





tensor
import torch
import numpy as np
# 创建tensor
data = [[1,2],[3,4]]
x_data = torch.tensor(data)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
# 创建形状相同的tensor
x_ones = torch.ones_like(x_data)
x_rand = torch.rand_like(x_data)
# 创建某种形状的tensor
shape = (2,3,) # 注意最后还有一个逗号
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
# 获取tensor的相关属性
tensor.shape
tensor.dtype
tensor.device
# 将tensor从cpu(默认)上转到gpu上
# 首先检查gpu是否可用
if torch.cuda_is_available():
tensor = tensor.to('cuda')
# 索引和切片
tensor = torch.ones(4,4)
print('First row: ',tensor[0])
print('First column: ', tensor[:, 0])
print('Last column:', tensor[..., -1])
tensor[:,1] = 0
print(tensor)
'''
First row: tensor([1., 1., 1., 1.])
First column: tensor([1., 1., 1., 1.])
Last column: tensor([1., 1., 1., 1.])
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
'''
# 连接tensor
t1 = torch.cat([tensor,tensor,tensor],dim=1)
# 提供的非空的张量除了连接的维度外都必须具有相同的形状,dim指的是张量连接的维度。
# 如果dim=0,说明输出结果的其他维度不变,第一维的大小变成了所拼接的张量的和。
# 数学运算
# 以下三种方法用来计算两个tensor的矩阵乘法
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)
# 以下三种方法用来计算两个tensor的点乘
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
# 使用item()方法将仅包含一个元素的tensor转化为python数据类型
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))
'''
12.0 <class 'float'>
'''
# 将结果存储到操作数中的操作称为就地操作in-place operation。
# 它们用后缀_表示。例如:x.copy_(y), x.t_(),这些操作都将改变x。
print(tensor)
tensor.add(5)
print(tensor)
tensor.add_(5)
print(tensor)
'''
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
tensor([[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.],
[6., 5., 6., 6.]])
'''
tensor 和 ndarray共享内存,只要一方发生改变,另一方也会改变。
datasets 和 dataloaders
为了让数据集和模型训练解耦,从而提高可读性和模块化程度,pytorch提供两种数据基元torch.utils.data.DataLoader和torch.utils.data.Dataset用以载入数据。
Dataset存储了samples和lables,DataLoader在Dataset周围包装了一个可迭代对象,以方便访问samples。
an example:https://pytorch.org/text/stable/datasets.html
loading a dataset
以fashion MNIST为例,其中包含60000张训练图片和10000张测试图片,每个图片都是28x28的灰度图,包含10个类别。
相关的参数:
root:训练和测试数据的位置
train:二元,默认True,区分训练还是测试
download=True,如果root中不包含数据集则下载
***transform***和***target_transform***指feature和label的变形。
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
迭代和可视化数据集
labels_map = {
0:'t-shirt',
1:'trouser',
2:'pullover',
3:'dress',
4:'coat',
5:'sandal',
6:'shirt',
7:'snearker',
8:'bag',
9:'ankle boot',
}
figure = plt.figure(figsize=(8,8))
cols,rows = 3,3
for i in range(1,cols * rows +1): # 只sample9个例子画图
sample_idx = torch.randint(len(training_data),size=(1,)).item() # 随机从0-60000中生成一个int,作为要取的sample的索引
img, label = training_data[sample_idx] # 获取上述索引对应的图片和类标
figure.add_subplot(rows, cols,i) # 将获得的图片放进子图中
plt.title(labels_map[label]) # 把类标映射成对应的文字表示
plt.axis('off') # 不要坐标轴(若删掉会按照像素点取值
plt.imshow(img.squeeze(),cmap='gray')
