









本项目目的是交流与学习 请在24小时内删除!!!
1.1 requests 爬虫
第一件事应该是
明确需要爬取的数据的API接口
1.1.1 寻找API接口
首先你需要寻找的数据一定是JSON形式(JSON 类似字典 键值对一一对应,不约束结构)
一定在Fetch里面
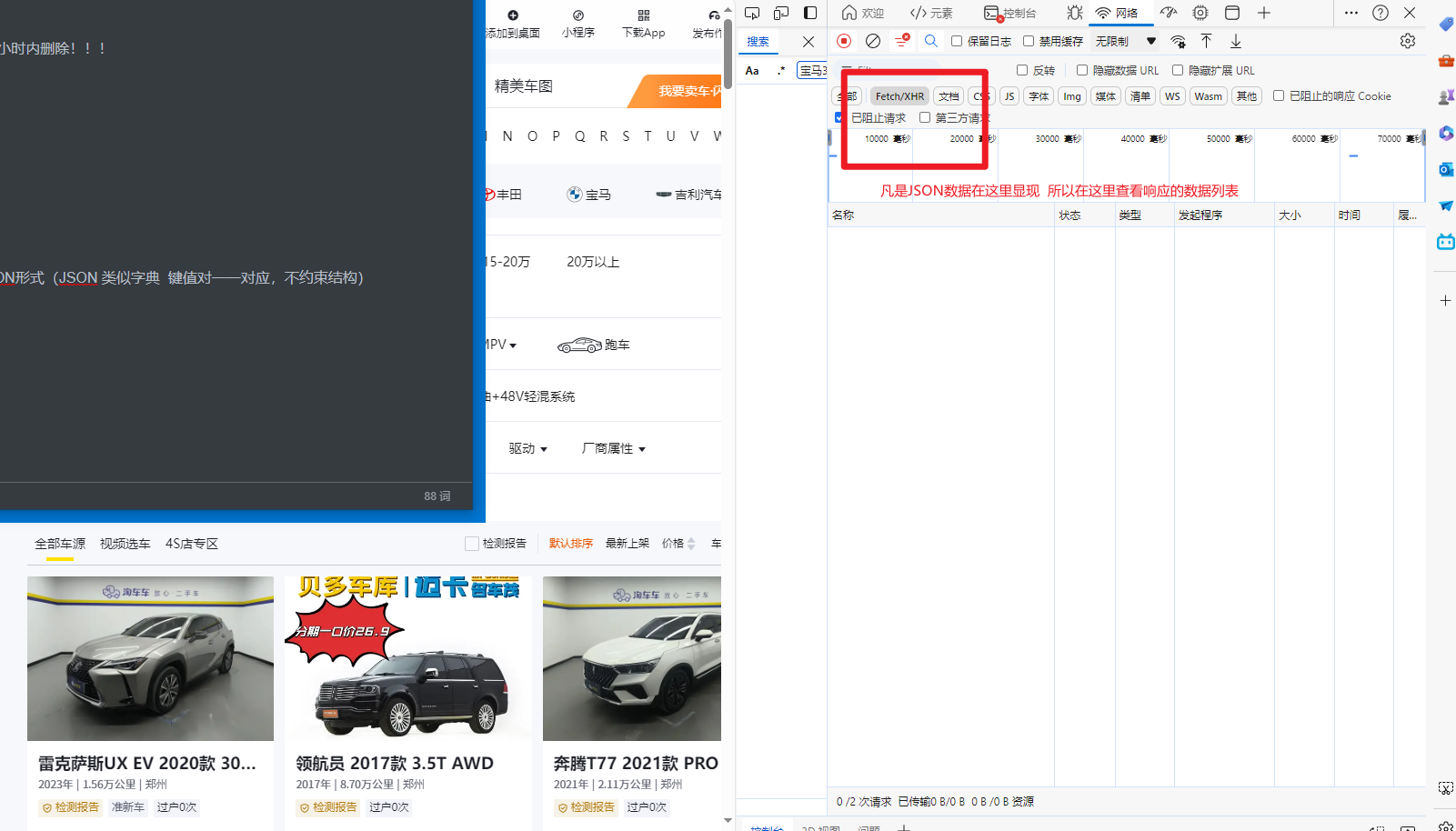
一般不通过直接刷新网页查看API接口,而是通过向下划/翻页只看在翻页时候发生的响应,更少的请求更少的扰乱项
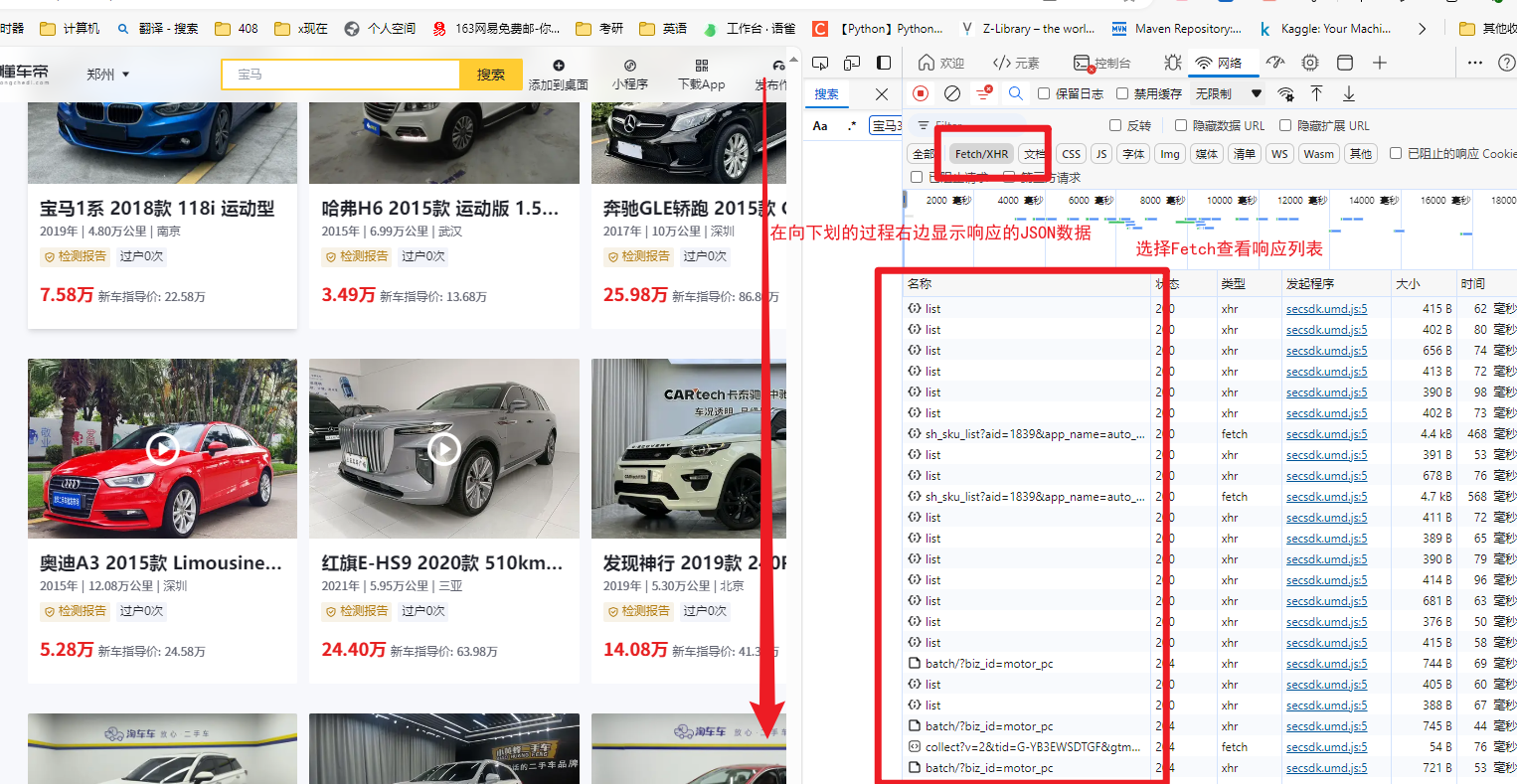
选择某个响应 查看其预览/响应
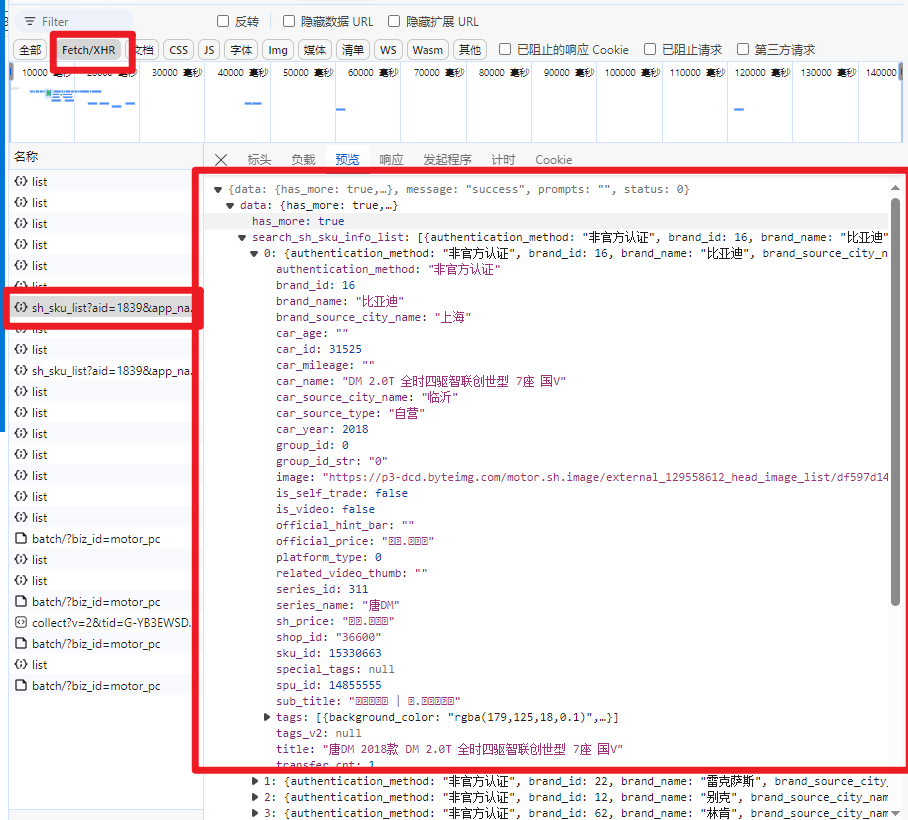
确定API接口:
https://www.dongchedi.com/motor/pc/sh/sh_sku_list?aid=1839&app_name=auto_web_pc
分析:
https://www.dongchedi.com/motor/pc/sh/sh_sku_list?aid=1839&app_name=auto_web_pc
POST方式 这个必须确实方式
表单Form数据携带:
cookie:
User-Agent:
这三个是常见的携带数据
这次只用表单数据
&sh_city_name=全国&page=2&limit=20
sh_city_name:全国 要求的范围
page:2 第几页
limit:20 一次获取数量
1.1.2使用requests库发起请求查看响应
url = 'https://www.dongchedi.com/motor/pc/sh/sh_sku_list?aid=1839&app_name=auto_web_pc'
#From 参数
for page in range(1,2):
data = { #键值对传入携带参数
'sh_city_name': '全国',
'page': page,
'limit': '20'
}
#发起请求
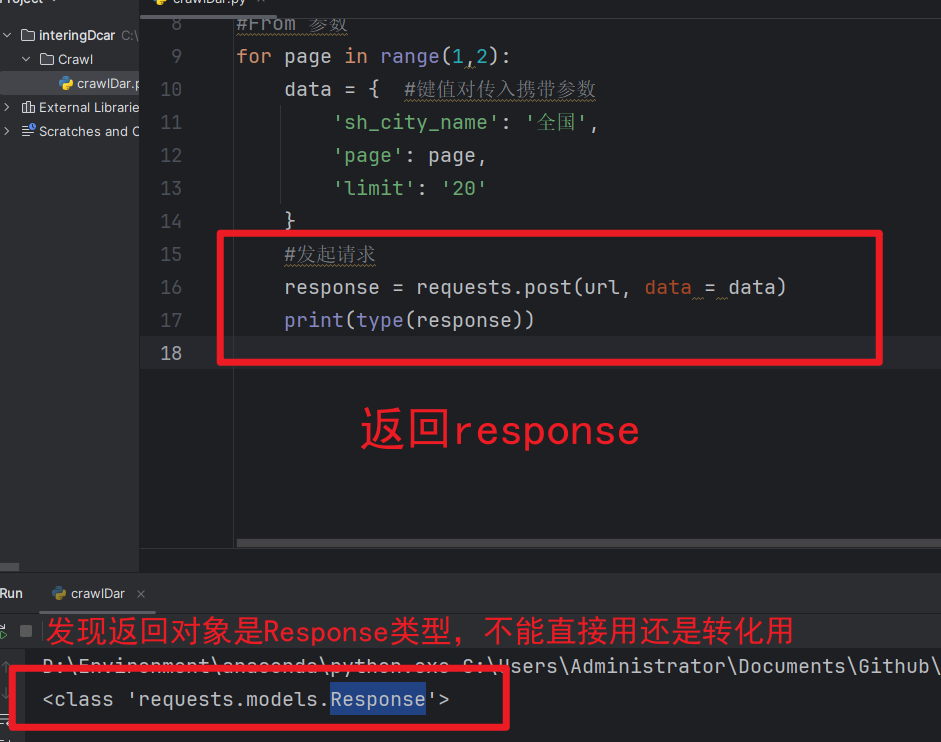
response = requests.post(url, data = data)
print(type(response))
1.1.3分析response
转化为JSON数据 进行键值对访问
#使用JSON 可以通过键值对访问
