









论文解读:FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | FASPell |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 中文拼写纠错 |
| 4 | 核心内容 | 图表征,语言模型 |
| 5 | GitHub源码 | https://github.com/iqiyi/FASPell |
| 6 | 论文PDF | https://aclanthology.org/D19-5522.pdf |
动机:
- 近年来拼写错误在英文上得以应用,但由于英文与中文在语义和语法上的差异性,在你英文上的方法无法直接用在中文上;
- 先前的中文拼写纠错建立在confusion set(相似字符集合),filter从候选字符中挑选最佳的字符,但其依然有两个问题:(1)在数据资源不足时候容易过拟合;(2)使用confusion set并不灵活和有效
inflexibility to address the issue that confusing characters in one scenario may not be confusing in another.
insufficiency in utilizing character similarity.
- 优势:提出的方法更加快,更加自适应,更加简单以及更加健壮。
方法:
本文提出一种FASPell模型,包含Denoising Autoencoder(DAE)和Decoder模块,遵循Encoder-Decoder架构。其中Masked Language Model(MLM)作为DAE模块来生成candidate,Confidence-similarity Decoder则用来过滤candidate。
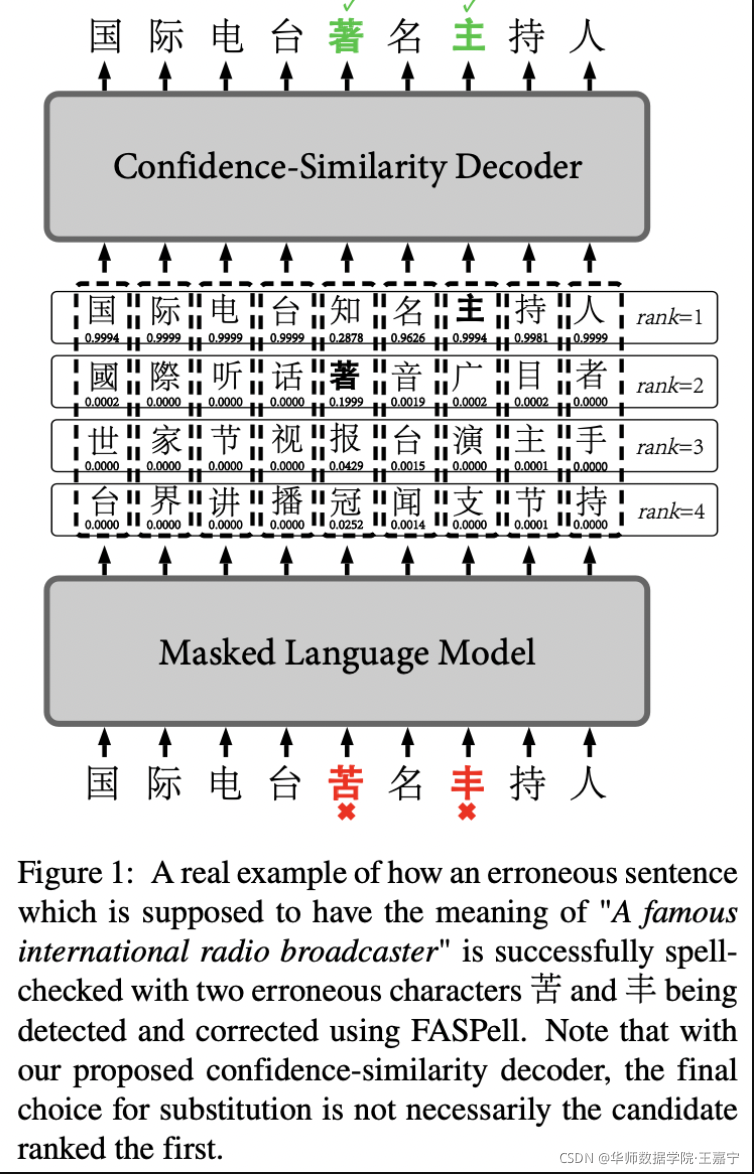
Masked Language Model
MLM是BERT中的一个任务,给定一个文本,80%的token被替换且[MASK],10%的token被替换为其他token,剩余10%保持不变。MLM的任务则是预测[MASK]对应的token。可以换一个角度来理解MLM,如果将[MASK]token当作错误的拼写,则MLM恰巧就是取纠正这个错误。而还有一部分的token是保持不变的,即还需要模型能够检测token是否是错误的拼写。因此MLM兼具拼写检测和纠正两个作用。
考虑到随机mask的token与真实场景下的错误拼接是有差距的,因此本文提出在拼写检测数据集上的微调方法:
- 如果给定的文本不存在错误拼写,则按照原来的MLM训练;
- 如果给定的文本存在错误拼写。有两种生成训练数据方法:(1)对于错误的拼写token,将其mask掉,并将label对应于真实的token;(2)为了避免过拟合,对没有拼写错误的token进行mask掉,并将label对应于这个token。
Character Similarity
作者认为MLM起到的作用并非强大,因此有必要添加一个decoder。
错误的中文字符通常与正确的字符存在视觉和发音的相似性,而在OCR任务中则偏向于视觉相似性。
visual similarity
在视觉相似性中,通常选择表意描述序列(Ideographic Description Sequence (IDS))来表示字符的字形,本质上是有序树的前序遍历路径。
对字形进行计算时主要采用CJK字的细粒度IDS表示
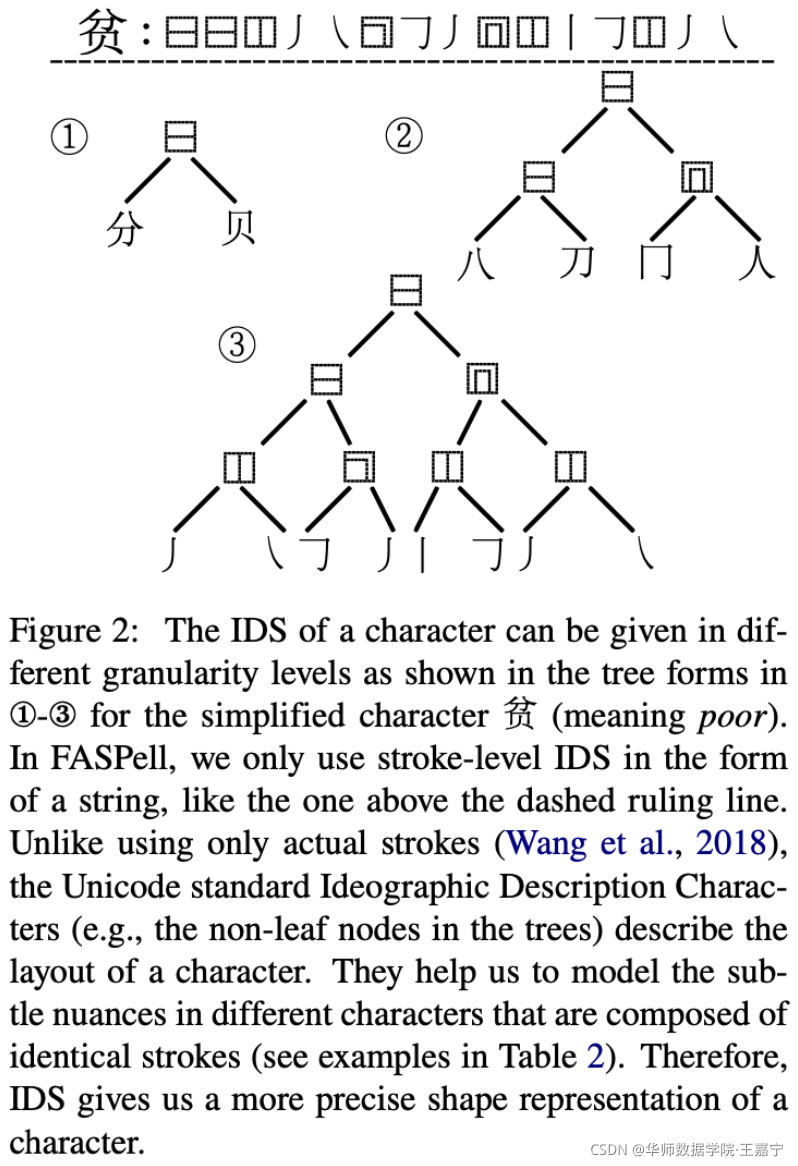
在定义视觉相似性,本文只使用IDS,两个字符之间的相似性则使用1减去正则化的IDS序列Levenshtein编辑距离来表示。
