







Homework
专业班级:计算机科学与技术165班
课程名称:云计算技术
1. HDFS is implemented as a user-level file system vs an in-kernel file-system. (a) What is the advantage of this in the context of Hadoop?
(1)可以存储数据量较大的文件,比如GB,TB,PB级别的海量数据。
(2)一次写入,多次夺取。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
(3).搭建在普通的商业集群机器上就可以了,节省成本。
(4).节约NameNode内存和外存空间。
2. The output of a Mapper is written into the local filesystem instead of the global filesystem. Why? Your answer should explain both why writing into the global file system would be undesirable as well as why it would be of minimal benefit.
- 减少网络流量使用,因为reducer可能与输出在同一台机器上运行,因此不需要复制。
不需要HDFS的容错能力。如果作业中途死亡,我们总是可以重新运行地图任务。 - 写入hdfs与写入本地磁盘不同。这是一个更复杂的进程,namenode确保至少将dfs.replication.min副本写入hdfs。并且namenode还将运行后台线程以为下复制的块创建其他副本。
假设,用户在两者之间杀死作业或者作业失败。hdfs上会有很多中间文件无缘无故你必须手动删除。如果此过程发生的次数过多,则您的群集会执行并会降级。Hdfs针对追加而非频繁删除进行了优化。
此外,在映射阶段,如果作业失败,它会在退出之前执行清理。如果它是hdfs,则删除过程将要求namenode将块删除消息发送到适当的数据节点,这将导致该块的失效并将其从blocksMap中删除。如此多的操作只涉及清理失败而无法获得!
3. Why does Hadoop sort records en route to a Reducer? How would it affect things if these records were processed by the Reducer in the order in which they were received from the various Mappers?
- 一个MapReduce作业由Map阶段和Reduce阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce框架本质就是一个Distributed Sort。在Map阶段,Map Task会在本地磁盘输出一个按照key排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在Reduce阶段,每个Reduce Task会对收到的数据排序,这样,数据便按照Key分成了若干组,之后以组为单位交给reduce()处理。很多人的误解在Map阶段,如果不使用Combiner便不会排序,这是错误的,不管你用不用Combiner,Map Task均会对产生的数据排序(如果没有Reduce Task,则不会排序, 实际上Map阶段的排序就是为了减轻Reduce端排序负载)。由于这些排序是MapReduce自动完成的,用户无法控制,因此,在hadoop 1.x中无法避免,也不可以关闭,但hadoop2.x是可以关闭的。
4. How is the failure of a Mapper or Reduce managed?
分析:实际情况下,用户代码存在软件错误、进程崩溃、机器故障等都会导致失败。Hadoop判断的失败有不同级别类型,针对不同级别的失败有不同的处理对策,这就是MapReduce的容错机制。下面是几个不同级别失败的分类:
一、任务失败
分为3种情况:Task失败、子进程JVM退出、超时检测被关闭。
1.任务失败。最常见的是Map或Reduce任务的失败,即写的本身MR代码导致失败。发生Map或Reduce失败的时候,子任务JVM进程会在退出之前向上一级TaskTracker发送错误报告。错误报告最后悔记录在用户的错误日志里面,TaskTracker会将此次task attempt标记为failed,释放一个任务槽slot用来运行另一个任务。
2. 子进程JVM突然退出。可能由于JVM的bug导致,从而导致MapReduce用户代码执行失败。在这种情况下,TaskTracker会监控到进程以便退出,并将此次尝试标记为“failed”失败。
3. 关闭了超时连接(把超时timeout设置成0)。所以长时间运行的任务永不会被标记failed。在这种情况下,被挂起的任务永远不会释放其所占用的任务槽slot,并随时间推移会降低整个集群的性能。
二、TaskTracker失败
- 正常情况下,TaskTracker 会通过心跳向 JobTracker 通信,如果发生故障,心跳减少, JobTracker 会将TaskTracker 从等待任务调度的池中移除,安排上一个成功运行的 Map 任务返回。
主要有两种情况:
1.Map 阶段的情况。如果属于未完成的作业,Reduce 阶段无法获取本地 Map 输出的文件结果,任务都需要重新调度和执行,只要是Map阶段失败必然是重新执行这个任务。
2.Reduce 阶段的情况。自然是执行未完成的 Reduce 任务。因为 Reduce 只要执行完了就会把输出写到 HDFS 上。
三、JobTracker失败
- 最严重的情况就是 JobTracker 失败,并且这情况在单点故障时是最严重的,因为此情况下作业最终失败。
- 解决方案是启动多个 JobTracker ,只运行主 JobTracker ,其可以通过 ZooKeeper 来协调。
四、任务失败重试
-
当 MapTask 执行失败后会重试,超过重试次数(默认为4),整个Job会失败。
-
Hadoop 提供配置参数 mapred.max.ap.failures.percent 解决这个问题。如果一个 Job 有 200 个 MapTask ,参数设置为5,则单个 Job 最多允许 10 个 MapTask 失败(200×5%=10),其可以在配置文件 mapred-site.xml 里修改。