responseList = response.json()
1.1.4 真正取出数据
使用键值对取数据 不过需要对JSON进行分析
先明白response是什么
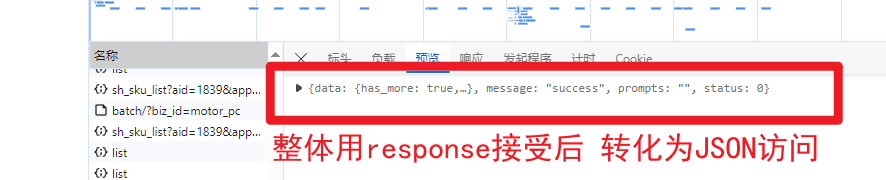
所以 response是 整个大括号
{
data:{
}
}
遵循两个要求
- 大括号{}就是里面含有很多键值对通过[‘data’] 键值访问某一个数据
- 中括号[]就是列表 只能通过[0] [1] 这种访问 一般在Python在使用for item in data 进行访问
把我键值对和列表两种形式对应方法进行访问 余下的就是要一级一级看
目的取出每一辆汽车的信息 已经确定在里面 一级一级访问查看
- reponse内部:
repsonse是:

后面是键值对那么[‘data’]进行访问
response['data']

这是response内部一个个键值对
- response[‘data’]内部
首先 看到是大括号 那么自然能想到里面什么情况
键值对 对应内部数据为

response['data']['search_sh_sku_info_list']
-
response['data']['search_sh_sku_info_list']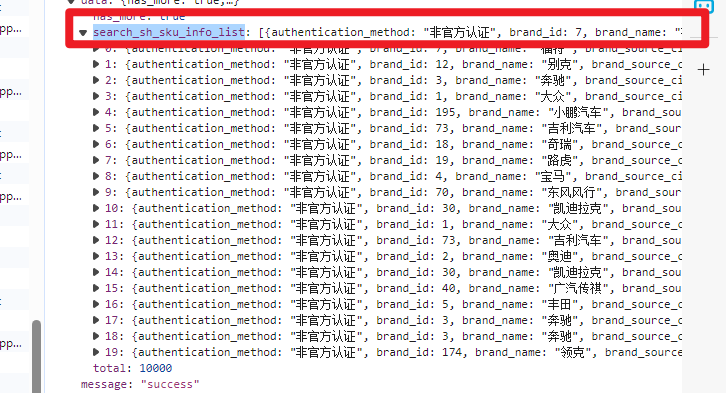
后面是中括号 那么列表
访问item访问
for item in responseList['data']['search_sh_sku_info_list']:
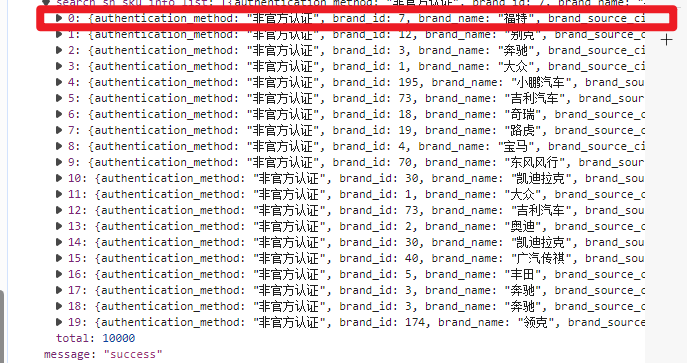
item后面依旧是大括号那么键值对
一直访问到自己需要的
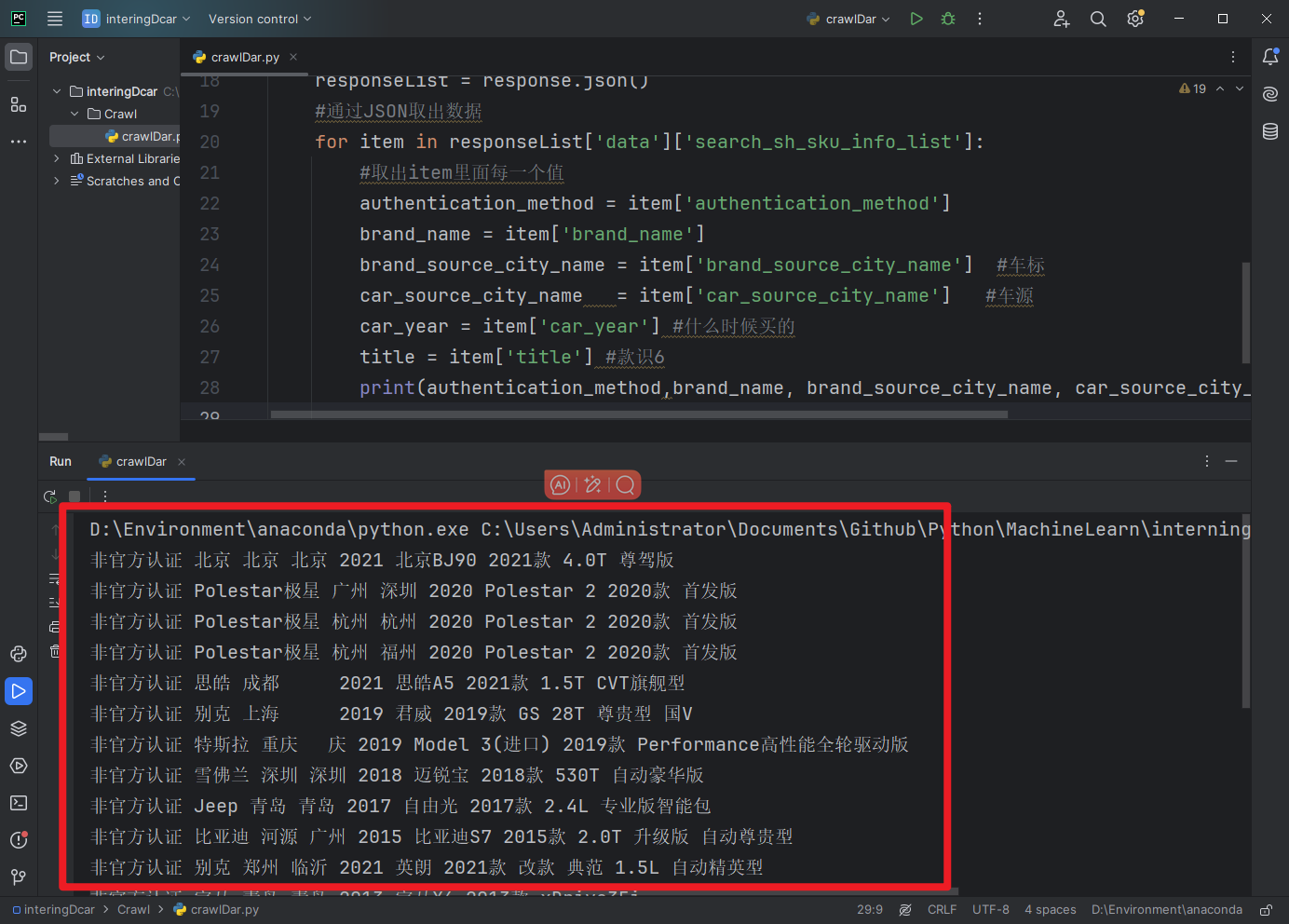
#通过JSON取出数据
for item in responseList['data']['search_sh_sku_info_list']:
#取出item里面每一个值
authentication_method = item['authentication_method']
brand_name = item['brand_name']
brand_source_city_name = item['brand_source_city_name'] #车标
car_source_city_name = item['car_source_city_name'] #车源
