







百面机器学习笔记
1 特征工程
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
问题 为什么需要对数值类型的特征做归一化?
数据归一化并不是万能的。在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比(详见第3章第3节),而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。
问题 在对数据进行预处理时,应该怎样处理类别型特征?

问题 在图像分类任务中,训练数据不足会带来什么问题?如何缓解数据量不足带
来的问题?
当训练数据不足时,说明模型从原始数据中获取的信息比较少,这种情况下要想保证模型的效果,就需要更多先验信息。先验信息可以作用在模型上,例如让模型采用特定的内在结构、条件假设或添加其他一些约束条件;先验信息也可以直接施加在数据集上,即根据特定的先验假设去调整、变换或扩展训练数据,让其展现出更多的、更有用的信息,以利于后续模型的训练和学习。
具体到图像分类任务上,训练数据不足带来的问题主要表现在过拟合方面,即模型在训练样本上的效果可能不错,但在测试集上的泛化效果不佳。根据上述讨论,对应的处理方法大致也可以分两类:
- 基于模型的方法,主要是采用降低过拟合风险的措施,包括简化模型(如将非线性模型简化为线性模型)、添加约束项以缩小假设空间(如L1/L2正则项)、集成学习、Dropout超参数等;
- 基于数据的方法,主要通过数据扩充(Data Augmentation),即根据一些先验知
识,在保持特定信息的前提下,对原始数据进行适当变换以达到扩充数据集的效果。
具体到图像分类任务中,在保持图像类别不变的前提下,可以对训练集中的
每幅图像进行以下变换。


问题 在模型评估过程中,过拟合和欠拟合具体是指什么现象?
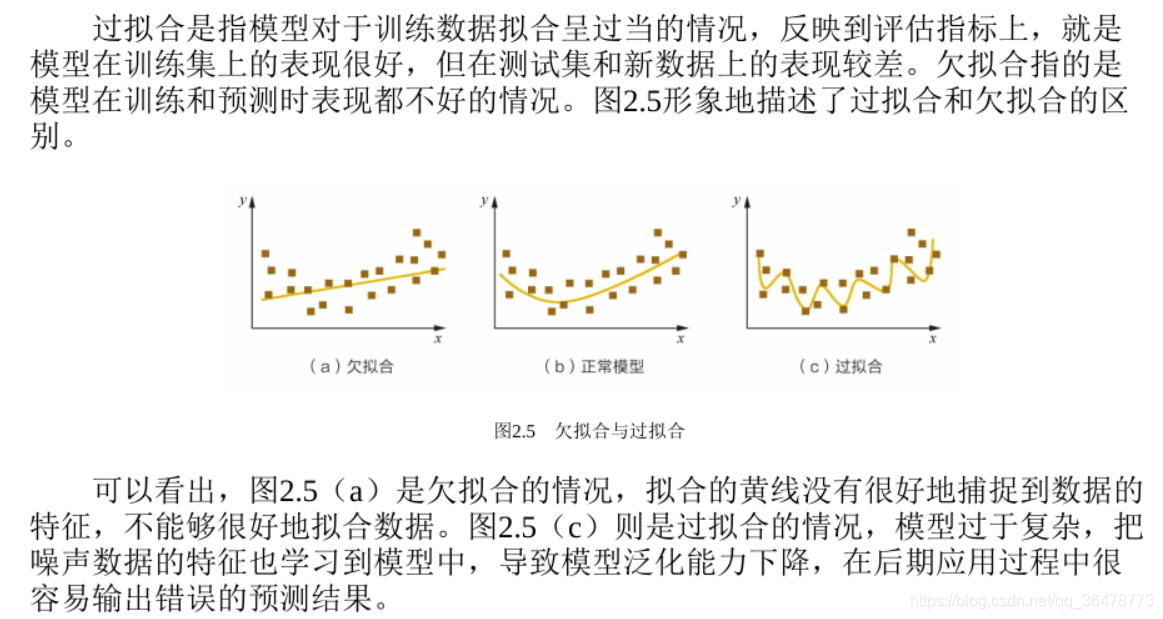
简而言之,过拟合即为模型不够复杂,欠拟合为模型太过于复杂。复杂是指x特征太少。


问题 logisitic回归相比于线性回归,有何异同?