- 此时相似性值在0-1之间;
- 如果一对较复杂的字符与一对较不复杂的字符具有相同的编辑距离,我们希望较复杂字符的相似度略高于较不复杂字符的相似度
Phonological Similarity
本文利用字符的发音相似性。两个字符之间的发音相似性则使用1减去正则化的音标序列Levenshtein编辑距离来表示。
考虑到中文同音字的影响,在进行字音相似度计算时采用了汉字在普通话(MC)、粤语(CC)、日语(JO)和韩语(K)中的不同发音共同进行字音相似度的计算。

Confidence-Similarity Decoder(CSD)
传统的candidate filter方法是为多个候选字符的特征设置不同的阈值和权重。而本文则使用confidence-similarity decoder(结合上下文置信度和字符相似性)
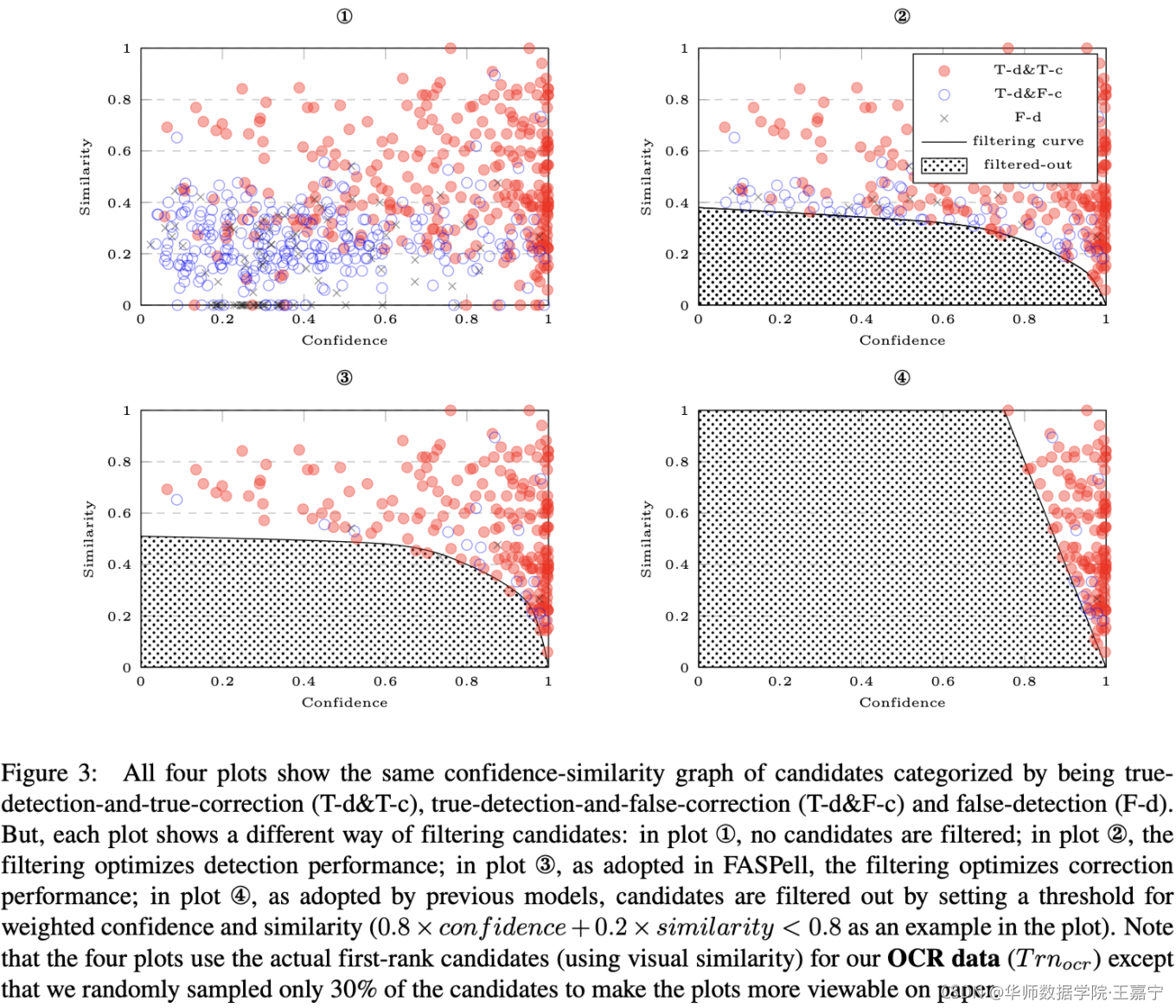
如上图,对于所有候选的candidate,可以获得相应的confidence score和character similarity。2-4则是三种过滤曲线。
In FASPell, we optimize correction performance and manually find the filtering curve using a training set, assuming its consistency with its corresponding testing set. But in practice, we have to find two curves – one for each type of similarity, and then take the union of the filtering results.