car_year = item['car_year'] #什么时候买的
title = item['title'] #款识6
print(authentication_method,brand_name,)
爬取完毕
1.2 数据持久化 放入CSV/Mysql中
1.2.1 CSV保存到本地
1.2.1.1 open函数
首先了解open函数
Pyhton打开一个文件,如果文件不存在,自动创建一个文件(就算这个文件为空)
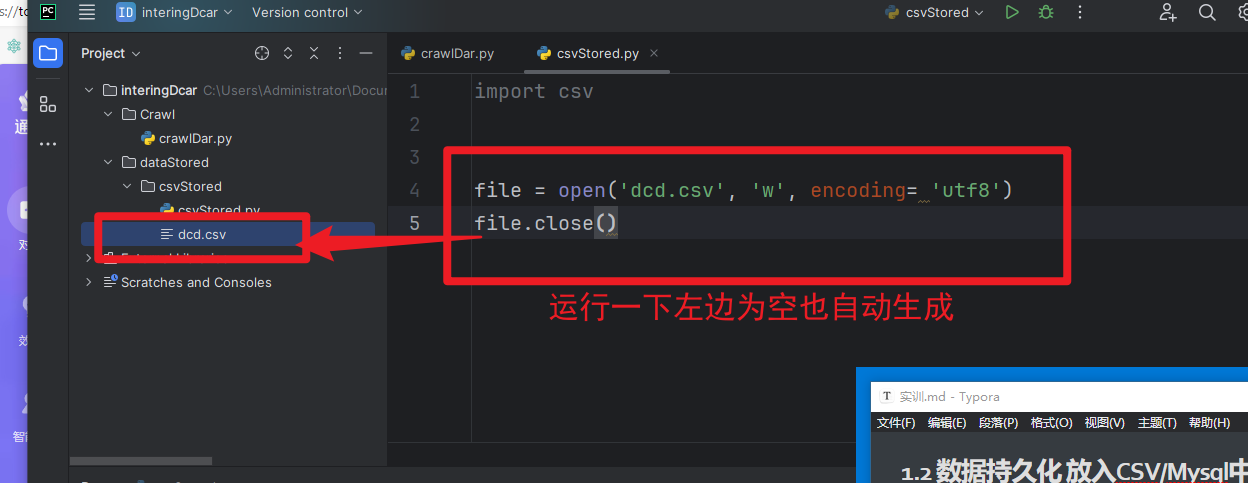
file = open('dcd.csv', 'a', encoding= 'utf8')
('adress','way', 'encoding 编码格式')
1.1.2.2 持久化CSV
创建CSVStored类:
- 大逻辑
构造函数设置属性 self.xxxx 声明一些等下需要用到变量
设置路径,设置 表头 属性
打开文件 - Csv 创建文件对象
Csv修改file(打开的文件对象),表头
写入header 表头中 确定属性后
函数2 使用初始化的self.csvWriter 实现写入行 字典数据
self.csvWriter .writeRowdic)
函数3 关闭对象自己的文件链接
self.flie.close()
import csv
import random
#参数
#1.保存路径
#2.表头值
class CsvDataStore:
#构造函数 创建类的时候传入保存地址、表头
#创建csv文件 设置csv文件表头csvWriter = csv.Dicheader(path, fieldnames = fieldnames) 通过Dicwriter
#写入表头中 csvWriter.writerHeader() #writerRow写入行
#细节:
# 1.构造函数只用于初始化 不实现具体的函数(推荐)(因为会多次调用1) 如这次的Csv传入路径和表头 确定属性后 在writeRow函数中实现写入行
#2.在构造函数中新声明的变量用self.xxx声明,之后调用就通过self.xxxx调用即可
def __init__(self, path, fieldnames):
self.file = open(path, 'a', encoding='utf8', newline='')
self.writerCsv = csv.DictWriter(self.file, fieldnames=fieldnames)