决策树

聚类

算法流程:

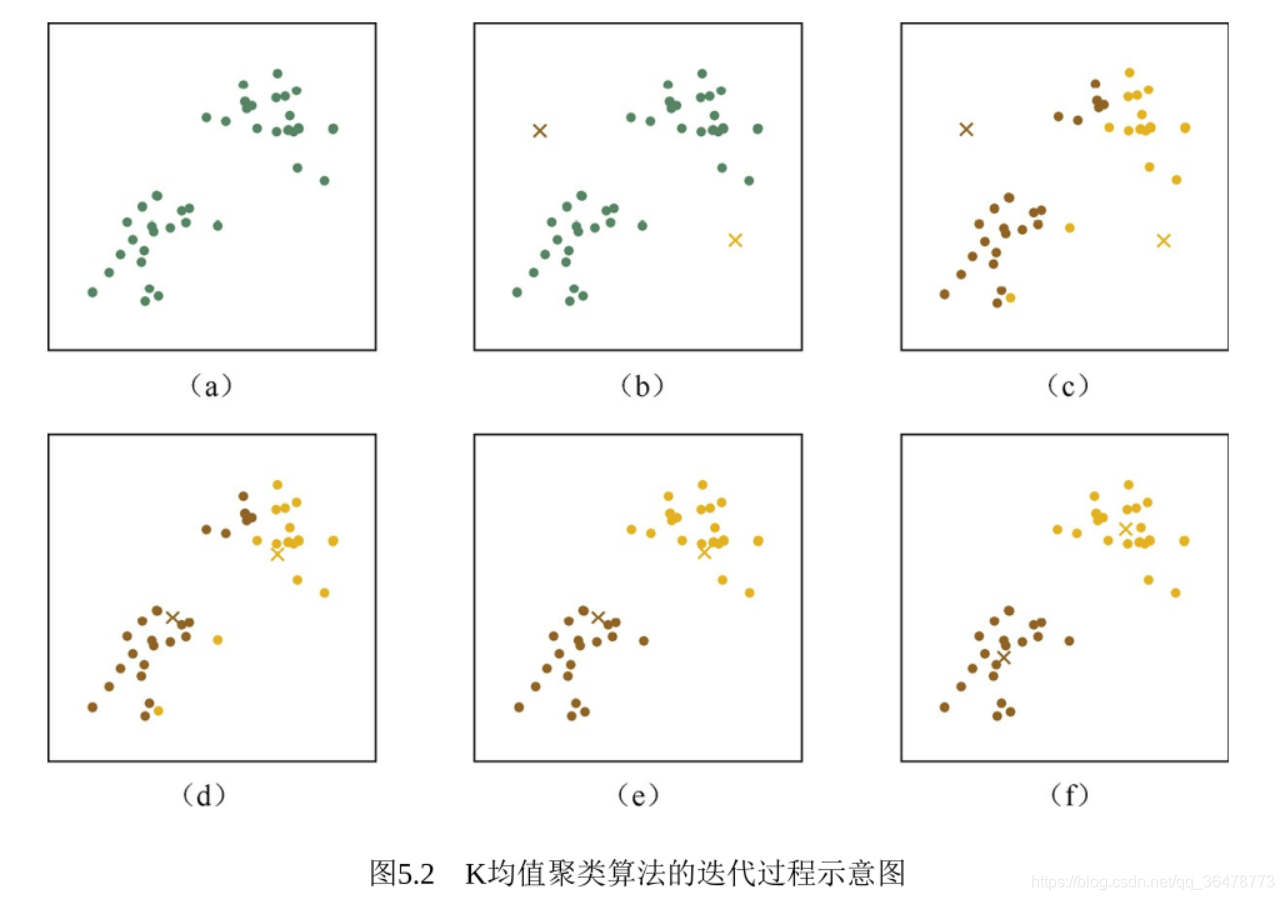
问题 K均值算法的优缺点是什么?如何对其进行调优?
K均值算法有一些缺点,例如受初值和离群点的影响每次的结果不稳定、结果通常不是全局最优而是局部最优解、无法很好地解决数据簇分布差别比较大的情况(比如一类是另一类样本数量的100倍)、不太适用于离散分类等。但是瑕不掩瑜,K均值聚类的优点也是很明显和突出的,主要体现在:对于大数据集,K均值聚类算法相对是可伸缩和高效的,它的计算复杂度是O(NKt)接近于线性,其中N是数据对象的数目,K是聚类的簇数,t是迭代的轮数。尽管算法经常以局部最优结
束,但一般情况下达到的局部最优已经可以满足聚类的需求。
调优的方法:


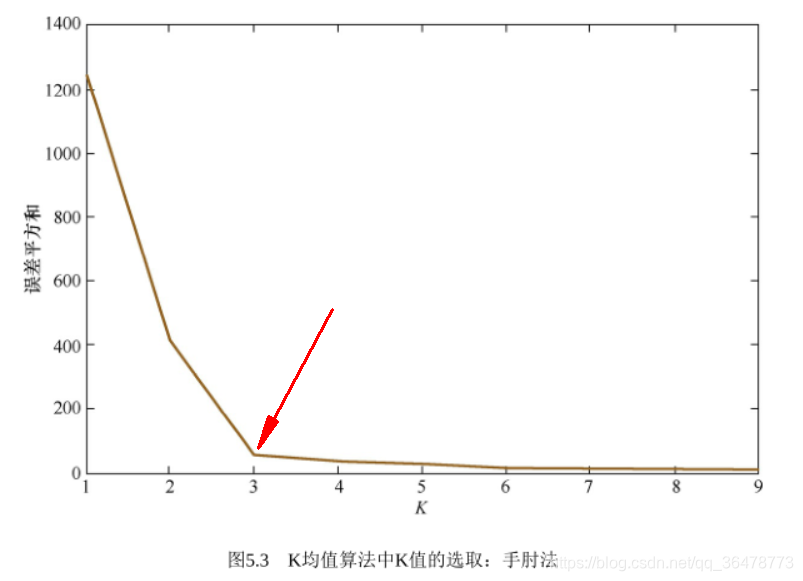
手肘法是一个经验方法,缺点就是不够自动化,因此研究员们又提出了一些
更先进的方法,其中包括比较有名的Gap Statistic方法 。
3. 采用核函数
采用核函数是另一种可以尝试的改进方向。传统的欧式距离度量方式,使得K均值算法本质上假设了各个数据簇的数据具有一样的先验概率,并呈现球形或者高维球形分布,这种分布在实际生活中并不常见。面对非凸的数据分布形状时,可能需要引入核函数来优化,这时算法又称为核K均值算法,是核聚类方法的一种 。核聚类方法的主要思想是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而在经典的聚类算法失效的情况下,通过引入核函数可以达到更为准确的聚类结果。
K均值算法的主要缺点如下。
(1)需要人工预先确定初始K值,且该值和真实的数据分布未必吻合。
(2)K均值只能收敛到局部最优,效果受到初始值很大。
(3)易受到噪点的影响。
问题 机器学习中的优化问题
首先,凸函数的定义:函数L()是凸函数当且仅当对定义域中的任意两点x,y和任意实数λ∈[0,1]总有 L(λx+(1-λ)*y) <= λL(x)+(1-λ)*L(y).
那么,无约束优化问题的优化方法有哪些?
梯度:表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
直接法和迭代法


迭代法:
- 一阶迭代法即梯度下降法
- 二阶迭代法即牛顿法

问题 当训练数据量特别大时,经典的梯度下降法存在什么问题,需要做如何改进?
- 经典的梯度算法使用所有训练数据的平均损失来近似目标函数,因此经典的梯度下降法在每次对模型参数进行更新时,需要遍历所有的训练数据;
- 随机梯度下降法(Stochastic Gradient Descent,SGD)用单个训练样本的损失来近似平均损失。
- 为了降低随机梯度的方差,从而使得迭代算法更加稳定,也为了充分利用高
度优化的矩阵运算操作,在实际应用中我们会同时处理若干训练数据,该方法被
称为小批量梯度下降法。


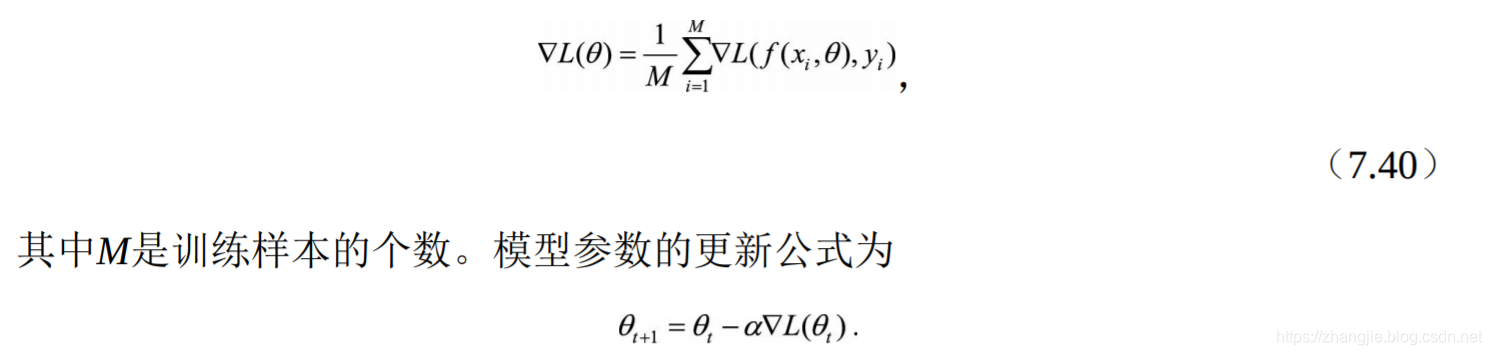
注意,随机梯度下降法则放弃了对梯度准确性的追求,每步仅仅随机采样一个(或少量)样本来估计当前梯度,计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。















 3940
3940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