# 相关的色彩有supported values are 'Accent', 'Accent_r', 'Blues', 'Blues_r', 'BrBG', 'BrBG_r', 'BuGn', 'BuGn_r', 'BuPu', 'BuPu_r', 'CMRmap', 'CMRmap_r', 'Dark2', 'Dark2_r', 'GnBu', 'GnBu_r', 'Greens', 'Greens_r', 'Greys', 'Greys_r', 'OrRd', 'OrRd_r', 'Oranges', 'Oranges_r', 'PRGn', 'PRGn_r', 'Paired', 'Paired_r', 'Pastel1', 'Pastel1_r', 'Pastel2', 'Pastel2_r', 'PiYG', 'PiYG_r', 'PuBu', 'PuBuGn', 'PuBuGn_r', 'PuBu_r', 'PuOr', 'PuOr_r', 'PuRd', 'PuRd_r', 'Purples', 'Purples_r', 'RdBu', 'RdBu_r', 'RdGy', 'RdGy_r', 'RdPu', 'RdPu_r', 'RdYlBu', 'RdYlBu_r', 'RdYlGn', 'RdYlGn_r', 'Reds', 'Reds_r', 'Set1', 'Set1_r', 'Set2', 'Set2_r', 'Set3', 'Set3_r', 'Spectral', 'Spectral_r', 'Wistia', 'Wistia_r', 'YlGn', 'YlGnBu', 'YlGnBu_r', 'YlGn_r', 'YlOrBr', 'YlOrBr_r', 'YlOrRd', 'YlOrRd_r', 'afmhot', 'afmhot_r', 'autumn', 'autumn_r', 'binary', 'binary_r', 'bone', 'bone_r', 'brg', 'brg_r', 'bwr', 'bwr_r', 'cividis', 'cividis_r', 'cool', 'cool_r', 'coolwarm', 'coolwarm_r', 'copper', 'copper_r', 'cubehelix', 'cubehelix_r', 'flag', 'flag_r', 'gist_earth', 'gist_earth_r', 'gist_gray', 'gist_gray_r', 'gist_heat', 'gist_heat_r', 'gist_ncar', 'gist_ncar_r', 'gist_rainbow', 'gist_rainbow_r', 'gist_stern', 'gist_stern_r', 'gist_yarg', 'gist_yarg_r', 'gnuplot', 'gnuplot2', 'gnuplot2_r', 'gnuplot_r', 'gray', 'gray_r', 'hot', 'hot_r', 'hsv', 'hsv_r', 'inferno', 'inferno_r', 'jet', 'jet_r', 'magma', 'magma_r', 'nipy_spectral', 'nipy_spectral_r', 'ocean', 'ocean_r', 'pink', 'pink_r', 'plasma', 'plasma_r', 'prism', 'prism_r', 'rainbow', 'rainbow_r', 'seismic', 'seismic_r', 'spring', 'spring_r', 'summer', 'summer_r', 'tab10', 'tab10_r', 'tab20', 'tab20_r', 'tab20b', 'tab20b_r', 'tab20c', 'tab20c_r', 'terrain', 'terrain_r', 'turbo', 'turbo_r', 'twilight', 'twilight_r', 'twilight_shifted', 'twilight_shifted_r', 'viridis', 'viridis_r', 'winter', 'winter_r'
plt.show()
为自己的文件创建数据集
必须包含的三个函数:__init__, __len__, and __getitem__.
import os
import pandas as pd
import torchvision.io as tvio
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotaions_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = traget_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self,idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx,0])
image = tvio.read_image(image_path)
label = self.img_labels.iloc[idx,1]
if self.transform:
image = selef.transform(image)
if self.target_transfrom:
label = self.target_transform(label)
sample = {'image': image, 'label':label}
return sample
使用dataloaders为训练准备数据
当训练模型的时候需要将minibatch大小的实例传到模型中,在每个epoch重新洗选数据以减少模型过拟合,并使用Python的多处理来加速数据检索。
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data,batch_size=64,shuffle=True)
test_dataloader = DataLoader(test_data,batch_size=64,shuffle=True)
下面的每次迭代都批量使用了train_features和train_labels(分别包含Batch_size = 64个features和labels)。因为我们指定了shuffle = true,因为我们迭代所有批处理后,数据被洗牌(对于通过数据加载顺序进行更精细的粒度控制,请查看采样器。
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
transform the data
将不能直接用于训练的数据转换。
例子中的feature都是PIL(python information library)的格式,label是int格式,需要将feature转化为tensor格式,label转化为one-hot格式,需要应用的函数是totensor和lambda.