在 FASPell 中,我们优化校正性能并使用训练集手动找到过滤曲线,假设其与相应的测试集一致。 但在实践中,我们必须找到两条曲线——每种相似度都对应一条曲线,然后取过滤结果的并集。
请注意,使用提出的置信相似度解码器,替换的最终选择不一定是排名第一的候选者。
理解:利用训练集文本通过MLM输出的矩阵,逐行绘制语境把握度-字符相似度散点图,确定能将FP和 TP分开的最佳分界曲线。推理阶段,逐行根据分界线过滤掉FP得到TP结果,然后将每行的结果取并集得到最终替换结果。
以图1为例,句子首先通过fine-tune训练好的MLM模型,得到的候选字符矩阵通过CSD进行解码过滤,第一行候选项中只有“主”字没有被CSD过滤掉,第二行只有“著”字未被过滤掉,其它行候选项均被分界线过滤清除,得到最终输出结果,即“苦”字被替换为为“著”,“丰”被替换为“主”。
实验
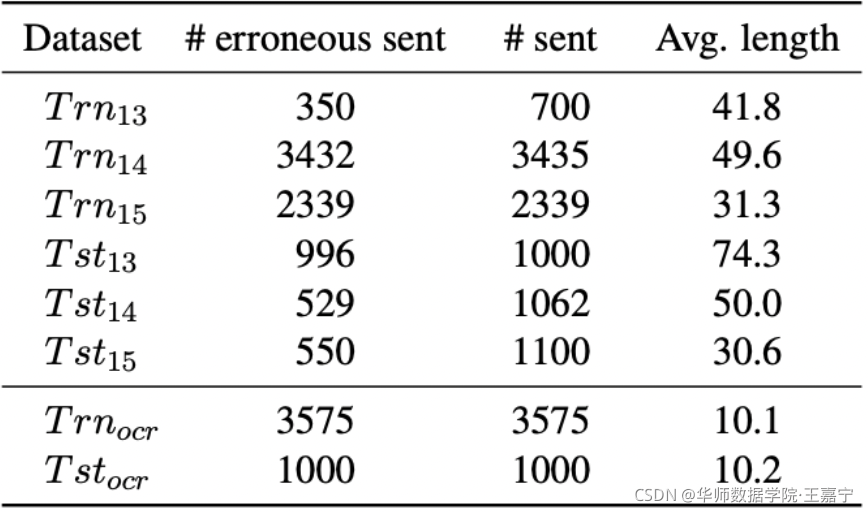
