区,然后唤醒⽤户进程。
⾄此,⼀个⽹络包的接收过程就已经结束了,你也可以从下图左边部分看到⽹络包接收的流程,右边部分刚好反过来,它是⽹络包发送的流程。
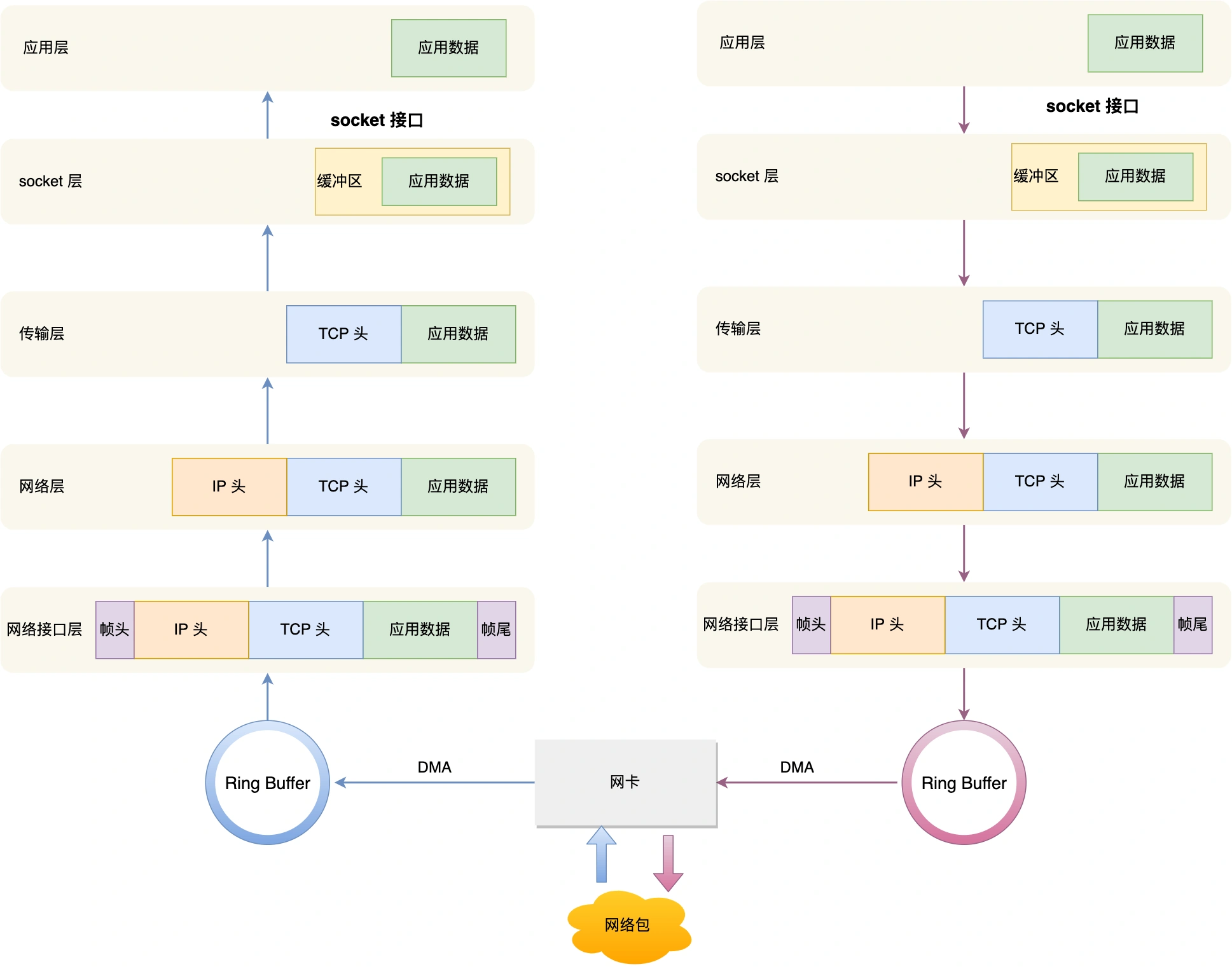
35.Linux发送网络包的流程是什么
如上图的右半部分,发送⽹络包的流程正好和接收流程相反。
⾸先,应⽤程序会调⽤ Socket 发送数据包的接⼝,由于这个是系统调⽤,所以会从⽤户态陷⼊到内核态中
的 Socket 层,内核会申请⼀个内核态的 sk_buff 内存,将⽤户待发送的数据拷⻉到 sk_buff 内存,并将其****加⼊到发送缓冲区。
接下来,⽹络协议栈从 Socket 发送缓冲区中取出 sk_buff,并按照 TCP/IP 协议栈从上到下逐层处理。
如果使⽤的是 TCP 传输协议发送数据,那么先拷⻉⼀个新的 sk_buff 副本 ,这是因为 sk_buff 后续在调⽤
⽹络层,最后到达⽹卡发送完成的时候,这个 sk_buff 会被释放掉。⽽ TCP 协议是⽀持丢失᯿传的,在收
到对⽅的 ACK 之前,这个 sk_buff 不能被删除。所以内核的做法就是每次调⽤⽹卡发送的时候,实际上传递出去的是 sk_buff 的⼀个拷⻉,等收到 ACK 再真正删除。
接着,对 sk_buff 填充 TCP 头。这⾥提⼀下,sk_buff 可以表示各个层的数据包,在应⽤层数据包叫data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
你可能会好奇,为什么全部数据包只⽤⼀个结构体来描述呢?协议栈采⽤的是分层结构,上层向下层传递
数据时需要增加包头,下层向上层数据时⼜需要去掉包头,如果每⼀层都⽤⼀个结构体,那在层之间传递
数据的时候,就要发⽣多次拷⻉,这将⼤⼤降低 CPU 效率。
于是,为了在层级之间传递数据时,不发⽣拷⻉,只⽤ sk_buff ⼀个结构体来描述所有的⽹络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,⽐如
- 当接收报⽂时,从⽹卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐
步剥离协议⾸部。
