






F.binary_cross_entropy_with_logits 抽象运算原理
PyTorch 中的 F.binary_cross_entropy_with_logits 函数计算的是带有逻辑斯特回归(logistic regression)的二元交叉熵损失。这个函数适用于当模型的输出是未经过 sigmoid 激活的原始 logits 时。它在内部应用 sigmoid 函数,然后计算二元交叉熵损失。
示例代码
下面是一个使用 PyTorch 计算二元交叉熵损失的示例:
import torch
import torch.nn.functional as F
def loss_with_builtin(logits, targets):
return F.binary_cross_entropy_with_logits(logits, targets)
def loss_manual(logits, targets):
probabilities = torch.sigmoid(logits) # 值转化为0-1之间
loss = - (targets * torch.log(probabilities) + (1 - targets) * torch.log(1 - probabilities)) # (2, 3)
# 即对于每一个位置,
# 若targets=1,则这个位置的损失为 -log(probabilities),0~1 -> 正无穷~0 。即正样本损失。
# 若targets=0,则这个位置的损失为 -log(1 - probabilities),0~1 -> 0~正无穷 。即负样本损失。
loss = torch.mean(loss) # 最后将每一个位置的损失相加求平均
return loss
# 定义模型的原始输出,未经过 Sigmoid 激活。shape 为 (2, 3)
logits = torch.tensor([[1.1, -2.0, 3.4], [-2.4, 3.9, -4.7]])
# 目标值。形状需要与 logits 一致。值在 0 到 1 之间。
targets = torch.tensor([[0.0, 1.0, 0.0], [1.0, 0.0, 1.0]])
loss_builtin = loss_with_builtin(logits, targets) # 使用F.binary_cross_entropy_with_logits计算损失
loss_manual = loss_manual(logits, targets) # 手动计算binary_cross_entropy_with_logits损失
print('loss_builtin:', loss_builtin)
print('loss_manual:', loss_manual)
结果与分析
运行上述代码,我们得到以下结果:
loss_builtin: tensor(3.0105)
loss_manual: tensor(3.0105)
结果相同,故手动实现的方法解释了 F.binary_cross_entropy_with_logits内部到底是如何计算的。
多分类原理
在上述代码中,我们没有给logits和targets赋予具体含义,而是抽象地将它们视为一系列数字。于是在上面我们清楚地理解了binary_cross_entropy_with_logits的计算原理。
现在,让我们给logits和targets赋予实际意义,并考虑一般的N分类问题。我们需要定义好one-hot编码的targets,即每个样本是一个形状为(N,)的向量,其中只有一个位置是1,其余位置都是0。对于每个样本,其logits也是一个形状为(N,)的向量,这是模型经过全连接层但未经过sigmoid激活函数的输出。故若有X个样本,则logits和targets的形状皆为(X, N)。(当然,其也可以是任意形状,因为我们在上面已经知道了,binary_cross_entropy_with_logits的计算与输入向量的形状无关。)然后,我们可以直接将这些值代入到F.binary_cross_entropy_with_logits函数中进行计算。这种方法被称为“通过多个二分类来实现多分类”。
Focal loss
原理
正如上面代码中的注释所说,若targets=1(正样本),则这个位置的损失为 -log(probabilities),若targets=0(负样本),则这个位置的损失为 -log(1 - probabilities)。这样对于正负样本的损失是公平的。但我们考虑,若输入中有绝大部分都为1(或0),剩下的小部分为0(或1),那么在初期,对于绝大部分的那个类别造成的loss占总loss的比重会很大,这样会导致模型被loss训练为倾向于预测为绝大部分的那个类别,而对于何时预测为少数的类别,模型收到的惩罚会很小。于是Focus Loss就是为了解决这个问题而提出的。
首先Focus Loss定义一个值alpha,这个值是一个超参数,用来控制正负样本的损失权重。具体来说,其定义出两个系数,一个是正样本的系数(alpha),一个是负样本的系数(1-alpha)。(或者反过来,很明显是等效的。)可以看到其和为1,它们分别用于乘在-log(probabilities)与-log(1 - probabilities)之前,即相当于对正负样本的损失进行了加权平均。例如如果输入中有绝大部分都为1,那么则令alpha < 0.5,这样就可以解决上面提到的问题。一般取alpha=0.25,可以发现其实反而是将一般较少的正样本的权重放得更小了,这似乎与我们前面的解释矛盾。
我们找到Focus Loss原论文,其中有这样一张表:
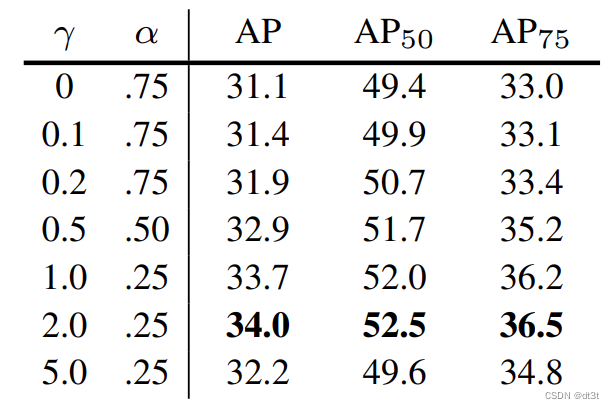
据此,有人如此解释到:
“这归因于α参数和焦点项之间的相互作用。您可以看到,在表1b中引入焦点损失项时,特别是在γ > 0.5的情况下,他们需要使用一个非直观的α值。这是因为随着γ增大,焦点损失会进一步强化对难分类样本的关注,此时需要调整α来平衡各类别的权重,防止模型过于偏向背景或前景类别。”
Focus Loss论文中也说到:
“我们注意到赋予罕见类别的权重α也有一个稳定的范围,但它会与γ相互作用,因此有必要同时选择这两个参数。一般来说,随着γ增大,应稍微降低α的值(对于γ = 2的情况,α = 0.25效果最佳)。”
好了,让我们放下有些令人迷惑的alpha。现在我们考虑-log(probabilities)与-log(1 - probabilities),其实它们不过是probabilities的函数,对于0~1的probabilities,其值域分别为正无穷到0和0到正无穷。我们将它们简记为f(x)=-log(x)和g(x)=-log(1-x)。而Focus Loss修改了这两个函数,使其在接近预测正确时loss相对原来的更小(当更接近预测错误时loss和原来的差不多)。具体来说,其另f(x)=-(1-x)^gamma * log(x)和g(x)=-x^gamma * log(1-x),即分别多出了(1-x)^gamma和x^gamma项。这样就可以使得在接近预测正确时loss相对原来的更小。其中gamma是手动调整的超参数,一般取2。
我们可以看下面的图,这里取gamma=2,其中红线为两个f(x),蓝线为两个g(x)。虚线为原始的,实线为Focus Loss的。我们只需要仔细观察在横坐标0和1之间,曲线的变化即可。
我们看到其总体趋势与值域并没有改变。
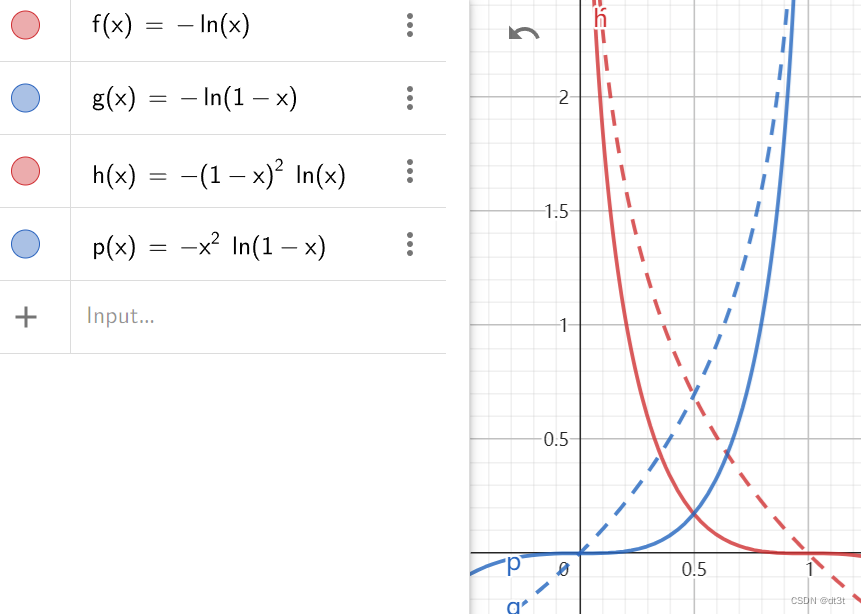
从图像可以看出,相比于原始形式的loss,Focus Loss的这一改动使得对于分类错误的样本,其产生的梯度显著地大于分类正确的。而原始形式的loss,你可以看到在横坐标0~1范围内,它们的梯度在大部分时间都相差不大。这即是这一改动地作用。
代码
def sigmoid_focal_loss(
inputs: torch.Tensor,
targets: torch.Tensor,
alpha: float = -1,
gamma: float = 2,
reduction: str = "none",
) -> torch.Tensor:
"""
Loss used in RetinaNet for dense detection: https://arxiv.org/abs/1708.02002.
Args:
inputs: A float tensor of arbitrary shape.
The predictions for each example.
targets: A float tensor with the same shape as inputs. Stores the binary
classification label for each element in inputs
(0 for the negative class and 1 for the positive class).
alpha: (optional) Weighting factor in range (0,1) to balance
positive vs negative examples. Default = -1 (no weighting).
gamma: Exponent of the modulating factor (1 - p_t) to
balance easy vs hard examples.
reduction: 'none' | 'mean' | 'sum'
'none': No reduction will be applied to the output.
'mean': The output will be averaged.
'sum': The output will be summed.
Returns:
Loss tensor with the reduction option applied.
"""
inputs = inputs.float()
targets = targets.float()
p = torch.sigmoid(inputs) # 转化到0~1之间
ce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none") # 计算原始的交叉熵损失
# 改动f(x), g(x)
p_t = p * targets + (1 - p) * (1 - targets)
loss = ce_loss * ((1 - p_t) ** gamma)
# 分别对正负样本乘上alpha与(1 - alpha)
if alpha >= 0:
alpha_t = alpha * targets + (1 - alpha) * (1 - targets)
loss = alpha_t * loss
if reduction == "mean":
loss = loss.mean()
elif reduction == "sum":
loss = loss.sum()
return loss
我们可以看到其不过是先调用F.binary_cross_entropy_with_logits计算原本的loss,然后再乘上上面介绍的两个系数即得到Focus Loss。我们从中可以学习到实现正负样本分别计算的技巧,即使用* targets与* (1 - targets),其体现在p_t = p * targets + (1 - p) * (1 - targets)与alpha_t = alpha * targets + (1 - alpha) * (1 - targets)这两行代码。














 7327
7327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









