







 本文介绍了数字语音识别的基本步骤,重点讨论了隐马尔可夫模型在语音识别中的应用,包括前向后向算法和维特比算法。通过对模型的训练和解码过程的阐述,揭示了如何利用这些算法优化语音识别的性能。
本文介绍了数字语音识别的基本步骤,重点讨论了隐马尔可夫模型在语音识别中的应用,包括前向后向算法和维特比算法。通过对模型的训练和解码过程的阐述,揭示了如何利用这些算法优化语音识别的性能。
文章目录
数字语音识别的基本步骤
数字语音识别的基本模型如下图所示。首先对语音进行处理之后,使用声学模型进行解码,之后将音节与词表进行匹配得到词序列,最后再使用语言模型得到语句。
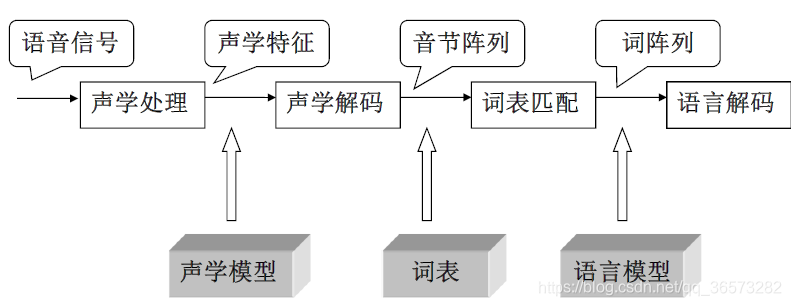
在中间的过程中,通过解码后的音学信号序列得到词语序列。常规的方法是使用贝叶斯来计算词语的概率值。
假设 X X X是声学信号序列, W W W是词语序列,那么贝叶斯公式为 P Λ ( W ∣ X ) = P λ X ( X ∣ W ) P λ W ( W ) P ( X ) P_{\Lambda}(W|X)=P_{\lambda X}(X|W)\frac{P_{\lambda W}(W)}{P(X)} PΛ(W∣X)=PλX(X∣W)P(X)PλW(W)。在训练的过程中是要最大化 m a x Λ P Λ ( W ∣ X ) max_{\Lambda}P_{\Lambda}(W|X) maxΛPΛ(W∣X),在语音解码得到词语序列的时候则是最大化 m a x W P Λ ( W ∣ X ) max_{W}P_{\Lambda}(W|X) maxWPΛ(W∣X)。
语音识别模型
语音识别常用的模型包括动态时间规整(Dyanmic Time Warping)、矢量量化(Vector Quantization)、隐马尔可夫模型(Hidden Markov Models)。
隐马尔可夫模型
高斯混合密度分布刻画了语音状态(例如音素)以及语音状态之间的时序变迁的统计规律。基本的过程包含三步。
- 评估:给定观测向量Y和模型,利用前向后向算法计算得分;
- 匹配:给定观测向量Y,用Viterbi算法确定一个优化的状态序列;
- 训练:用Baum-Welch算法(类似于EM)重新估计参数,使得得分最大。
已知一个有限的离散状态序列 S = { q 1 , q 2 , … , q N − 1 , q N } S=\{q_1,q_2,\dots,q_{N-1},q_N\} S={ q1,q2,…,qN−1,qN},从时间 t t t到时间 t + 1 t+1 t+1,保持当前状态或迁移到另一个状态。从时刻 t t t状态为 q i q_i qi迁移到时刻 t + 1 t+1 t+1状态为 q j q_j qj,概率为 a i j = P ( q t + 1 = j ∣ q t = i ) , 1 ≤ i , j ≤ N a_{ij}=P(q_{t+1}=j|q_t=i),1\leq i,j\leq N aij=P(qt+1=j∣qt=i),1≤i,j≤N。这样就可以得到状态之间的迁移概率矩阵。
A = [ a 11 a 12 … a 1 N a 21 a 22 … a 2 N … … … … a N 1 a N 2 … a N N ] A=\left[\begin{matrix} a_{11} & a_{12} & \dots & a_{1N}\\ a_{21} & a_{22} & \dots & a_{2N}\\ \dots & \dots & \dots & \dots\\ a_{N1} & a_{N2} & \dots & a_{NN} \end{matrix}\right] A=⎣⎢⎢⎡a11a21…aN1a12a22…aN2…………
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4411
4411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









