






输入介绍:

其中criterion为models/conditional_detr.py中的SetCriterion类。outputs与targets进入其forward函数。
以下所有内容中,采用超参数bs为4,decoder层数(n_decoder)为4,object query数量为200。
outputs组成如下:

outputs包含最后一层的输出pred_logits(分类置信度,未经过sigmoid),pred_boxes(框,形式为cxcywh)与前几层的输出aux_outputs。故pred_logits与pred_boxes中的4为bs,aux_outputs为list,包含n_decoder-1个dict,每个为一层的输出。
targets组成如下:
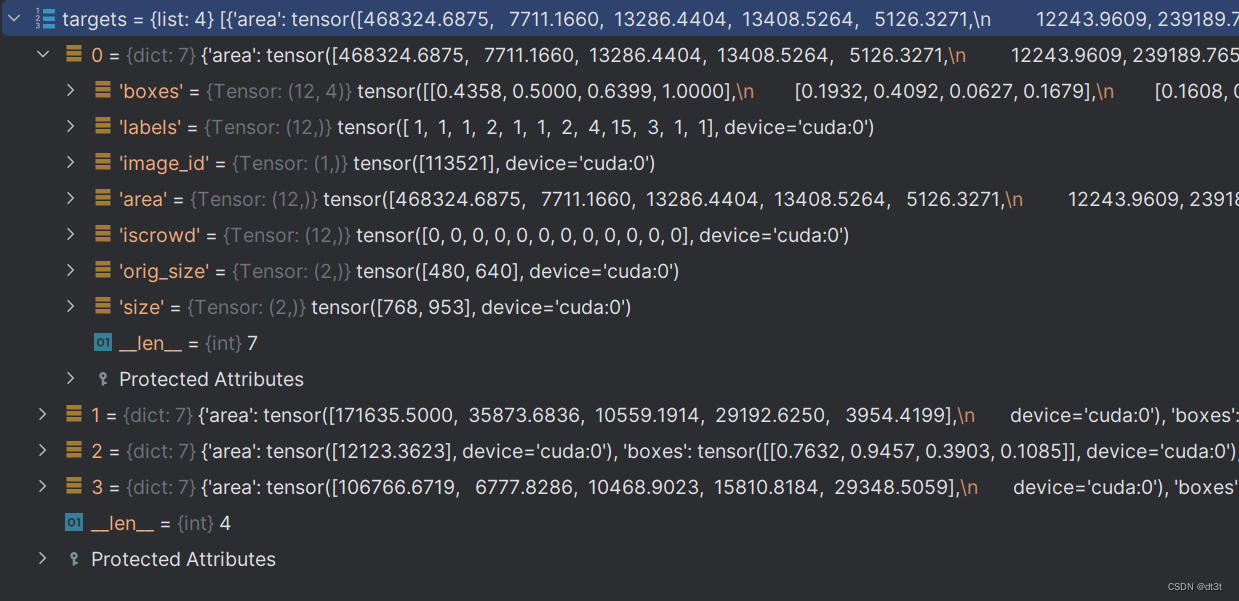
targets为list,包含bs个dict。box为归一化后的gt框。labels对应每个框的标签(编号为1~90中的8个)。其他的内容大概不重要。
匈牙利匹配:

outputs_without_aux即为outputs去掉aux_outputs。(其实去不去掉都一样,self.matcher里只会取出pred_logits与pred_boxes,并不会管你有没有aux_outputs)
self.matcher:
然后将outputs_without_aux与targets输入self.matcher中,其为models/matcher.py中的HungarianMatcher类,我们进入到其forward函数:
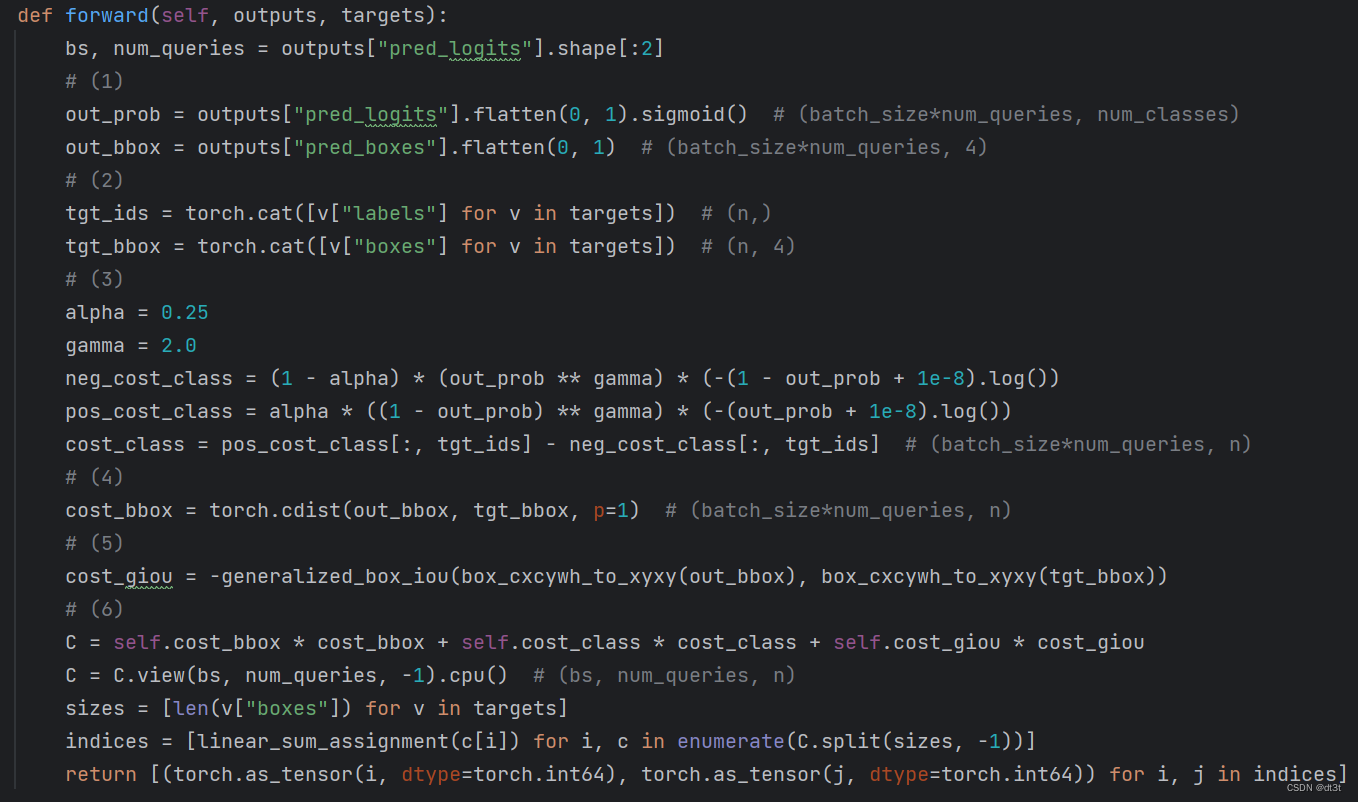
(1)将outputs中的pred_logits与pred_boxes取出,将分类置信度经过sigmoid到0~1区间,将bs和n_qurey两个维度混为一个(见注释标明了混合后的形状,至于为什么要混合,下文有解释)。
(2)取出了所有bs的labels与boxes。注释中的n为n(1)+n(2)+...+n(bs),其中n(k)代表这个批次第k张图片中的gt框数(k属于[1, bs])。即n为这个批次中所有图片总框数。
class cost:
(3)我们直接看这三个函数的图像,蓝绿虚线分别对应neg_cost_class与pos_cost_class(1e-8在此被忽略,代码中的log实际上为ln),红色实线为cost_class。其中x即代表out_prob(取值0~1)。故我们只需要观察横坐标0~1对应的曲线变化情况。总之,对于out_prob中的值,其越接近1,cost_class就越小,反之越大。注意cost_class取出元素的逻辑(见上面代码注释的cost_class形状)。

上面图像使用GeoGebraCalculator绘制,文件已放置在网盘,有需要的同学可自行下载把玩:
软件及GGB文件下载链接(百度网盘)![]() https://pan.baidu.com/s/19-xYyVaArqGC-SeLfiLwaQ?pwd=jntm
https://pan.baidu.com/s/19-xYyVaArqGC-SeLfiLwaQ?pwd=jntm
这里不详细解释为什么采用这样的函数(我也没搞懂为什么非要用这个)。
另外,原版DETR采用如下方法计算cost_class:

这样看来,似乎cost_class=h(out_prob)这一函数满足单调递减就可以。
L1 cost:
(4)计算所有预测框与所有gt框的L1距离(各维度差的绝对值之和)。具体来说,out_bbox(batch_size*num_queries, 4)与tgt_bbox(n,4)之间两两计算距离,p=1代表使用L1距离。最后输出得到的cost_bbox形状为(batch_size*num_queries, n)。
Giou cost:
(5)计算giou coat,与(4)类似,最终的cost_giou形状与cost_bbox相同,不详细阐述。注意输入generalized_box_iou函数的坐标需要为xyxy形式且在0~1之间。由于需要giou越大,cost应当越小,故giou值取负作为cost。
cost矩阵与匹配:
(6)混合所有cost,处理为cost矩阵。具体来说,先将3种cost加权组合,此时形状仍然为(batch_size*num_queries, n)。接着reshape为(batch_size, num_queries, n),为接下来分开每个批次的处理做准备。sizes为一个包含bs个int的list,每个int即为对于图像中的gt框数,即上面提到的n(i),故其和为n。C.split(sizes, -1)的作用为按照sizes中的数在-1(即最后一个)维度上做分割。故对于枚举C.split(sizes, -1)中元素的c,其tensor的形状为(batch_size, num_queries, n(i))。故c[i]为(num_queries, n(i)),即为每一张图像内的query与这种图像的gt的cost矩阵。接着使用linear_sum_assignment计算得到匹配,得到的indices后,将numpy类型转化为int64tensor,最后return的内容结构如下:

至于为什么要先把批次内图像混合之后计算出cost矩阵最后再分开,官方解释为这样效率高一些:

Loss字典计算:

num_boxes为the average number of target boxes accross all nodes。
self.loss:

self.get_loss:

其中mask loss只有在做语义分割时会有,目标检查任务中无。
self.loss_labels:

idx为tuple,包含两个形状为(n,)的tensor,这样的数据组织结构常用于作为另外tensor的索引。在这里,其内容为批次内“图片编号”与“这张图片内匹配到gt成功的query的编号”,内容如下:

target_classes_o形状为(n,),内容为批次内所有图片的gt框的真实类别编号:
![]()
target_classes为(bs, num_queries)形状的全x数组,其中x=num_classes。(初始化)
![]()
通过target_classes[idx] = target_classes_o语句,可以看到idx确实作为了target_classes的索引,将索引到的元素一一对应地赋值为target_classes_o中的元素。故此时target_classes的意义已经明确,即为每个query的真实标签,其中这里的91(即num_classes)就用于代表背景,即在matcher中未被匹配到gt框的query。
接下来三行代码生成真实类别的one-hot向量:

由于要生成one-hot向量,故先初始化target_classes_onehot为全0的(bs, num_queries, num_classes + 1)形状,至于为什么是num_classes + 1,最后一个维度将作为背景维度用于辅助下一步的赋值。(这里的num_classes为91,真实标签为1~90,上文又提到91将作为背景类别。由于下一步将直接使用数字1~91作为target_classes_onehot最后一维的索引,于是需要最后一维的大小为num_classes + 1,即92。也就是说,索引0始终不代表任何类别,包括背景类别)
关于target_classes_onehot.scatter_(2, target_classes.unsqueeze(-1), 1)这行代码,知道其运行后的效果为按照target_classes将target_classes_onehot变为one-hot形式就可以了,具体用法见下面的链接:
pytorch中torch.Tensor.scatter用法
刚才说过num_classes + 1中的1是作为辅助,于是这里最后将其去掉。这样target_classes_onehot变为了(bs, num_queries, num_classes)形状,其中值为1的位置都为真实类别。(其实刚才所谓的“背景类别”只是我们一厢情愿的理解,你可以仅仅将其看作一个用于生成one-hot的辅助维度)
这样,src_logits于target_classes_onehot的形状便相同了,直接放入sigmoid_focal_loss中计算损失。至于这个focal loss的原理,还没有细看,但看了下sigmoid_focal_loss的代码,总之就是在普通交叉熵损失的每个值上乘以对应的系数,然后最后得到的losses是所有位置的loss之和除以num_boxes。
对于最后的losses['class_error'],经过我查看代码,其公式经化简为(1-t/n)*100,其中t为n个匹配对中,query类别预测正确的个数。(n代表的意义同前文)
self.loss_boxes:
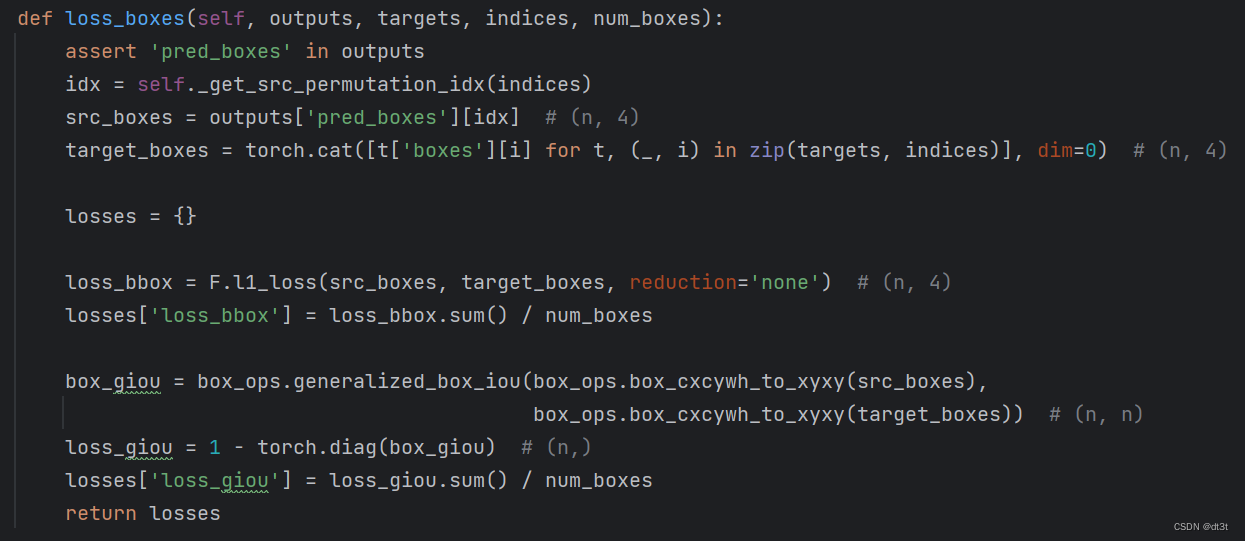
其loss由L1 loss与giou loss两部分组成,本别被命名为loss_bbox与loss_giou。这里主要解释一下giou loss的计算:box_ops.generalized_box_iou()函数计算n个预测框与n个gt框两两之间的giou值,得到(n, n)形状的box_giou。然后使用torch.diag()取对角线元素,由于现在的值是giou值,需要用1减之作为最终的loss。其他的内容于上面的self.loss_labels差不多,便不再详细讲解。
self.loss_cardinality:

tgt_lengths为一个包含bs个int的list,每个int即为对于图像中的gt框数。card_pred计算每张图像中没有预测为背景的query数量。然后使用L1 loss计算差距。
但其实这里的计算是错误的。这里需要说明Conditional-DETR与原版DETR的一个不同:原版DETR的分类头输出层维度为num_classes+1,而Conditional-DETR的为num_classes。故原版DETR的最后一个维度(即索引为91的维度)确实代表了背景类别,但Conditional-DETR根本没有索引为91的维度,之前(在self.loss_labels的解析中)也说过了,索引的0的维度没有任何含义,不表示任何类别,故Conditional-DETR的分类头输出并没有所谓的背景类别(索引1~90被实际的类别占用)。self.loss_cardinality函数是照搬的原版DETR的,于是这里对cardinality的计算毫无意义。但反正cardinality也不参与梯度计算,也无伤大雅了。另外,正如刚才提到的分类头维度的不同,也会导致self.loss_labels不能完全照搬原版DETR的,但loss_labels显然是要参与梯度计算,故Conditional-DETR的self.loss_labels确实是在原版DETR的之上做出了修改,以适应这一点,下面是原版DETR的self.loss_labels代码:

感兴趣的读者可以同上文展出的Conditional-DETR的self.loss_labels代码进行对比。
Loss加权相加:
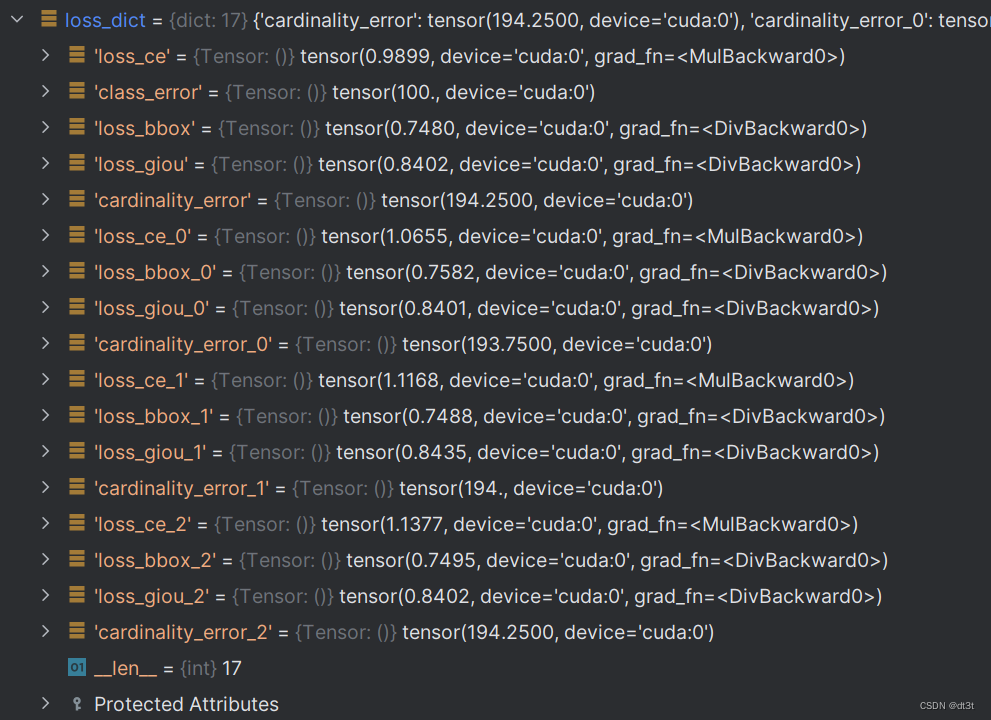
注意到class_error只有最后一层有,符合上面的代码。cardinality每一层都有。
但并不是它们都需要用作梯度计算。最后真正需要用作反向传播计算梯度的losses为其中一些loss的加权和:

其中weight_dict为需要的loss对应的权重,如下:

注意到只有ce, bbox, giou,不包含cardinality和class_error。
故如若想要自行添加其他loss并使其参与梯度计算,需要在models/conditional_detr.py中的SetCriterion类中实现之,使得返回的loss_dict包含你的loss(默认每一层都会计算)。然后需要在models/conditional_detr.py中的build函数中对weight_dict字典添加这个loss的权重(对同一种loss,默认对每一层都是相同的权重)。注意loss_dict与weight_dict中你的loss的名字应当一致。存在于loss_dict但在weight_dict中没有对应权重的loss将不会影响到梯度计算,其只会通过metric_logger打印在屏幕上。(如cardinality和class_error)
PostProcess后处理:
这一部分仅在evaluation时使用,在train时不使用。
代码位于models/conditional_detr.py中的PostProcess类:

其中target_sizes以(bs, 2)的shape封装了图片的h,w。
接着,prob_flat为out_logits在num_queries和num_classes上进行混合,即形状变为(bs, num_queries * num_classes)。这样接下来对于每张图,其都有num_queries * num_classes个概率(取值0~1),使用torch.topk(prob_flat, 100, dim=1)在其中取最大的k(这里为100)个值(与其索引),即代码中的topk_values(值)与topk_indexes(索引),二者的形状皆为(bs, k)。或许你会疑惑这样top-k个概率中不是可能会有好几个都属于同一个query吗?经过我的实验,对于模型不训练之前确实是这样,但经过训练之后应该就不会了。并且即使不训练,当num_queries为k的两倍及以上时,几乎也不会出现这种情况(如果用概率论计算一下的话,大概是很小的概率吧)。你可能还想问为什么k取100(即为什么只取概率最高的100个框来进行评测),实际上经过我的实验,取其他的值也是可以的,例如90或50,不过最终评测结果可能会降低一丢丢(小于1)。
然后使用对topk_indexes采用num_classes(也就是代码中的out_logits.shape[2])的整除与取模操作即可获得topk_indexes索引位于的query编号(即代码中的topk_boxes)与类别(即代码中的labels)。
接下来便是按topk_boxes取出out_bbox中的预测框,然后乘上原图尺寸获得最终boxes结果。














 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









