









python爬取强智科技教务系统,以江苏科技大学为例:本人开发的系统作为参考:https://www.wjn1996.cn/estudy/tools/educationLogin.jsp?school=10289&search=1
以本人账号为例:
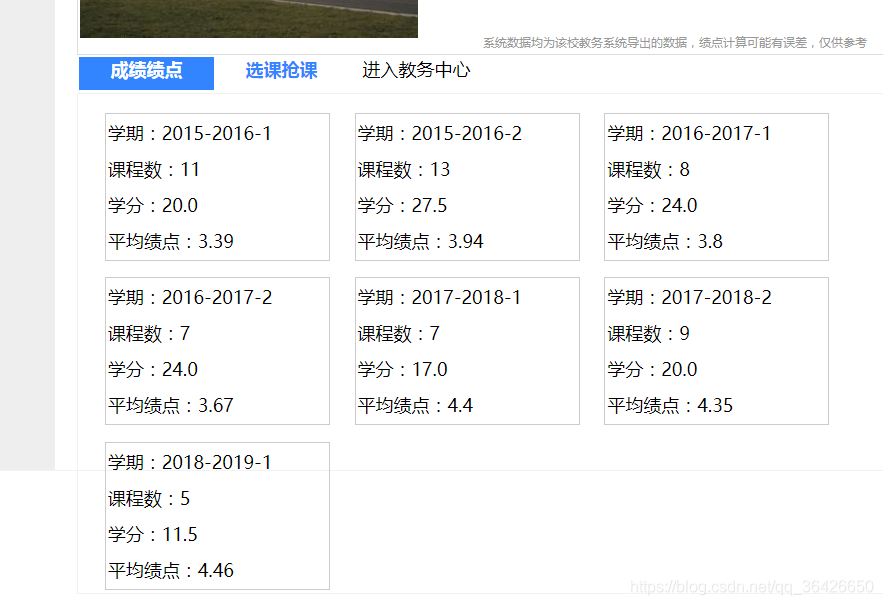
程序如下,保存为test.py,cmd命令执行python3 test.py+学号+密码。可返回所有成绩列表。
import urllib
import urllib.request
import urllib.parse
import http.cookiejar
PostUrl = "http://jwgl.just.edu.cn:8080/jsxsd/xk/LoginToXk"
cookie = http.cookiejar.CookieJar()
hander = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(hander)
headers ={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.8',
'Content-Type':'application/x-www-form-urlencoded',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
PostData = {
'USERNAME':'******',#'这里填写学号
'PASSWORD':'******'#这里填写密码
}
data = urllib.parse.urlencode(PostData).encode(encoding = 'utf-8')
request = urllib.request.Request(PostUrl,data,headers)
response = opener.open(request)
result = response.read().decode('utf-8')
#print(result)
res = opener.open('http://jwgl.just.edu.cn:8080/jsxsd/kscj/cjcx_list')
#print(res.read().decode('utf-8'))
from bs4 import BeautifulSoup
html_text = BeautifulSoup(res.read().decode('utf-8'),'html.parser')
td = html_text.select('td')
all_test_list = []
list = []
for i in td:
if i.text != '':
list.append(i.text)
else:
if len(list)>0:
all_test_list.append(list)
list = []
continue
#print (i.text)
#print(all_test_list)
for i in all_test_list:
print(i)#这里输出每一个课程的成绩list
# print(i[3] , i[4])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











