







一、背景
最近有个同事对字符串加索引,加完后,发现多了个奇奇怪怪的数字
执行的SQL如下:
alter table string_index_test add index `idx_name` (`name`) USING BTREE;
这个奇怪数字就是191,它很是疑惑,也没指定索引的长度

通过查看MySQL官方文档
InnoDB has a maximum index length of 767 bytes for tables that use COMPACT or REDUNDANT row format, so for utf8mb3 or utf8mb4 columns, you can index a maximum of 255 or 191 characters, respectively. If you currently have utf8mb3 columns with indexes longer than 191 characters, you must index a smaller number of characters.
In an InnoDB table that uses COMPACT or REDUNDANT row format, these column and index definitions are legal:
col1 VARCHAR(500) CHARACTER SET utf8, INDEX (col1(255))
To use utf8mb4 instead, the index must be smaller:
col1 VARCHAR(500) CHARACTER SET utf8mb4, INDEX (col1(191))
大概意思就是InnoDB最大索引长度为 767 字节数,用的编码是utf8mb4,则可以存储191个字符(767/4 约等于 191),编码字段长度超出最大索引长度后MySQL 默认在普通索引追加了191
二、思考
1、MySQL中如何提高字符串查询效率?
可以对字符串加索引,但一般情况下,是不建议在字符串加索引,占空间。
如果一定要加,建议指定长度,而且前提是字符串前面部分的区分度比较好,这类索引叫前缀索引。
2、前缀索引有什么问题?
如果前面部分区分度不好的话,很容易发生碰撞,进而引发一系列问题
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上
如何看区分度?
可以使用 count(distinct left(列名, 索引长度))/count(*) 来确定区分度
我们通过执行计划来分析一波
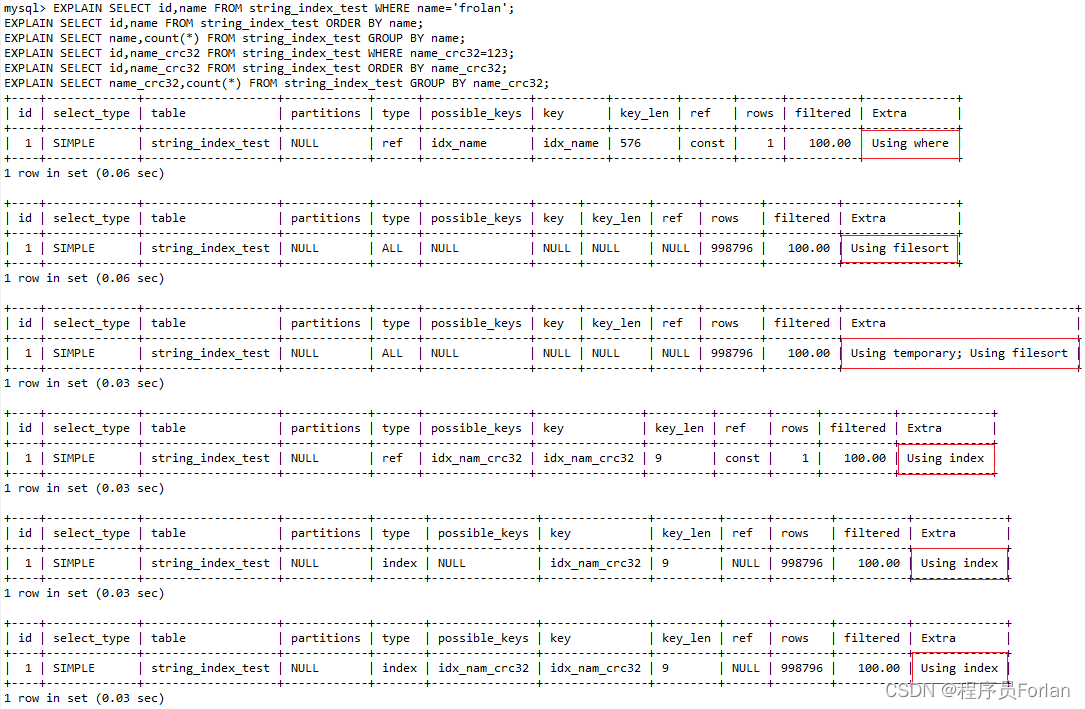
上面分别演示了前缀索引和普通索引在where条件、order by和group by的执行情况。
通过Extra的信息,得出结果:前缀索引只有where条件,无法使用覆盖索引,order by会使用filesort,group by会使用temporary和filesort
总的来说,前缀索引无法使用覆盖索引,进而导致order by和group by要使用文件排序、临时表。
那么前缀索引又有这么些问题,指定长度不行,不指定长度也不行,怎么处理?往下看~
3、利用额外字段
加一个name_crc32列,定义为整型,索引空间小很多,加速查询
CRC全称为Cyclic Redundancy Check,又叫循环冗余校验。
CRC32是CRC算法的一种,返回值的范围0~2^32-1,使用bigint存储
三、性能比较
准备了单表100W的数据进行测试
使用性能压力测试工具mysqlslap
性能测试脚本
mysqlslap -uroot -p --concurrency=100,200 --iterations=1 --number-of-queries=200 --create-schema=test --query=C:\xxx\query.sql
参数说明:
- –concurrency=100,200:指定并发连接数,第一次100,第二次200
- –iterations=1:指定执行次数,这里表示只执行1次
- –number-of-queries=200:指定总查询次数,这样每个连接的查询数=number-of-queries/concurrency
- –create-schema=test:指定查询的数据库test
1、不加索引
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name=‘forlan’;
测试结果如下:
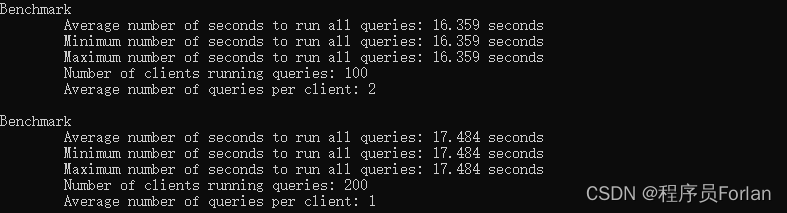
100并发查询耗时16.359秒,200并发查询耗时17.484秒
2、加字符串索引
加字符串索引:alter table string_index_test add index idx_name (name) USING BTREE;
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name=‘forlan’;
测试结果如下:

100并发查询耗时0.297秒,200并发查询耗时1.563秒
3、使用CRC32创建索引
加普通索引:alter table string_index_test add index idx_nam_crc32 (name_crc32) USING BTREE;
查询的SQL:SELECT SQL_NO_CACHE * FROM string_index_test WHERE name_crc32=CRC32(‘forlan’) and name=‘forlan’;
因为CRC32存在发生碰撞,所以加上name条件,才能筛选出正确的数据
测试结果如下:
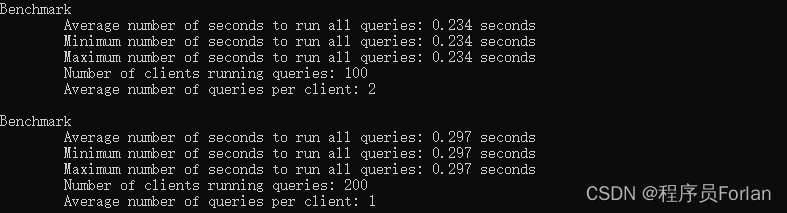
100并发查询耗时0.234秒,200并发查询耗时0.297秒
四、总结
- 通过对字符串加索引,可以提高查询效率,但需要注意指定长度,无法使用覆盖索引
- 通过使用CRC32,需要额外存一个字段,将字符串转为整数存储,节省空间,效率提升并不是很大,但存在碰撞问题,可以加多字符串筛选条件
- 对于CRC32存在碰撞问题,可以使用CRC64减少碰撞,但需要额外安装 common_schema database函数库
















 2352
2352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