5. In a typical Map-Reduce graph algorithm, what data structure is used to represent the graph? Why?
介绍
MapReduce框架非常适合处理大规模的流数据,而图算法的实现一直是MapReduce的难点。已发表这方面的文章也不是特别多。根据“Graph Twiddling in a MapReduce world”,本文详细介绍了 四个图算法的实现,分别是图节点度计算,三元环检测,四元环检测,k-桁结构(k-trusses)检测。
图节点度计算
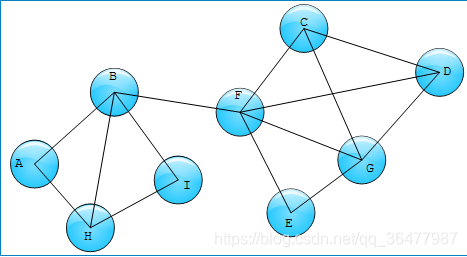
度是图节点最基本的特征,在hadoop中求节点度的方法比较简单。以图1为例,需要求其中各个节点的度。
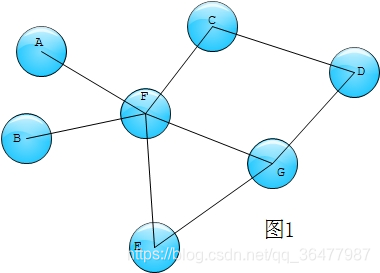
Hadoop算法实现非常简单,如下图2所演示
MapReduce-1: 分别以边的两个节点作为key,边作为键值输出,reducer阶段统计节点关联的边个数,同时输出边中相应节点的度;
MapReduce-2:以MapReduce-1的输出作为输入,reducer阶段合并边上两个节点的度。
三元环检测
这个开三元环闭合(即是否有一条边可以将链的两个端点闭合)。
这里有两个优化点,可以大大提供算法性能。 首先,为了降低计算复杂度,一个三元环,我们只输出一次。如果对三元环中节点排序(最简单的办法就是节点按字母排序),通过逆序或者旋转三元环的节点输出顺序只有一种(例如ABC,BAC, CBA, ACB… 都可以由ABC逆序或者旋转得到)。由于这个性质,每轮mapper reducer过程,输出时候保证节点是按顺序的。 其次,二次爆炸问题,当某一个节点度比较高的时候,那么通过这个节点边就会很多,进而形成的开三元环也会比较多(例如,节点A的度为N,那么通过节点A边有N条边,这N条边任意两条都可以形成一个开三元环,最终A节点将形成N(N-1)/2 个开三元环,当N很大时候性能会有很大影响)。一个解决办法是,使用度较小的节点为key做合并,这样数据被分散到度比较小的节点上。(结合上面的性质,三元环节点序是只有一种,所以不会出现有些三元环没找到的情况)。这两个优化点能大大提高算法性能。
我们以第一节中的图1为例,具体的hadoop算法 流程如下
流程如下

四元环检测
