









sPecIalized KnowledgE and Rationale Augmented Generation(PIKE-RAG)框架https://github.com/microsoft/PIKE-RAG,通过有效地提取、理解和组织专业知识,并构建连贯的推理逻辑,解决了现有RAG系统在工业应用中的局限性。实验结果表明,PIKE-RAG在处理复杂的多跳问答和法律知识问答任务时表现出色,具有较高的准确率和F1分数。PIKE-RAG框架主要由几个基本模块组成,包括文档解析、知识提取、知识存储、知识检索、知识组织、以知识为中心的推理以及任务分解和协调。通过调整主模块内的子模块,可以实现专注于不同能力的RAG系统,以满足现实场景的多样化需求。
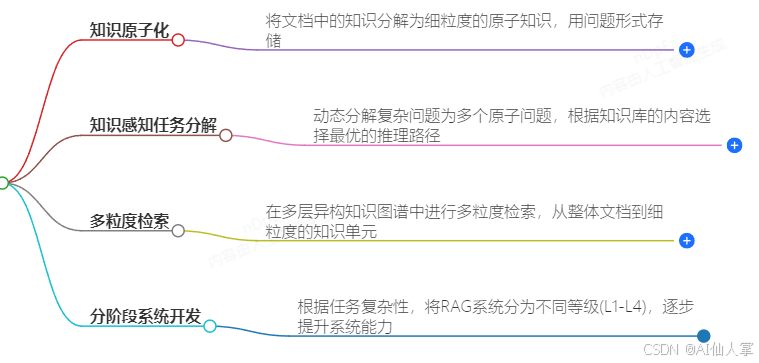
PIKE-RAG 框架关键组件
PIKE-RAG 框架包括以下几个关键组件:
- 文件解析:处理多种格式的文件,将其转换为机器可读的格式。
- 知识提取:从文本中提取知识单元,构建知识图谱。
- 知识存储:将提取的知识以多种结构化格式存储。
- 知识检索:使用混合检索策略获取相关信息。
- 知识组织:对检索到的知识进行组织和处理。
- 任务分解与协调:将复杂任务分解为子任务,并协调检索和推理操作。
- 知识中心推理:基于组织的知识进行推理,生成答案。

创新点
-
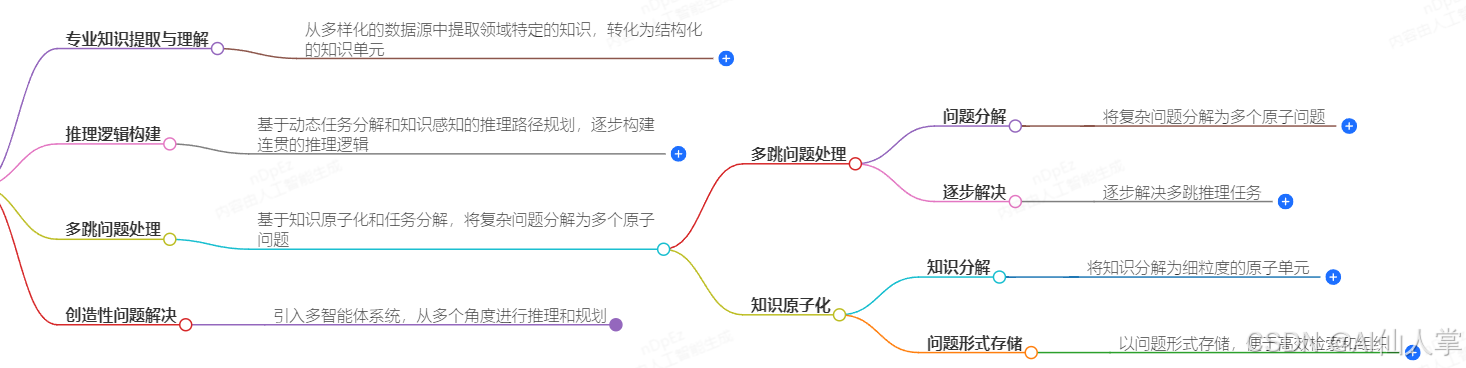
知识提取和表示:PIKE-RAG框架借助文件解析模块,将领域特定文档转换为机器可读格式,并生成图结构来表示信息资源层、语料库层和蒸馏知识层。
-
任务分解和协调:框架引入任务分解和协调模块,把复杂问题分解为多个子问题,通过迭代机制逐步收集相关信息并进行推理。根据知识提取、理解和利用的难度,将任务分为事实性问题、可链接推理问题、预测性问题和创造性问题四类,并将 RAG 系统能力分为四个级别,对应不同类型问题的解决能力。
-
知识感知任务分解训练:提出知识感知的任务分解器训练策略,通过采样上下文和创建多样化交互轨迹收集推理轨迹数据,训练分解器将领域特定推理逻辑融入任务分解和结果寻求过程。
在PIKE-RAG框架中,知识感知任务分解(Knowledge-Aware Task Decomposition)是一种策略,用于将复杂的问题分解为更小、更易于管理的子任务。这种分解方法通过利用领域特定的知识库来增强问题的解决能力。以下是知识感知任务分解工作流的实现步骤: -
初始化上下文:
- 初始化一个空的上下文集合 C 0 \mathcal{C}_0 C0,用于存储在任务分解过程中收集到的信息。
-
生成原子问题提案:
- 在每次迭代中,使用大语言模型(LLM)根据当前的上下文 C t − 1 \mathcal{C}_{t-1} Ct−1 生成可能的原子问题提案 { q ^ i t } \{\hat{q}_i^t\} {q^it}。这些提案是为了帮助完成任务而生成的潜在有用问题。