# 写入文件中
self.writerCsv.writeheader()
#插入数据
def writeRow(self, dic):
# 创建文件
if dic:
# Csv不真正操作数据 而是设置数据信息 修改列信息 这种对文件属性的操作而不内容
# 而Csv中DictWriter才可以对内部数据写入等等
# 操作文件 字典列信息
# 插入数据时 按照字典键值对类型写入行
#在 Windows 系统中,默认的换行符是'\r\n',而 CSV 格式通常只需要'\n'作为行分隔符。通过指定newline='',csv.DictWriter会按照 CSV 的规范进行换行处理,而不会引入额外的空行。
self.writerCsv.writerow(dic)
else:
print("dic provided")
def close(self):
self.file.close()
1.2.2.3 码点解析
def change(word):
string = ''
# 构建映射规则
word_data = {58344: '候', 58345: 'p', 58346: '应', 58347: '7', 58348: '外', 58349: '学', 58350: '在', 58352: 'x',
58353: '着', 58354: '原', 58355: 'b', 58356: '几', 58357: '相', 58358: 'y', 58359: '处', 58361: '进',
58362: '下', 58363: '长', 58364: '手', 58365: 'w', 58366: '花', 58367: '后', 58368: 'l', 58369: '发',
58370: '写', 58371: '别', 58372: '期', 58373: '声', 58374: '还', 58375: '友', 58376: 'g', 58377: '些',
58378: '万', 58379: 'v', 58380: '已', 58381: '路', 58382: '等', 58383: '爱', 58384: '每', 58385: '5',
58386: '有', 58387: '结', 58388: '回', 58389: '音', 58390: '像', 58391: '斯', 58392: '比', 58393: '士',