四元环检测基本思想与检测三元环类似。可以先找两个开三元环,如果两个开三元环连接相同的两个端点,那么这两个开三元环组成一个四元环。为了减少计算量,我们先分析一下四元环旋转和逆序的性质。先从三元环说起,前面已经提到了。假如三元环顶点有序,那么通过旋转和逆序三元环的顺序是唯一的(ABC,BCA,CAB,CBA,ACB,BAC都可以通过ABC旋转或者逆序得到)。对于四元环四个顶点(A,B,C,D),四个顶点的排列方式有4!=24中,但是通过旋转和逆序只有三种排列方式 (排序方法最简单就是按字母顺序排序)。
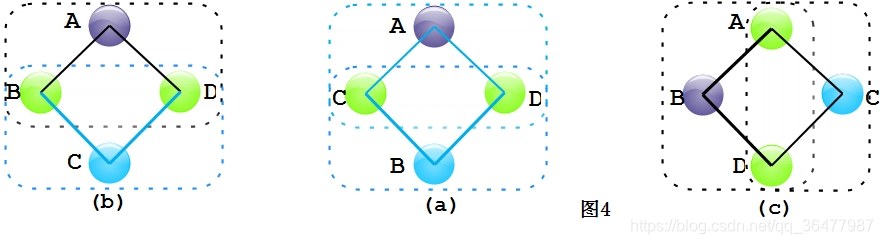
如图4所示,我们继续对上面四元环进行分析。根据其中三元环顶点与其邻居节点的关系,我们对上面三个四元环进行分类。首先(a)中两个开三元环(蓝色)的顶点(A,B)比它们相邻的节点(C,D)都小;(b)中两个开三元环(蓝色和黑色),黑色开三元环顶点小于它邻居节点,蓝色开三元环的顶点在邻居节点中间;(c)中两个开三元环(黑色),顶点都在邻居节点中间。所以四元环可以分解成两种三元环的组合:一种三元环,其顶点在两个邻居节点中间,一种三元环,其顶点比邻居节点小。通过这样的策略我们减少开三元环的输出,降低算法的复杂度,后面我们将看到这个策略的应用。
四元环检测算法如下:
a) mapper输入所有的边,分别以边节点为key,边为value的键值,同时对键值对进行标注,标记输出的节点的字母排序(或者其他排序)大小,例如,处理边AF时候, mapper输出值有两个键值对,<A,(AF),L> <F,(AF),H>。第一个值表示key A,键值 AF,L表示A < F (字母序); 第二个值表示key F,键值AF,H表示 F>A(字母序);
b) reducer 处理所有节点对应的开三元环 ,这里注意我们输出两种开三元环:(I)输出节点关联的任意两个L键值对组成的开三元环 (例如,图中C,F对应的两个L键值对,他们组成的开三元环都要输出。如果有三个对以上的L 键值,任意两对组成的开三元环都要输出);(II)输出节点任意一个L键值对和所有的H键值组成的开三元环(例如图中D,F节点)。 【这里就是为什么上面我们分析四元环的组成,因为任意一个四元环只能分解成,两种情况顶点小于两个相邻节点,顶点在两个相邻节点中间。两个L键值对表示的就是顶点小于两个相邻节点,一个L键值和一个H键值表示就是顶点在两个相邻节点中间】
c) 最后一个Reducer就是分析是否两个开三元环的顶点不一样,但是端点一致;是则是四元环;否则不是。
算法流程可以见下图5
k-trusses 结构检测
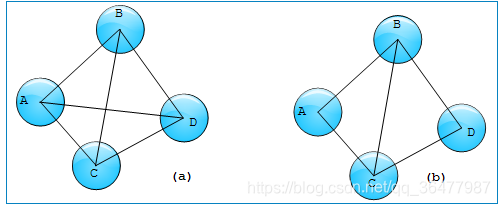
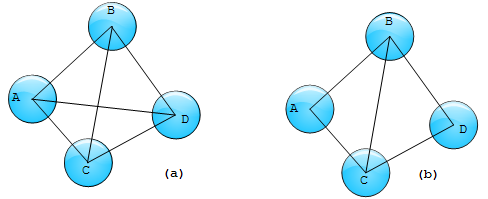
