







SciPy是一个常用的开源Python科学计算工具包,开发者针对不同领域的特性发展了众多的SciPy分支,统称为scikits,其中以scikit-learn最为著名,经常被运用在数据挖掘建模以及机器学习领域。
一.分类方法
1.Logistic回归
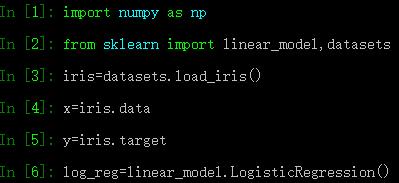
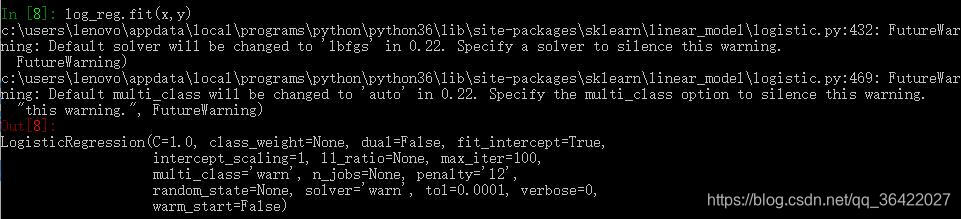

scikit-learn中的Logistic回归在sklearn.linear_model.LogisticRegression类中实现,支持二分类(binary)、一对多分类(one vs rest)以及多项式回归,并且可以选择L1或L2正则化。
从 Warning 信息中得知,原因是 sklearn 的新版本中,OneHotEncoder 的输入必须是 2-D array,而 data_train[‘Fare’] 返回的 Series 本质上是 1-D array,所以要将
df[‘Fare_scaled’] = scaler.fit_transform(data_train[‘Fare’])
改成
df[‘Fare_scaled’] = scaler.fit_transform(data_train[[‘Fare’]])
也就是在data_train[[‘Fare’]]外面再加一个[]
2.SVM
SVC、NuSVC、LinearSVC都能够实现多元分类,其中SVC和NuSVC比较接近,两者的参数略有不同,LinearSVC如其名字所写,仅支持线性核函数的分类。
SVC、NuSVC、LinearSVC示例:
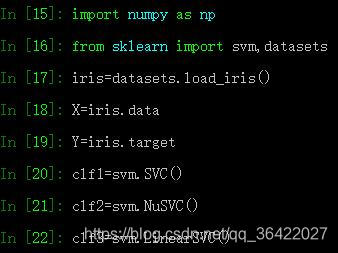
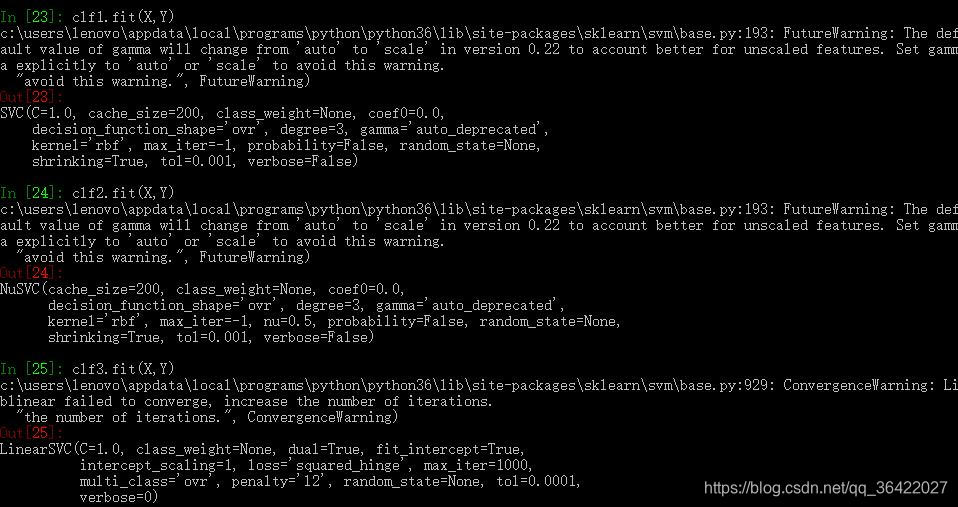
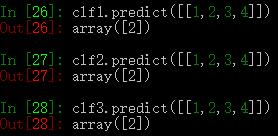
3个参数获取clf1的支持向量:
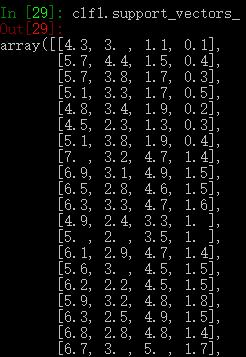


support_vectors_参数获取支持向量机的全部支持向量,support_参数获取支持向量的索引,n_support_获取每一个类别的支持向量的数量。
3.Nearest neighbors
scikit-learn实现了两种不同的最近邻分类器KNeighbordClassifier和RadiusNeighborsClassifier。其中,KNeighborsClassifier基于每个查询点的k个最近邻实现,k是用户指定的整数值;RadiusNeighborsClassifier基于每个查询点的固定半径r内的邻居数量实现,r是用户指定的浮点数值。两者相比,前者的应用更多。
最近邻分类示例:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1931
1931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









