







分布式大数据处理系统概览(二)
本博文主要对现如今分布式大数据处理系统进行概括整理,相关课程为华东师范大学数据科学与工程学院《大数据处理系统》,参考大夏学堂,下面主要整理HDFS/MapReduce/Spark/Yarn/Zookeeper/Storm/SparkStreaming/Lambda/DataFlow/Flink/Giraph有关的内容。
分布式大数据处理系统大纲
- 分布式大数据处理系统概览(一):HDFS/MapReduce/Spark
- 分布式大数据处理系统概览(二):Yarn/Zookeeper
- 分布式大数据处理系统概览(三):Storm/SparkStreaming
- 分布式大数据处理系统概览(四):Lambda/DataFlow/Flink/Giraph
6 资源管理系统Yarn
6.1背景:
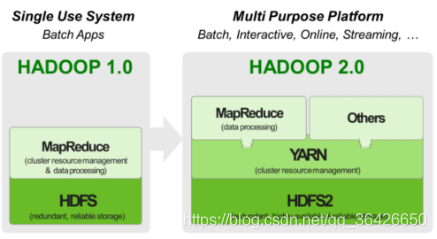
(1)MapReduce1.0的缺点:资源管理与作业紧密耦合;作业控制管理高度集中(JobTracker存在单点故障风险,JobTracker“大包大揽”内存开销大)
(2)1.0中MapReduce既是计算系统,又是资源管理系统,而2.0中Yarn是独立出来的资源管理系统。
6.2 Yarn体系架构
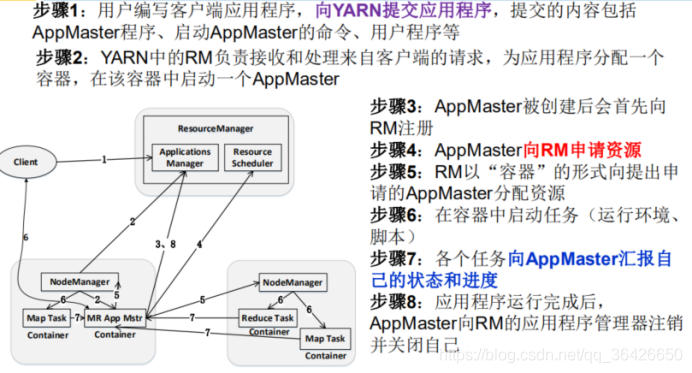
(1)ResourceManager(RM):是全局的资源管理器,包括:
# 资源调度器(Result Schedule):资源分配;
# 应用程序管理器(Application Manager):所有应用程序的管理工作
(2)NodeManager(NM):
# NodeManager管理一个YARN集群中的每个节点。NodeManager提供针对集群中每个节点的服务,监控资源使用情况,健康状况;
# 向ResourceManager反馈资源使用情况和每个容器的运行状态;
# 负责管理抽象的容器
(3)ApplicationManager(AM):
# 与RM进行交互,协商获取资源,并把资源分配给内部的任务;定时向RM报告资源使用情况和应用进度信息;作业完成后向RM注销容器
# 与NM保持通信进行应用程序的管理
# 监控任务的执行进度和状态
(4)Container容器:动态资源分配单位,封装了CPU内存等资源,用于执行计算任务
6.3 Yarn工作原理
(1)生命周期:
(2)资源分配:
# RM调度器Result Schedule维护一个或多个应用队列,每个队列含有一定量的资源,同一个队列内的应用共享同一个资源;
# Yarn进行资源分配的对象是应用,用户提交的应用保存在队列中,队列决定应用使用的资源上限;
# 资源分配的实质是决定如何将资源分配给不同的队列,如何将队列的资源分配给不同的应用。
6.4 Yarn容错
(1)Resource Manager故障:持久化存储系统恢复状态信息;
(2)Node Manager故障:RM认为该结点上的所有任务全部执行失败,AM将向RM重新申请资源,并由RM重新分配其他结点执行对应的任务;如果故障的结点恢复,则向RM重新注册,并恢复状态。
7 协调服务系统ZooKeeper
7.1 ZooKeeper 简介:轻量级的分布式系统
(1)作用:用于解决分布式应用中通用的协作问题
(2)用途:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理
7.2 ZooKeeper设计思想:
(1)ZooKeeper维护一个类似文件系统的数据结构;
(2)子目录项称为Znode,能够自由的增删改;
(3)Znode四种类型:

(4)监听通知机制:客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端;
(5)用处:假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
7.3 ZooKeeper系统架构
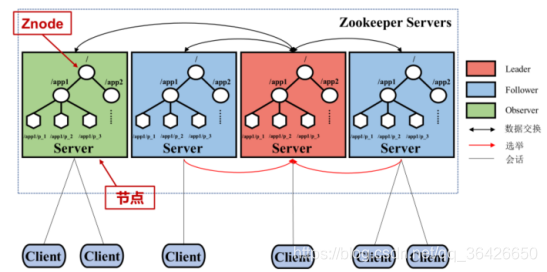
(1)服务器Server:每个服务器(节点)维护一个树形结构,其包含:
# 领导者Leader:根据算法选举其中一个节点为领导者,可直接为客户端执行读写操作;
# 追随者Follower:仅提供读操作,写操作需要转发给领导者,可参与选择领导者;
# 观察者Observer:与追随者一样,但不可参与选举领导者;服务器中可没有观察者节点
(2)会话机制:
# 客户端Client:可以在某个Znode上设置Watcher监听Znode变化;一旦发生变化,则通知客户端
# SEESION机制
7.4 ZooKeeper工作原理
(1)为什么选择领导者?

(2)选举领导者过程:

(3)写操作流程:
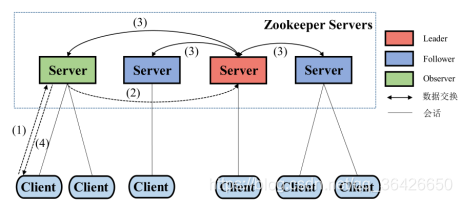
# step1:客户端与某一服务建立连接;
# step2:若该服务器是追随者或观察者,则将收到的写请求转发给领导者;
# step3:使用分布式一致协议保证每个服务器的数据一致
# step4:数据返回
(4)读请求流程:
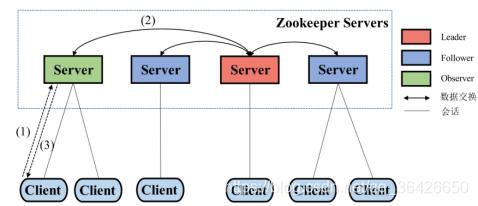
# 当客户端发起读请求时,所有服务器均可以执行;
# 数据同步:在读取之前,与领导者保持数据同步;
# 数据返回:领导者返回的数据是最新的,其他服务器返回的结果可能不是最新的,需要进行数据同步;
7.5 ZooKeeper容错
(1)领导者故障:需要重获进行领导选举;
(2)追随者或观察者节点故障:不影响ZooKeeper服务
7.6 ZooKeeper功能应用
(1)命名管理:统一命名服务:树形的名称结构
(2)配置管理:配置信息存在ZooKeeper的某个目录节点上,所有机器watch该目录节点,一旦发生变化,每台机器收到通知,然后获取新的配置信息到应用系统中;
(3)集群管理:监控集群中slave状态;从多个master中选择领导者
分布式大数据处理系统大纲
- 分布式大数据处理系统概览(一):HDFS/MapReduce/Spark
- 分布式大数据处理系统概览(二):Yarn/Zookeeper
- 分布式大数据处理系统概览(三):Storm/SparkStreaming
- 分布式大数据处理系统概览(四):Lambda/DataFlow/Flink/Giraph
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。喜欢请关注+点赞o( ̄▽ ̄)d















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