k-trusses 桁结构的定义是:a relaxation of a kmember clique and is a nontrivial, single-component maximal subgraph, such that every edge is contained in at least k -2 triangles in the subgraph. 具体理解,桁结构中是由三角结构组成的平面或者立体结构。如下图中(a)是一个4-trusses,而(b)不是4-trusses;(b)是两个3-trusses。桁结构有很多力学性质,在网络社区发现等算法中k-trusses也经常被认为是一簇紧密相连的节点,可以聚为一类。下面我们就来介绍一下,通过hadoop框架来实现k-trusses结构检测的问题。
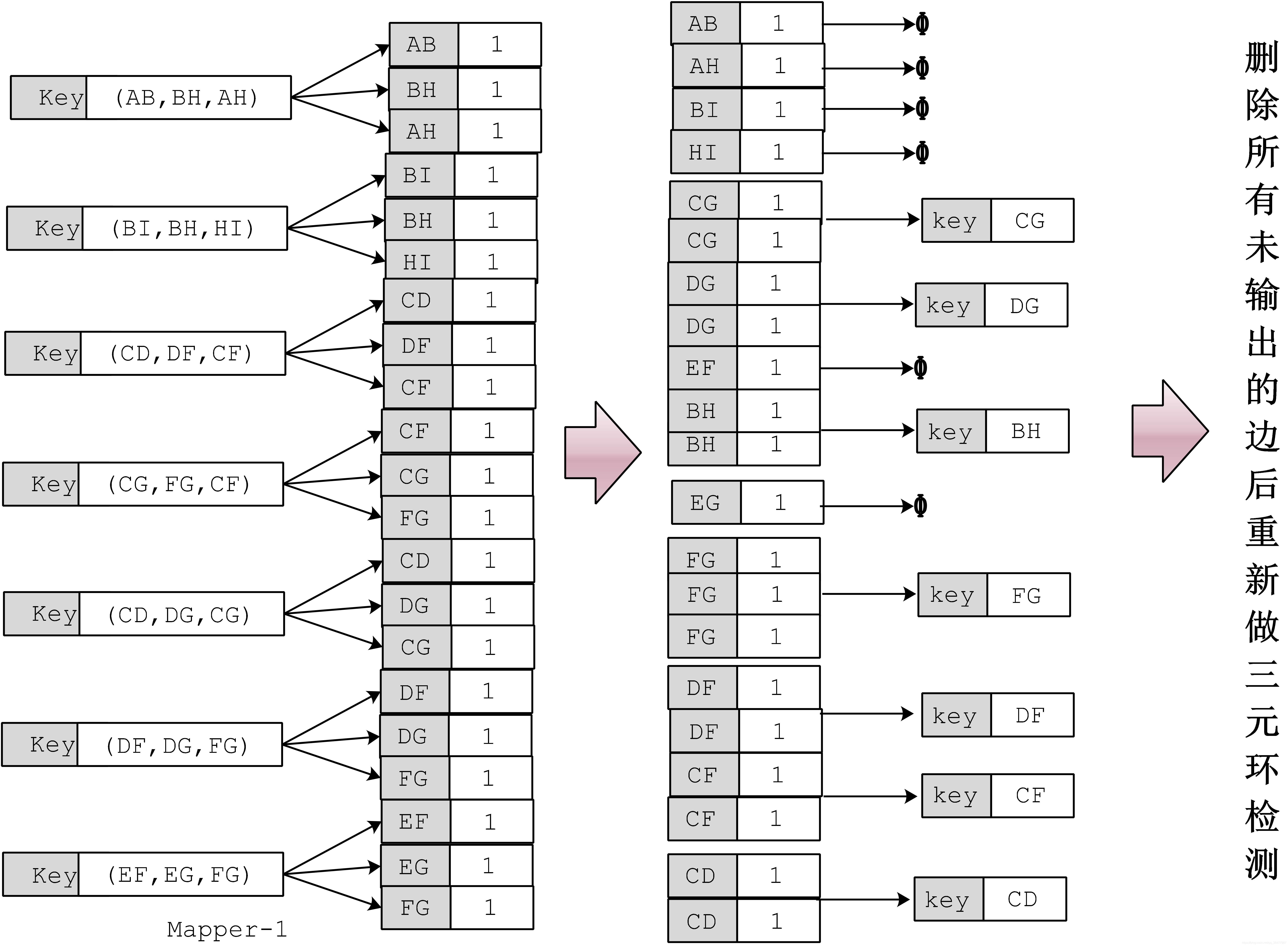
从上面定义可以发现其实寻找k-trusses问题可以转化为查找三元环问题。同时,由于k-trusses的边满足支撑条件(即k-trusses中的边至少属于k-2 triangles),可以考虑每次删除图中不满足支撑条件的边,检验剩下的图中边是否还满足支撑条件,不断迭代。如果将所有不满足支撑条件的边都去掉,图中剩余的component,就是k-trusses。具体算法如下:
- 计算边的度,检测出所有的三元环
- 输出三元环所有边,记录边所在三元环的个数;
- 保留满足支撑条件的边;
- 如果step 4 删除某些边,那么goto step1
- 剩下图中的components,每一个都是k-trusses
其中step 3,4 是一个MapReducer过程。
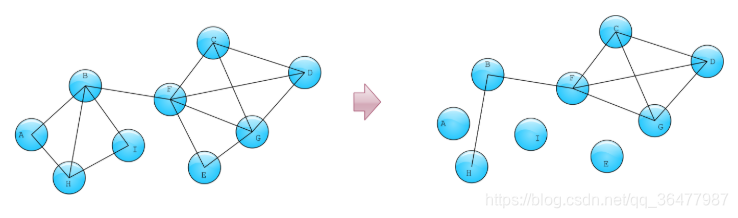
具体计算过程如下,假如初始图如下,我们要做4-trusses检测:
- 计算节点度,检测三元环;
- step 3, step 4 为一个MapReduce过程,演示示意图如下图6。

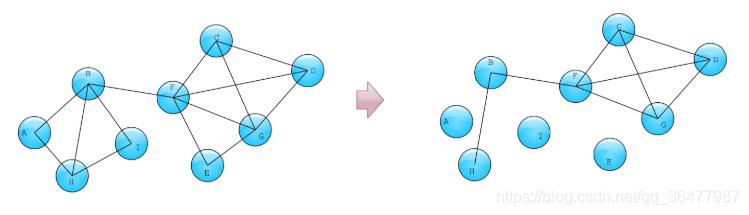
- Reducer过程中去掉了一些边,那么回到step1,重新对剩下的边做三元环检测,看剩下的边是否满足支撑条件。如下图所示,这时我们发现剩下的边组成如下的图,由此我们推理出trusses检测算法的主要流程,最后满足支撑条件的边都能构成4-trusses。
6. In a typical Map-Reduce graph algorithm, how many Map-Reduce phases are typically necessary before the graph can be traversed? Why?