from trochvision import datasets
from torchvision.transforms import ToTensor, Lambda
ds = datasets.FashionMNIST(
root='root',
train=True,
download=True,
transform=ToTensor(),
target_transform=Lambda(lambda y:torch.zeros(10,dtype=torch.float).scatter_(0,torch.tensor(y),value=1)))
其中ToTensor()能将PIL图片或者ndarray转换为FloatTensor的格式,并将图片的像素密度转为[0,1]之间。
构建模型
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transfroms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512,512),
nn.ReLU(),
nn.Linear(512,10),
nn.ReLU()
)
def forward(self,x):
x = self.flatten(x) # 降维,将张量变为一维
logits = self.linear_relu_stack(x)
return logits
每一个nn.Module类的实现都是通过forward方法实现的。
model = NeuralNetwork().to(device)
print(model)
模型实现forward方法的同时,需要同时进行后向传播操作,因此不能直接使用forward方法。
基于上述输入调用模型会返回一个10维的张量,每一个类都会有一个原始的预测值,使用nn.Softmax 模块获得预测密度。
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
实际上模型就是几个不同的层堆积起来的,下面是具体解析:
# 首先初始化输入
# 这里将minibatch设置成3张长和宽都是28像素的图片
input_image = torch.rand(3,28,28)
print(input_image.size())
# nn.flatten
# 使用flatten将28x28的图片转换为一维的784像素的array
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size)
# nn.Linear
# 线性层执行了线性变化,根据存储的weight和biase对输入进行线性变换
layer1 = nn.Linear(in_features=28*28,out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())
'''
torch.Size([3, 20]) # hidden1已经都变成20维了
'''
# nn.ReLU
# 非线性激活函数,将原始的数据映射到[0,+∞) 之间
# hidden1
print(f'before relu:{hidden1}\n\n')
hidden1 = nn.ReLU()(hidden1)
print(f'after relu:{hidden1}\n\n')
# nn.Sequential
# 容器,定义数据通过的顺序
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20,10)
)
input_image = torch.rand(3,28,28)
logits = seq_mosules(input_image)
# nn.Softmax
# 经过softmax层,原始分布于整个实数域上的数据会被转换为[0,1]区间中的值
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
#模型参数是动态训练获得的
print('model strcture:',model, '\n\n')
for name,param in model.named_parameters():
print(f'layer:{name} | size:{param.size()} | values:{param[:2]}\n')
'''
Model structure: NeuralNetwork(