- 当要发送报⽂时,创建 sk_buff 结构体,数据缓存区的头部预留⾜够的空间,⽤来填充各层⾸部,在
经过各下层协议时,通过减少 skb->data 的值来增加协议⾸部。
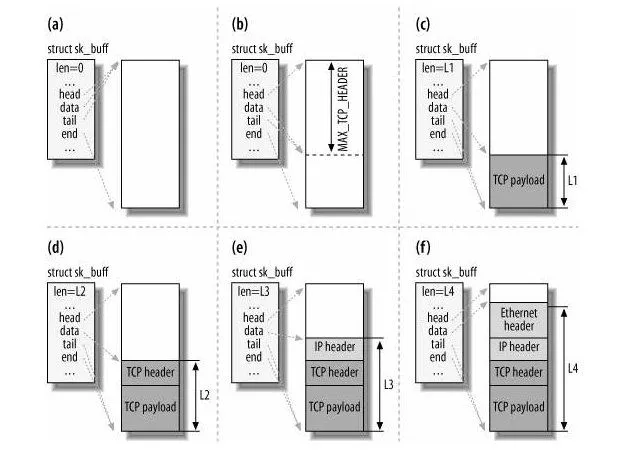
⾄此,传输层的⼯作也就都完成了。
然后交给⽹络层,在⽹络层⾥会做这些⼯作:选取路由(确认下⼀跳的 IP)、填充 IP 头、netfilter 过滤、
对超过 MTU ⼤⼩的数据包进⾏分⽚。处理完这些⼯作后会交给⽹络接⼝层处理。
⽹络接⼝层会通过 ARP 协议获得下⼀跳的 MAC 地址,然后对 sk_buff 填充帧头和帧尾,接着将 sk_buff
放到⽹卡的发送队列中。
这⼀些⼯作准备好后,会触发「软中断」告诉⽹卡驱动程序,这⾥有新的⽹络包需要发送,驱动程序会从
发送队列中读取 sk_buff,将这个 sk_buff 挂到 RingBuffer 中,接着将 sk_buff 数据映射到⽹卡可访问的内
存 DMA 区域,最后触发真实的发送。
当数据发送完成以后,其实⼯作并没有结束,因为内存还没有清理。当发送完成的时候,⽹卡设备会触发
⼀个硬中断来释放内存,主要是释放 sk_buff 内存和清理 RingBuffer 内存。
最后,当收到这个 TCP 报⽂的 ACK 应答时,传输层就会释放原始的 sk_buff 。
36.发送⽹络数据的时候,涉及⼏次内存拷⻉操作?
第⼀次,调⽤发送数据的系统调⽤的时候,内核会申请⼀个内核态的 sk_buff 内存,将⽤户待发送的数据
拷⻉到 sk_buff 内存,并将其加⼊到发送缓冲区。
第⼆次,在使⽤ TCP 传输协议的情况下,从传输层进⼊⽹络层的时候,每⼀个 sk_buff 都会被克隆⼀个新
的副本出来。副本 sk_buff 会被送往⽹络层,等它发送完的时候就会释放掉,然后原始的 sk_buff 还保留在
传输层,⽬的是为了实现 TCP 的可靠传输,等收到这个数据包的 ACK 时,才会释放原始的 sk_buff 。
第三次,当 IP 层发现 sk_buff ⼤于 MTU 时才需要进⾏。会再申请额外的 sk_buff,并将原来的 sk_buff 拷
⻉为多个⼩的 sk_buff。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