- 计算边的度,检测出所有的三元环
- 输出三元环所有边,记录边所在三元环的个数;
- 保留满足支撑条件的边;
- 如果step 4 删除某些边,那么goto step1
- 剩下图中的components,每一个都是k-trusses
其中step 3,4 是一个MapReducer过程。
k-trusses 桁结构的定义是:a relaxation of a kmember clique and is a nontrivial, single-component maximal subgraph, such that every edge is contained in at least k -2 triangles in the subgraph. 具体理解,桁结构中是由三角结构组成的平面或者立体结构。如下图中(a)是一个4-trusses,而(b)不是4-trusses;(b)是两个3-trusses。桁结构有很多力学性质,在网络社区发现等算法中k-trusses也经常被认为是一簇紧密相连的节点,可以聚为一类。下面我们就来介绍一下,通过hadoop框架来实现k-trusses结构检测的问题。
具体计算过程如下,假如初始图如下,我们要做4-trusses检测: - 计算节点度,检测三元环;
- step 3, step 4 为一个MapReduce过程,演示示意图如下图6。
- Reducer过程中去掉了一些边,那么回到step1,重新对剩下的边做三元环检测,看剩下的边是否满足支撑条件。如下图所示,这时我们发现剩下的边组成如下的图,由此我们推理出trusses检测算法的主要流程,最后满足支撑条件的边都能构成4-trusses。
参考资料
1.https://blog.csdn.net/dannypolyu/article/details/38669401
2.https://studygolang.com/topics/4649?fr=sidebar
3.https://developer.ibm.com/messaging/2018/01/31/mq-performance-tests-docker/
4.https://docs.docker.com/storage/volumes/
5.https://github.com/docker-library/docs/tree/master/rabbitmq/














 76
76











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