(flatten): Flatten()
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
(5): ReLU()
)
)
Layer: linear_relu_stack.0.weight | Size: torch.Size([512, 784]) | Values : tensor([[-0.0320, 0.0326, -0.0032, ..., -0.0236, -0.0025, -0.0175],
[ 0.0180, 0.0271, -0.0314, ..., -0.0094, -0.0170, -0.0257]],
device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.0.bias | Size: torch.Size([512]) | Values : tensor([-0.0134, 0.0036], device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.2.weight | Size: torch.Size([512, 512]) | Values : tensor([[-0.0262, 0.0072, -0.0348, ..., -0.0374, 0.0345, 0.0374],
[ 0.0439, -0.0101, 0.0218, ..., -0.0419, 0.0212, -0.0081]],
device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.2.bias | Size: torch.Size([512]) | Values : tensor([ 0.0131, -0.0289], device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.4.weight | Size: torch.Size([10, 512]) | Values : tensor([[ 0.0376, -0.0359, -0.0329, ..., -0.0057, 0.0040, 0.0307],
[-0.0196, -0.0440, 0.0250, ..., 0.0335, 0.0024, -0.0207]],
device='cuda:0', grad_fn=<SliceBackward>)
Layer: linear_relu_stack.4.bias | Size: torch.Size([10]) | Values : tensor([-0.0287, 0.0321], device='cuda:0', grad_fn=<SliceBackward>)
'''
自动微分
可以使用torch.autograd进行自动微分
在训练神经网络时,最常用的算法是后向传播算法,在这个算法中,参数(模型权重)根据损失函数的梯度动态调整。
为了计算梯度,pytorch内置了梯度引擎torch.autograd支持自动为计算图计算梯度。
考虑最简单的神经网络,给定输入x,参数w和b以及一些损失函数。
import torch
x = torch.ones(5)
y = torch.zeros(3)
w = torch.randn(5,3,requires_grad=True) # 因为要计算梯度,所以需要另设requires_grad是True,也可以先不设置,之后使用x.requires_grad_(True)使tensor可以计算梯度。
b = torch.randn(3,requires_grad=True)
z = torch.matmul(x,w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z,y)
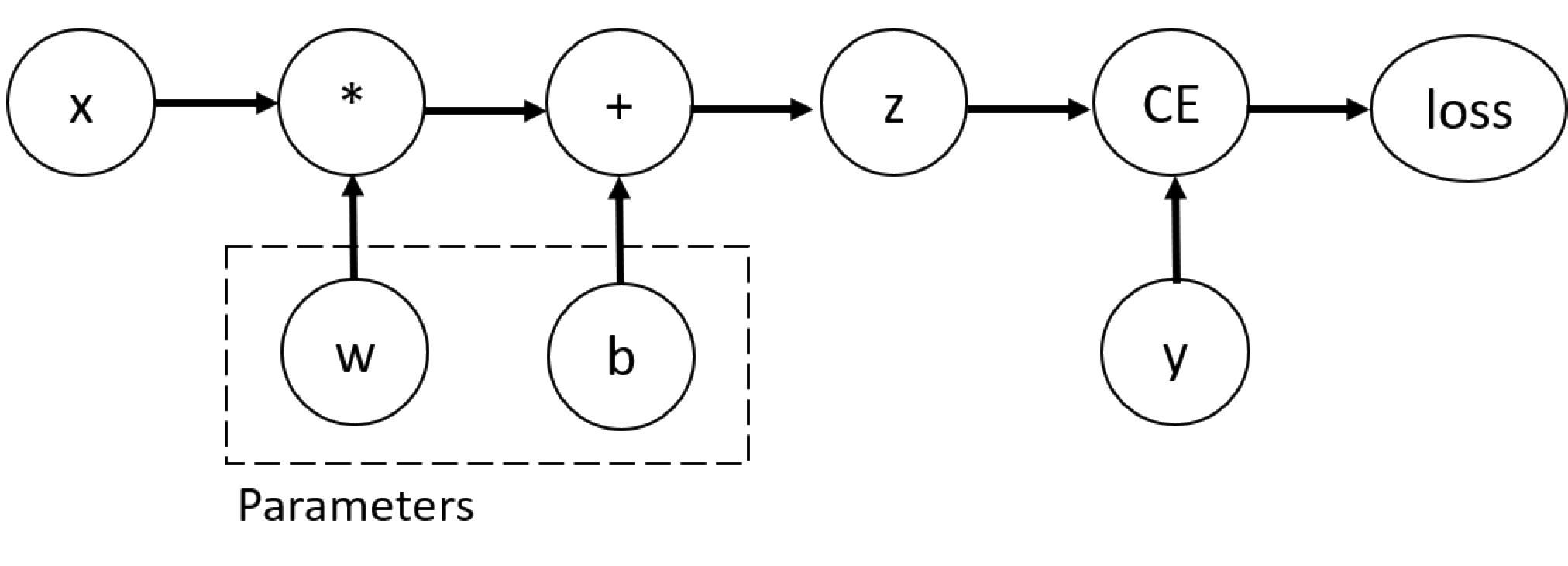
使用Function 可以构造计算图,可以在计算正向的函数的同时在后向传播计算梯度,A reference to the backward propagation function is stored in grad_fn property of a tensor. You can find more information of Function in the documentation.