58394: '现', 58395: '其', 58396: '难', 58397: '4', 58398: '过', 58399: '物', 58400: '儿', 58401: '名',
58402: '打', 58403: '都', 58404: '为', 58405: '出', 58406: 's', 58407: '我', 58408: 'Z', 58410: '认',
58411: '道', 58412: '便', 58413: '报', 58415: 'h', 58416: '种', 58417: '海', 58418: '将', 58419: '点',
58420: '月', 58421: '员', 58422: '由', 58423: '失', 58424: '同', 58425: '0', 58426: 't', 58427: '问',
58428: '两', 58429: 'Y', 58430: 'b', 58431: '但', 58432: '多', 58433: '然', 58434: '工', 58435: '家',
58436: '才', 58437: '的', 58438: '车', 58439: '轻', 58440: '关', 58441: '看', 58442: '棱', 58443: '夫',
58444: '之', 58445: '和', 58446: '真', 58447: '气', 58448: 'm', 58449: '却', 58450: '法', 58451: '又',
58452: 'j', 58453: '世', 58454: '主', 58455: '己', 58456: '用', 58457: '眼', 58458: 'k', 58459: 's',
58460: '笑', 58461: '9', 58462: '格', 58463: '上', 58464: 'c', 58465: '死', 58466: '平', 58467: '2',
58468: '四', 58469: '不', 58470: '记', 58471: '者', 58472: '对', 58473: '他', 58474: '机', 58475: '能',
58476: '被', 58477: '许', 58478: '国', 58479: '经', 58480: '从', 58481: '门', 58482: 'L', 58483: 'q',
