







 本文深入解析正则表达式的概念、语法与应用场景,涵盖特殊字符、限定符、元字符等核心元素,以及如何在Java中运用正则表达式进行字符串匹配、分割与替换,提供丰富的实例帮助理解。
本文深入解析正则表达式的概念、语法与应用场景,涵盖特殊字符、限定符、元字符等核心元素,以及如何在Java中运用正则表达式进行字符串匹配、分割与替换,提供丰富的实例帮助理解。
正则表达式
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
例如:
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。
runoob,可以匹配 runob、runoob、runoooooob 等, 号代表字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
正则表达式可以用来干什么?
我们在程序,经常会碰到需要判断字符串是否符合我们要求的需求,这时候,使用正则表达式是可以很好满足我们的开发
如:
判断字符串是否是有效的电话号码?
判断字符串是否是有效的身份证号码?
判断字符串是否是有效的电子邮件地址?
正则表达式入门
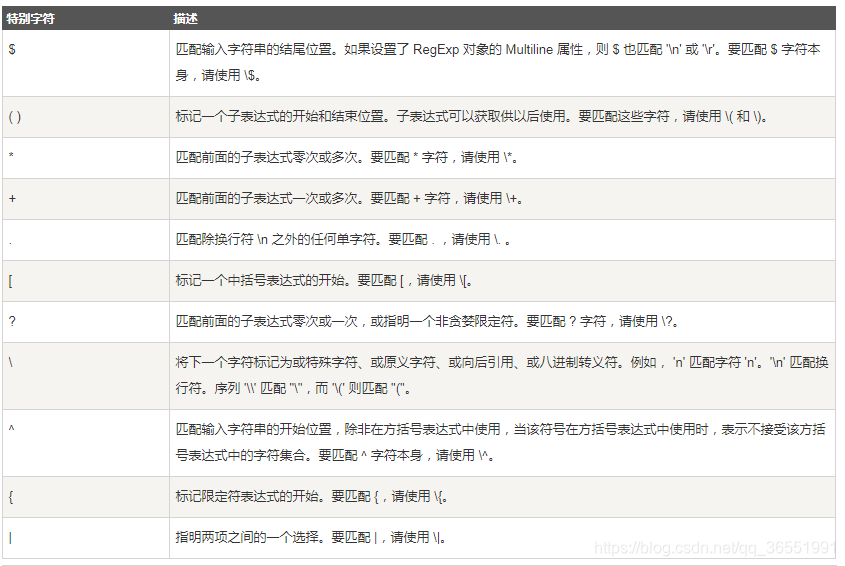
特殊字符
所谓特殊字符,就是一些有特殊含义的字符。比如上面例子的?和*。我们如果是想匹配这些特殊字符,是需要进行转义的,即在其前加一个 \
例如:我想匹配一个字符串是不是为”**”,我们的正则表达式应该为”**”
以下为正则表达式中的特殊字符
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
正则表达式的限定符有:

注:* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从"贪婪"表达式转换为"非贪婪"表达式或者最小匹配。
元字符
下面介绍一下正则表达式的元字符
^:表示字符串的开始位置
$:表示字符串的结束位置
\:转义符,在字符串中表达特殊字符需要进行转义
*:匹配前面的子表达式零次或多次
+:匹配前面的子表达式一次或多次
?:匹配前面的子表达式零次或一次
{n}:n 是一个非负整数,表示需要匹配两次,例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。
{n,m}:m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。
?:当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。
x|y:匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。
[xyz]:字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。
[^xyz]:负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。
[a-z]:字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。
[a-z]:负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。
\b:匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。
\B:匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。
\d:匹配一个数字字符。等价于 [0-9]。
\D:匹配一个非数字字符。等价于 [^0-9]。
\f:匹配一个换页符。等价于 \x0c 和 \cL。
\n:匹配一个换行符。等价于 \x0a 和 \cJ。
\r:匹配一个回车符。等价于 \x0d 和 \cM。
\s:匹配任何空白字符,包括空格、制表符、换页符等等。
\S:匹配任何非空白字符。
\w:匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。
\W:匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。
正则表达式从左到右进行计算,并遵循优先级顺序。我们只需要记得,正则表达式最高优先级为转义符(\),然后就是括号(圆括号和方括号),其他一些限定符都是同级(比括号低一级),最低是或运算符(|)。
在Java中如何判断字符串是否匹配给定的正则表达式
Java matches() 方法:matches() 方法用于检测字符串是否匹配给定的正则表达式。匹配得话返回true
使用
1、直接使用字符串调用
//rex为正则表达式
String rex = "a?c";
"axxc".matches(rex);
2、使用Pattern调用,第一个参数为正则表达式,第二个参数为需要检验的字符串
Pattern.matches("a?c", "axc")
一些常见的正则表达式匹配规则
精准匹配
精准匹配:即一些固定的数值或者字符,比如“abc”就只能匹配”abc”,”123”只能匹配”123”
不过精准匹配我们一般用的比较少,我们一般用的都是那种模糊匹配,即不指定固定值的表达式
模糊匹配
用.可以匹配任意字符
例:我们可以用a.c,来表示abc,aac等,只要ac之间有一个字符,我们都可以使用.来匹配,.匹配一个字符且仅限一个字符。。如果ac之间有多个字符,那么我们在.后面加一个+的限定符,表示可以有多个字符,"a.+c"可以匹配abc,aaacc等
匹配数字
我们可以用\d匹配任意数字,\d仅限单个数字字符。例12\d,可以匹配123,128等。
如果我们想匹配指定个数的数字就可以使用{}了
例:\d{3},表示3个数字
注意:在java的正则表达式中,\d才表示\d
例:
String rex = "\\d{3}";
System.out.println("123".matches(rex));
如果我们想匹配匹配n~m个字符,那么就可以使用{n,m},n为最少匹配的个数,m为最多匹配的个数
例:\d{3,5},可以匹配3到5个数字,多于5个或者少于3个都会不成立
不确定个数的匹配都是使用*,+,?
* 任意个数字符,0个或n个
+ 至少1个字符,1个或n个
? 0个或1个字符,最多只能匹配一个字符
范围匹配
如果我们只想匹配某个范围内的字符,可以使用[]加-表示一个范围。[]表示一组匹配字符,如[123],那么就可以匹配1、2、3中的任一个,而-表示连字符,可以方便我们表示如[123],我们可以表示成[1-3]
例:只匹配1,2,3,那么我们就可以使用以下这个正则表达式
[1-3] //匹配1,2,3
[b-d]//匹配b到d的字符,即b,c,d
注:正则表达式区分大小写,[A-Z]为匹配所有大写字母,[a-z]为匹配所有的小写字母
开头匹配和结尾匹配
^表示开头字符匹配,如果我们需要指定字符串只能是2开头,那么我们可以使用以下这个正则表达式
^2.* //匹配以2开头,后面可以接任意个字符
^不仅可以表示开头字符,当在一组方括号里使用 ^ 时,它表示"非"或"排除"的意思
^[^0-9].*//表示一个不能以数字开头的字符串
$表示结尾的字符,如.*2$,可以匹配12,2,342,但不能匹配23等不以2结尾的字符串。
或匹配
正则表达式的或匹配,使用|。如a|b,那么字符a或者b都可以匹配
例
如果我们想要匹配字符串say morning、say night,那么我们可以把公共部分提取出来,然后将不同部分用或匹配。使用()可以表达一个字表达式
正则 表达式如下:
say \\s(morning|night)
如果我们想匹配Morning和morning,可以参考下面的表达式
say\s((m|M)orning|(n|N)ight)
非贪婪匹配
假如,我们想获取到一个字符串中末尾a的个数
例:
xaa:结尾2个a
kisasda:结尾一个a
我们可能会写出(.)(a)的正则表达式
我们测试一下
Pattern pattern1 = Pattern.compile("(.*)(a*)");
Matcher matcher1 = pattern1.matcher("asda");
if (matcher1.matches()) {
System.out.println("group1=" + matcher1.group(1));
System.out.println("group2=" + matcher1.group(2));
}
输出
group1=asda
group2=
我们从输出可以看出,字符串都被第一个表达式所匹配了。这是因为正则表达式默认都是贪婪匹配的,它总是尽可能多地向后匹配。这时候我们就需要将第一个表达式变成非贪婪匹配,也很简单,只需要在第一个表达式后面加上一个?即可。改成(.?)(a)
Pattern pattern1 = Pattern.compile("(.*?)(a*)");
Matcher matcher1 = pattern1.matcher("asda");
if (matcher1.matches()) {
System.out.println("group1=" + matcher1.group(1));
System.out.println("group2=" + matcher1.group(2));
}
输出:
group1=asd
group2=a
符合我们的要求了
?=,?:,?!
?=:正向肯定预查,相当于我们就规定字符串需要包含该符合?=中的字符,例:“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。
?!:正向否定预查(negative assert),在不匹配?!表达式的字符串开始处匹配查找字符串,例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。
?::匹配一个表达式,需要字符串中需要含有该表达式,才符合匹配。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式
注意:还有?<=和?<!,表示反向的断言,即与?=和?!方法相反,需要在前面,例:"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",不能匹配"Windows2000"的Windows
在java中如何得到我们匹配的字符串呢?
我们可以用Pattern对象匹配,匹配后获得一个Matcher对象,如果匹配成功,就可以直接从Matcher.group(index)返回子串
例:
//构造一个正则表达式的Pattern对象
Pattern pattern = Pattern.compile("(\\d{3})\\-(\\d{3})");
//matcher为创建匹配器,它将根据此模式匹配给定的输入。
Matcher matcher = pattern.matcher("010-123");
//matches方法可以得到匹配结果,匹配成功为true,不成功为false
if (matcher.matches()) {
String group = matcher.group(1);
String group1 = matcher.group(2);
System.out.println(group);
System.out.println(group1);
}
输出
010
123
分割字符串
其实,如果我们知道一个字符串的分隔符是什么,那么我们直接使用spit方法更好。spit让我们传入一个分割符,然后就会对调用方法的字符串进行分割,返回一个String类型的数组。如果字符串中没有该分隔符,那就会返回原本的字符串。当然,spit方法还可以传入其他的正则表达式,很好用的一个方法
String str="010-123";
String[] split = str.split("-");
for (String s : split) {
System.out.println(s);
}
输出
010
123
替换字符串
使用正则表达式替换字符串可以直接调用String.replaceAll(),它的第一个参数是正则表达式,第二个参数是待替换的字符串。
例:我们将一个字符串中的空格去掉,可以使用以下方法
String test="a b c";
String s1 = test.replaceAll(" ", "");
System.out.println(s1);
输出:
abc
常用的正则表达式
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.\d)(?=.[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.\d)(?=.[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
正数、负数、和小数:^(-|+)?\d+(.\d+)?$
由数字、26个英文字母或者下划线组成的字符串:^\w+$
汉字:^[\u4e00-\u9fa5]{0,}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
Email地址:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+.?

















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