# 关于Function
print('gradient function for z=',z.grad_fn)
print('gradient function for loss=',loss.grad_fn)
'''
Gradient function for z = <AddBackward0 object at 0x00000280CC630CA0>
Gradient function for loss = <BinaryCrossEntropyWithLogitsBackward object at 0x00000280CC630310>
'''
需要根据固定的x和y计算
∂
l
o
s
s
∂
w
\frac{\partial loss}{\partial w}
∂w∂loss和
∂
l
o
s
s
∂
b
\frac{\partial loss}{\partial b}
∂b∂loss,为了计算上述两个导数,需要使用loss.backward(),结果就会返回w.grad和b.grad
loss.backward() # 只能保留一次图,如果需要对同一个图多次计算,需要加retain_graph=True属性
print(w.grad)
print(b.grad)
需要注意的是,grad只能计算计算图的叶子节点,也就是将requires_grad设置为True的点。对于其他节点,不能进行梯度的计算。另外,对于一个给定的图,只能使用backward计算一次梯度,如果想对同一个图执行多次梯度的计算,就需要给backward()方法增加retain_graph=True的属性。
默认情况下requires_grad=True的张量都在跟踪其计算历史,并支持梯度计算。但有时不需要后向传播,可以使用 torch.no_grad()方法或者detach()停止跟踪计算。
z = torch.matmul(x, w)+b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w)+b
print(z.requires_grad)
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
停止跟踪计算的原因:
- 将某些参数固定,常用于微调预训练模型
- 当不需要后向传播而只需要进行前向计算时加速计算。
计算图
自动微分将数据和所有操作保存在了一个由Function组成的有向无环图(DAG)中。在这个有向无环图中,叶子节点是输入的张量,根节点是输出的张量,通过跟踪从跟到叶子的图,就可以根据链路原则计算梯度了。
在前向传递中,自动微分做了两件事:
- 根据指定的操作计算结果
- 保留有向无环图中的梯度函数操作
当在根节点的自动微分上开始执行backward()操作时,后向传播开始,
- 根据每一个grad_fn计算梯度
- 将每一个梯度保留在grad属性中
- 根据链路法则,计算从叶子到根的导数。
每一次backward()执行后,就会建立一个新的图,这就比较方便控制模型的形状,大小和操作。
J
=
(
∂
y
1
∂
x
1
⋯
∂
y
1
∂
x
n
⋮
⋱
⋮
∂
y
m
∂
x
1
⋯
∂
y
m
∂
x
n
)
J=\left( \begin{array}{ccc} \frac{\partial y{1}}{\partial x{1}} & \cdots & \frac{\partial y{1}}{\partial x{n}}\\ \vdots & \ddots & \vdots\\ \frac{\partial y{m}}{\partial x{1}} & \cdots & \frac{\partial y{m}}{\partial x{n}} \end{array} \right)
J=⎝⎜⎛∂x1∂y1⋮∂x1∂ym⋯⋱⋯∂xn∂y1⋮∂xn∂ym⎠⎟⎞
inp = torch.eye(3, requires_grad=True)
out = (inp+1).pow(2) # y = (x+1)^2, y' = 2(x+1)
out.backward(torch.ones_like(inp), retain_graph=True)
print("First call\n", inp.grad)
out.backward(torch.ones_like(inp), retain_graph=True)
print("\nSecond call\n", inp.grad)
inp.grad.zero_()
out.backward(torch.ones_like(inp), retain_graph=True)
print("\nCall after zeroing gradients\n", inp.grad)
line1: i n p = ( 1 0 0 0 1 0 0 0 1 ) inp=\left(\begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right) inp=⎝⎛100010001⎠⎞
line2: o u t = ( 4 1 1 1 4 1 1 1 4 ) out=\left(\begin{array}{ccc} 4 & 1 & 1 \\ 1 & 4 & 1 \\ 1 & 1 & 4 \end{array}\right) out=⎝⎛411141114⎠⎞, i n p = ( 1 0 0 0 1 0 0 0 1 ) inp=\left(\begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right) inp=⎝⎛100010001⎠⎞
line3: i n p . g r a d = ( 4 2 2 2 4 2 2 2 4 ) inp.grad=\left(\begin{array}{ccc} 4 & 2 & 2 \\ 2 & 4 & 2 \\ 2 & 2 & 4 \end{array}\right) inp.grad=⎝⎛422242224⎠⎞ y’=2(x+1)
line5: o u t = ( 4 1 1 1 4 1 1 1 4 ) out=\left(\begin{array}{ccc} 4 & 1 & 1 \\ 1 & 4 & 1 \\ 1 & 1 & 4 \end{array}\right) out=⎝⎛411141114⎠⎞, i n p = ( 1 0 0 0 1 0 0 0 1 ) inp=\left(\begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right) inp=⎝⎛100010001⎠⎞没有变化!