58484: '那', 58485: '命', 58486: '西', 58488: '往', 58489: '常', 58490: '电', 58491: '接', 58492: '神',
58493: '望', 58494: '通', 58495: '边', 58496: '金', 58497: '男', 58498: 'v', 58499: '全', 58500: '受',
58501: '去', 58502: '拉', 58503: '生', 58504: '部', 58505: '走', 58506: '作', 58507: '何', 58508: '明',
58509: '乐', 58510: '成', 58511: '大', 58512: '地', 58514: '公', 58515: '十', 58516: '这', 58517: '或',
58518: '子', 58519: '先', 58520: '她', 58521: '只', 58522: '孩', 58523: '师', 58524: '所', 58525: '3',
58527: '东', 58528: '了', 58529: '意', 58530: '老', 58531: 'P', 58532: 'z', 58534: 'h', 58535: 'i',
58536: '里', 58537: 'd', 58538: '无', 58539: 'j', 58540: '满', 58542: '变', 58543: '得', 58544: '力',
58545: '安', 58546: '高', 58547: '光', 58548: 'q', 58549: '此', 58550: '知', 58551: '自', 58552: '向',
58553: '呢', 58554: '动', 58555: '数', 58556: '什', 58557: '目', 58558: '想', 58559: '到', 58560: '妈',
58561: '军', 58562: '再', 58563: '马', 58564: 'o', 58565: '听', 58566: '使', 58567: '吃', 58568: '尔',
58569: '立', 58570: 'g', 58571: '因', 58572: 'n', 58573: '本', 58574: 'K', 58575: '快', 58576: '做',
