







本文记录使用Python处理大量excel数据,避免手动重复过程。
0. 写在前面
我们在进行数据分析时,有时候需要变量两两之间作对比。但目前的问卷多为李克特量表,采用5点或7点计分。这时,我们需要对各题目答案大小进行两两比较,得到0/1形式的数据。
本文提供了用Python对李克特式数据进行两两比较的转化,以便后续进行瑟斯顿IRT迫选分析。
本例中使用的量表为奥尔波特价值观量表的第二部分,该量表测量6个价值观维度(经济型、科学型、审美型、精神型、政治型、社会型),共15题,每题4个答案,被试需按照自己的赞同程度对四个答案进行4/3/2/1排序。
举个量表的栗子:

注:
本例中奥尔波特价值观量表的计分方式采用原始计分方式即可,虽然产生自模式数据,但转换为瑟斯顿IRT分析后,维度间相关过高,故不予推荐。
如有更好的改进办法,欢迎指教讨论。
1. 处理数据内容及操作
如下图所示,所需处理数据行列数为1024*60,所需操作为:每4列为一组(对照奥尔波特价值观量表的4个答案),每组中各列两两对比,若后一列比前一列大,在新表中输出1,否则输出0。
以此类推,每一组原始数据生成6列新数据(对照量表测量6个价值观维度),总计生成90列新数据。
生成新表后,将其转化为TXT文件,以便后续操作。
以上操作可使用EXCEL自带IF函数完成,但重复内容过多,编写python程序可以减少大量工作内容。

2. 源代码及部分代码解析
import xlrd
from xlwt import *
import pandas as pd
#------------------读数据---------------------------------
fileName="文件路径/scores.xlsx"
data = xlrd.open_workbook(fileName)
sh = data.sheet_by_name("Sheet1") #通过索引顺序获取
#------------------获取表信息---------------------------------
nrows=sh.nrows #获取行数1024
ncols=sh.ncols #获取列数60
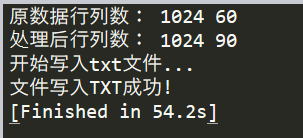
print('原数据行列数:',nrows,ncols)
#------------------新建表格---------------------------------
book = Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet') #创建一个sheet
#------------------对比+循环输出到新表------------------
for k in range(0,ncols-1,4):
for j in range(1,4):
for i in range(0,nrows): # 循环写入一列
if sh.cell_value(i,k+j)>sh.cell_value(i,k+0):
sheet.write(i,int(1.5*k)+j-1,'1')
else:
sheet.write(i,int(1.5*k)+j-1,'0')
for n in range(2,4):
for i in range(0,nrows):
if sh.cell_value(i,k+n)>sh.cell_value(i,k+1):
sheet.write(i,int(1.5*k)+n+1,'1')
else:
sheet.write(i,int(1.5*k)+n+1,'0')
for m in range(3,4):
for i in range(0,nrows):
if sh.cell_value(i,k+m)>sh.cell_value(i,k+2):
sheet.write(i,int(1.5*k)+m+2,'1')
else:
sheet.write(i,int(1.5*k)+m+2,'0')
#-------------------存储新表格------------------
book.save("文件路径/Result.xls")
#------------------打印新表的数据------------------
data = xlrd.open_workbook("D:/Python38/PyProjects/Excel_Python/Result.xls")
table = data.sheet_by_name("Sheet") #通过索引顺序获取
nrows=table.nrows #获取行数1024
ncols = table.ncols #获取列数90
print('处理后行列数:',nrows,ncols)
#------------------转换txt格式------------------
df = pd.read_excel("文件路径/Result.xls",header=None) # 使用pandas模块读取数据
print('开始写入txt文件...')
df.to_csv("文件路径/Result.txt",header=None,index=False) # 写入,逗号分隔
print('文件写入TXT成功!')
3. Py程序运行结果
执行程序后,所在文件夹生成Result.txt和Result.xls文件。
















 1066
1066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









