







一 核心思想
这篇文章最主要的想法是更好的结合point-based和voxel-based方法,是一个2-stage的检测方法,与Faster RCNN类似,第一阶段进行proposal的选择,第二阶段对第一阶段的proposal进行refine处理。
除此之外,本文还提出Spherical anchor、PointsPool Layer的创新方法,不过个人认为只是对Pointrcnn与voxel的一种整合办法,pointrcnn负责stage-1,VFE作为stage-2的特征提取。
下图为算法的整个步骤。

二 核心步骤
本文提出的二阶段算法主要分为三大块,分别为Proposal Generation Module、Proposal Feature Generation和Box Prediction Network。

2.1 Proposal Generation Module

整体步骤如上图所示,核心步骤分为两步,分别为Spherical Anchor的proposal选择和基于Spherical Anchor的proposal选择出更精细的proposal。
2.1.1 Spherical Anchor

如上图所示,这边提出的spherical Anchor,是对每一个point都提出一个spherical anchor,也就是以这个point为中心,对每一个类别提出特定的半径作为这个spherical anchor的范围(car:2m;cyclist and people:1m ),仅仅是起到一个聚类的作用(后续需要用到这个聚类内的点进行特征提取。),之后仍然是有pre-define的h、w、l。
作者提出这个spherical Anchor是因为作者认为其他的地方提出的传统的anchor还要考虑orientation的问题(不过看了很多论文之后,并不认为这个是个问题,因为只是给anchor加了一个pre-define的angle,或者根本就是直接预测。),于是为了不让angle影响对proposal的选取,提出了spherical Anchor。

然后,为了减少冗余的anchor,使用NMS,基于PointNet++得出的每个点的segmentation label score来选择排名前500的proposal作为下一步的输入。
注意,在进行NMS时,由于我们在这里采用的是spherical Anchor,因此传统的IoU肯定是无法适用的,于是作者提出了PointsIoU,这边对PointsIoU的定义为: 两个区域交集面积上的点数与两个区域并集的点数的商。
2.1.2 Proposal Generation Network

本步骤也是stage-1的最后一步,是对之前一步经过NMS抑制后的输出的500个proposal进行进一步的筛选。这里也就用到spherical anchor的性质,基于PointNet的方法,对proposal相应的spherical anchor内的点进行特征的提取。当然在此之前,对每一个spherical anchor内的点的坐标首先转化到以该anchor的中心点(X,Y,Z)作为坐标系下的坐标(也就是对坐标的normalize操作。)。然后就是将spherical anchor内的每个点经过PointNet++后的segment features和normalize后的每个点的坐标作为输入,输入到PointNet网络中,提取这个proposal的特征,然后通过两个分支分别得出这个proposal的class label和local regression。具体框架见下图所示。

在这里,spherical anchor的中心(Ax,Ay,Az)和预先定义的anchor的(Ah,Aw,Al)被用于NMS中(这边用到了预测出来的local regression参数来提取出真实的预测出来的bbox信息),以选择前300个proposal。注意NMS用到的是class label score和oriented BEV IoU。
2.2 Proposal Feature Generation

这里开始了stage-2的阶段,首先是对stage-1阶段传过来的300个proposal进行特征处理。在stage-2也就没有spherical anchor的身影了。
这里对与每一个proposal,将其内部的点进行VFE的处理。在进行VFE操作之前,对于每个建议,我们通过减去proposal中心(X, Y, Z)值并将它们旋转到proposal预测方向来获得normalized坐标系。
在进行VFE(128,128,256)处理之后,得到这个proposal的体素特征(dl×dw×dh×256),然后将体素特征进行flatten操作,也就变为了(n×256),n的值也就等于dl*dw*dh。
2.3 Box Prediction Network

对于stage-2的最后一个阶段,作者将预测分为了两个大的预测branch,分别为box estimation branch和IoU estimation branch。box estimation branch预测常规的class label score和location score;IoU estimation branch预测该proposal与真实框的IoU(至于为什么要预测IoU而不是直接使用,是因为在测试集上,无法得知IoU。)。
将预测出的IoU与class进行相乘,感觉相当于是attention机制,这一步作者说是比单纯的用class score来进行NMS要好,实验确实验证了该观点。
2.4 Loss Function
总损失函数为:
![]()
1、首先是对stage-1的损失函数Lprop的讨论:

其中Lseg表示PointNet++预测出的segmention label loss(这里也就是预测前景点与背景点),使用flocal loss;si和ui分别表示stage-1中第i个预测的classification score和ground-truth label;Ncls和Npos分别表示stage-1的anchors的数量和前景的数量;Lcls只是简单的softmax cross entropy loss。
这边需要对Lloc和Lang更进一步讨论:
(1) 对于Lloc,假定预先给每个proposal定义的anchor(这里就是传统的anchor参数,作者仅仅是在第一阶段提出了spherical anchor的概念,这边都是传统的anchor。)为(Al,Aw,Ah),这个proposal的中心为(Ax,Ay,Az)。其对于的ground truth为(Gx,Gy,Gz,Gl,Gw,Gh),则Lloc定义为:
![]()
其中Ldis表示Smooth-L1 loss。Actr表示预测出的center residual;Asize表示size residual;Gctr表示center residual target;Gsize表示size residual target。且Gctr和Gsize表示为:
![]()
![]()
(2) 对于Lang,包含orientation classification class和residual prediction loss,具体为:
![]()
其中,ta-cls和ta-res表示预测出的angle class和residual;va-cls和va-res表示其target。
2、其次对于stage-2的Lbox,对于Box Estimation Branch的loss与stage-1相同(只是没有加上Lseg![]() )。
)。
对于IoU Estimation Branch的loss,将其分为两个loss,第一个loss为3D IoU loss,第二个为corner loss。
其中corner loss表示为:
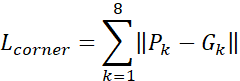
Pk和Gk分别表示预测出的点和ground truth的点。
三 总结
本文提出的方法,首先采用了segment label进行NMS抑制,这一步减少了后续的计算量,算是本文的创新点之一。然后是spherical anchor,作者认为该方法可以减少计算量,不过本人认为只是单纯的起到了聚类特征的作用。最后预测的IoU,类似于attention机制,确实在精确性上提升,可以考虑用在其他算法上。















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