58577: '信', 58578: '天', 58579: 'm', 58580: '至', 58581: 'n', 58582: '间', 58583: '更', 58584: '白',
58585: '次', 58586: '条', 58587: '小', 58588: '水', 58589: '表', 58590: '远', 58591: '而', 58592: '告',
58593: '象', 58594: '加', 58595: '8', 58596: '民', 58597: '直', 58598: '住', 58599: '理', 58600: '色',
58601: '让', 58602: 'a', 58603: '当', 58604: '太', 58605: '德', 58606: '战', 58607: 'u', 58608: '好',
58609: '文', 58610: '么', 58611: '行', 58612: '母', 58613: '见', 58614: '时', 58615: 'F', 58616: 'e',
58617: 'a', 58618: '日', 58619: '给', 58620: '头', 58621: '于', 58622: 'r', 58623: '利', 58624: '说',
58625: '带', 58627: '克', 58628: '教', 58629: 'o', 58630: '就', 58631: '是', 58632: '最', 58633: '重',
58634: '实', 58635: '要', 58636: '事', 58637: '总', 58638: '没', 58639: '任', 58640: '面', 58641: '话',
58642: '书', 58643: '正', 58644: '口', 58645: '英', 58646: '亲', 58647: 'u', 58648: '度', 58649: '体',
58650: '活', 58651: '少', 58653: '感', 58654: '前', 58655: '可', 58656: '中', 58657: '分', 58658: '山',
58659: '你', 58660: '性', 58661: '年', 58662: '情', 58663: '放', 58664: '样', 58665: '叫', 58666: '起',