数据集:
实验设置: 使用BERT的预训练MLM,超参数则与BERT一致;
在OCR识别的数据集上,不使用MLM的Fine-tuning;
评价指标:
选择Acc、Recall和F1作为评价指标,在detection和correction分别进行评测。
实验结果:
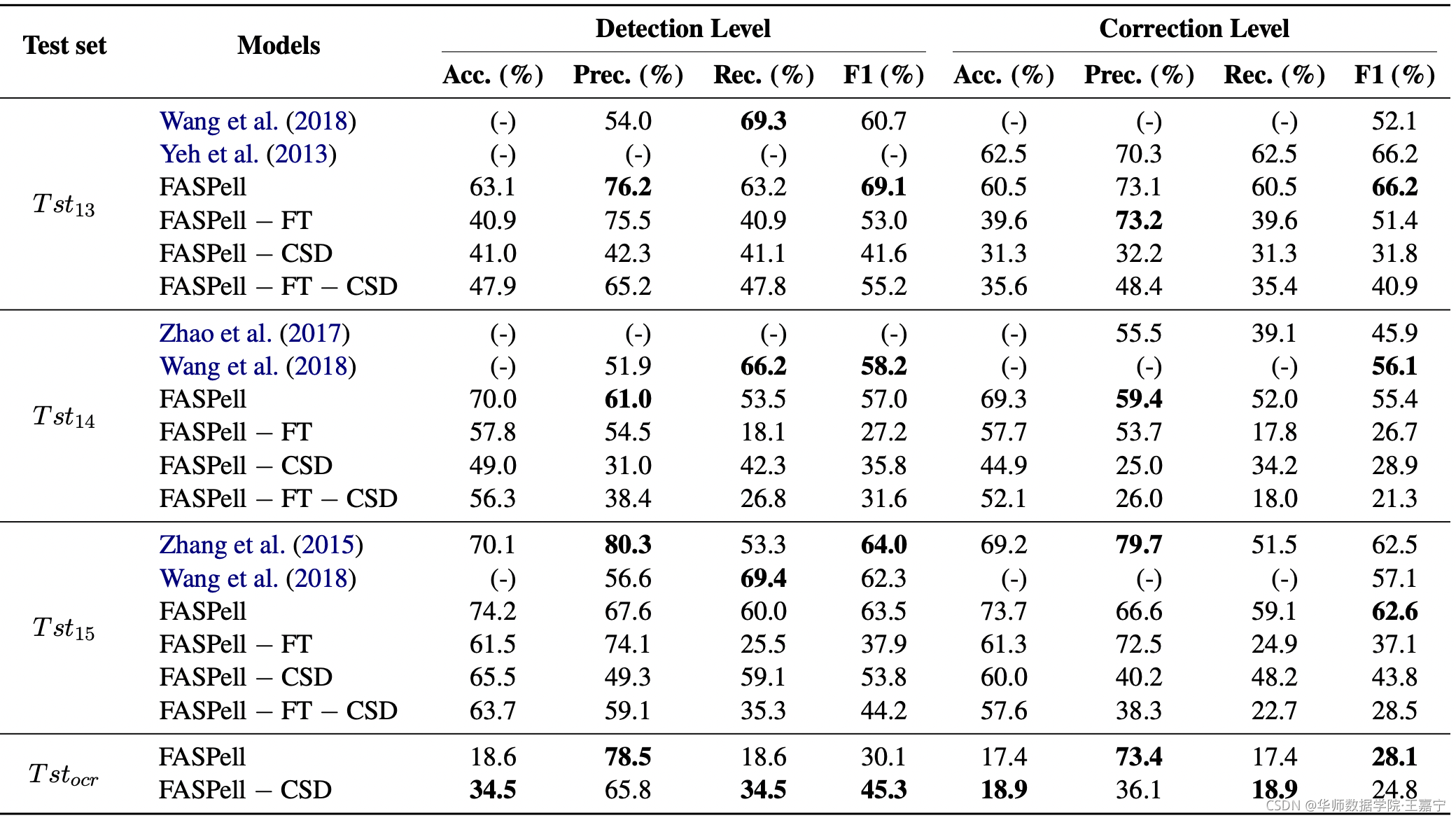
优点: 使用MLM预测候选,生成的方式替代了pt表,整个流程非常简单,需要的标注数据也很少,排序时使用字音字形特征,尤其是字音使用多种汉字发音,可解释性也比较好。
缺点: 只能解决错字场景,多字/少字/乱序场景不支持(这种一般都是实体类型,可单独解决)


















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