line6: i n p . g r a d = ( 8 4 4 4 8 4 4 4 8 ) inp.grad=\left(\begin{array}{ccc} 8 & 4 & 4 \\ 4 & 8 & 4 \\ 4 & 4 & 8 \end{array}\right) inp.grad=⎝⎛844484448⎠⎞
这次可以看出来,inp.grad是两次的梯度之和,这是因为在做反向传播时,PyTorch会对梯度进行累加,即计算出的梯度的值被添加到计算图的所有叶子节点的grad属性中。如果你想计算正确的梯度,你需要在此之前将grad属性归零。在现实训练中,优化器可以帮助我们做到这一点。
line7: i n p . g r a d = ( 0 0 0 0 0 0 0 0 0 ) inp.grad=\left(\begin{array}{ccc} 0 & 0 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 0 \end{array}\right) inp.grad=⎝⎛000000000⎠⎞ 将梯度归零
line8: o u t = ( 4 1 1 1 4 1 1 1 4 ) out=\left(\begin{array}{ccc} 4 & 1 & 1 \\ 1 & 4 & 1 \\ 1 & 1 & 4 \end{array}\right) out=⎝⎛411141114⎠⎞, i n p = ( 1 0 0 0 1 0 0 0 1 ) inp=\left(\begin{array}{ccc} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{array}\right) inp=⎝⎛100010001⎠⎞, i n p . g r a d = ( 4 2 2 2 4 2 2 2 4 ) inp.grad=\left(\begin{array}{ccc} 4 & 2 & 2 \\ 2 & 4 & 2 \\ 2 & 2 & 4 \end{array}\right) inp.grad=⎝⎛422242224⎠⎞ 归零后结果正确
循环优化
训练一个模型是一个迭代的过程,在每个epoch中,模型对输出进行猜测,计算测测中的损失,收集误差对其参数的导数,并使用梯度下降进行优化。与后向传播相关的知识可看3Blue1Brown
设置超参数
超参数是使训练人员控制模型优化过程的可调节的参数。不同的超参数值可以影响模型训练和收敛速度。常见的训练过程中的超参数有:epoch数量、batch size、 学习率。其中学习率指的是在每个batch或者epoch中更新模型参数的数量。较小的值产生慢的学习速度,而大量值可能会导致训练期间不可预测的行为。
一个常见的训练超参数设置
learning_rate = 1e-3
batch_size = 64
epochs = 5
一旦设置好超参数,就可以训练优化模型了。优化循环的每一次迭代叫做一个epoch,每个epoch包括两个部分:训练部分、验证/测试部分,前者是为了在训练集中收敛获得最优参数,后者是为了检验模型的效果是否在验证集上有所提升。
为此,损失函数是衡量获得的结果和目标值之间不相似的程度的量,训练的目标是令loss减少。
比较常见的损失函数有nn.MSELoss(用于回归任务),nn.NLLLoss(negative log likelihood,用于分类任务),nn.CrossEntropyLoss结合了nn.LogSoftmax和nn.NLLLoss
# 初始化
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
nn.ReLU()
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
learning_rate = 1e-3
batch_size = 64
epochs = 5
# 初始化损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器,用来在每一次训练步中调整模型参数,减少模型误差。优化的算法定义了应用了什么算法,常见的有SGD(随机梯度下降)、ADAM 和 RMSProp等。
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
优化器,用来在每一次训练步中调整模型参数,减少模型误差。优化的算法定义了应用了什么算法,常见的有SGD(随机梯度下降)、ADAM 和 RMSProp等。
在训练的循环中,优化主要执行三个步骤:
- 重置模型参数梯度,唤醒optimizer.zero_grad()方法在每次迭代时将梯度归零;
- 通过调用loss.backwards()反向传播预测损失,保存相应的参数;
- 有梯度后调用optimizer.step()调整参数。
#应用
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader): # batch为从0开始的序数,X、y为包含64条记录的一个batch
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# 后向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0: # 每6400条数据计算一次loss
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
size = len(dataloader.dataset)
test_loss, correct = 0, 0
with torch.no_grad(): #梯度归零
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= size
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
可以通过增加训练轮次或增大学习率改善效果
保存和加载模型
保存加载模型权重
model = model.vgg16(pretrained=True)
torch.save(model.state_dict(),path)
model = models.vgg16() # 不特设pretrained=True, i.e. 不加载默认权重
model.load_state_dict(torch.load('data/model_weights.pth'))
model.eval() # 非常重要,在设置dropout和batch normalization层前,需要确保一定有model.eval()
'''
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
'''
为了加载模型权重,需要首先创建一个相同的模型实例,然后使用load_state_dict()加载参数。
保存和加载模型形状
加载模型权重时,需要首先实例化模型的类,因为类定义了一个网络的结构。
保存时不仅要保存模型,还想要同时保存类的结构,这样我妈能将模型传递给保存的函数。
# 保存
torch.save(model, 'data/vgg_model.pth')
# 加载
model = torch.load('data/vgg_model.pth')














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