58667: 'c', 58668: '新', 58669: '把', 58670: '开', 58671: '方', 58672: '女', 58673: '个', 58674: '与',
58675: '身', 58676: '6', 58677: '入', 58678: 'w', 58679: '第', 58680: '父', 58681: '来', 58682: '界',
58683: 'd', 58684: '张', 58685: '会', 58686: '美', 58687: '人', 58688: 'R', 58689: '很', 58690: '风',
58691: 'x', 58693: '内', 58694: '觉', 58695: 'f', 58696: '定', 58697: '果', 58698: '也', 58699: '特',
58700: '1', 58701: '岁', 58702: '位', 58703: '字', 58704: '场', 58705: 'e', 58706: '它', 58707: '们',
58708: '心', 58709: '代', 58710: '解', 58711: '以', 58712: '如', 58713: '并', 58714: 't', 58715: 'l'}
# for循环遍历
for i in word:
try: # 如果存在字体加密
# ord(i) 获取码点 -> 根据键值对取值
new_word = word_data[ord(i)]
except: # 没有加密正常返回
new_word = i
string += new_word
#返回解析数据
return string
‘解’, 58711: ‘以’, 58712: ‘如’, 58713: ‘并’, 58714: ‘t’, 58715: ‘l’}
# for循环遍历
for i in word:
try: # 如果存在字体加密
# ord(i) 获取码点 -> 根据键值对取值
new_word = word_data[ord(i)]
except: # 没有加密正常返回
new_word = i
string += new_word
#返回解析数据
return string















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