-
检索相关原子候选项:
- 对于每个原子问题提案 q ^ i t \hat{q}_i^t q^it,从知识库中检索与之相关的原子候选项。这些候选项是从知识库中提取的,满足与提案的相似性阈值 δ \delta δ 的条件。
-
选择最有用的原子问题:
- 使用LLM和当前的上下文 C t − 1 \mathcal{C}_{t-1} Ct−1 以及所有生成的原子问题提案,选择最有用的原子问题 q t q^t qt。这个选择过程是基于LLM对问题的理解和上下文的评估。
-
处理无原子问题的情况:
- 如果没有合适的原子问题被选择(即 q t q^t qt 为空),则保持上下文不变并终止迭代。
-
获取相关片段:
- 如果选择了有用的原子问题 q t q^t qt,则从知识库中获取与该问题相关的片段 c t c^t ct。
-
更新上下文:
- 将获取的片段 c t c^t ct 添加到上下文集合 C t \mathcal{C}_t Ct 中,以便在下一次迭代中使用。
-
迭代终止条件:
- 迭代可以最多进行N次,N是一个超参数,用于控制计算成本。如果达到最大迭代次数或满足其他终止条件(如没有高质量的问题提案、没有高度相关的原子候选项、没有合适的原子知识选择等),则终止迭代。
-
生成答案:
- 使用最终的上下文 C t \mathcal{C}_t Ct 来生成问题的答案 a ^ \hat{a} a^。
通过这种方式,知识感知任务分解能够有效地将复杂问题分解为多个子问题,并利用领域特定的知识库来逐步解决这些问题。这种方法不仅提高了问题解决的效率,还增强了系统的推理能力和准确性。
任务分类
根据知识提取、理解和应用的难度,将任务分为四类:
- 事实性问题:直接从语料库中提取特定、明确的信息。
- 可链接推理问题:需要跨多个来源收集信息并执行多步推理。
- 预测性问题:基于现有数据进行归纳推理和预测。
- 创造性问题:需要领域特定逻辑和创造性问题解决能力。
系统能力级别
根据任务分类,将 RAG 系统分为四个级别:
- L1:能够准确回答事实性问题。
- L2:能够处理复杂的链接推理问题。
- L3:能够进行预测性问题的推理。
- L4:能够提出创造性的解决方案。
详细实现
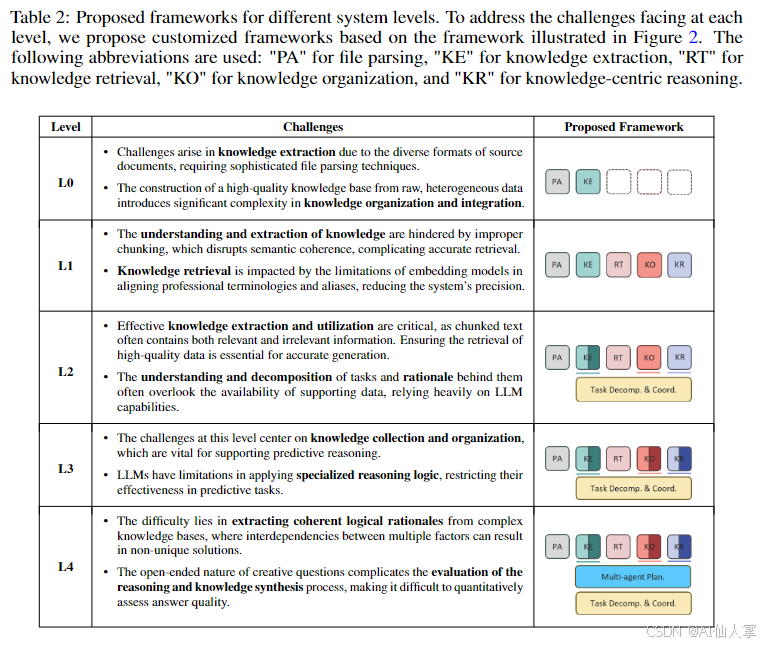
知识库构建(L0 级别)
- 文件解析:使用 LangChain 等工具处理多种文件格式,包括扫描图像和表格。
- 知识组织:构建多层异构图,包括信息资源层、语料库层和蒸馏知识层。
事实性问题 RAG 系统(L1 级别)
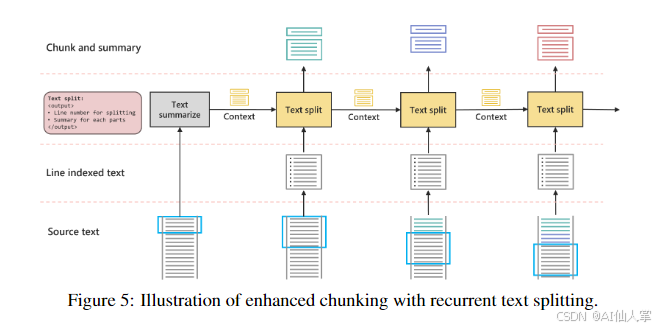
- 增强分块:通过迭代分块算法,保持上下文并生成每个分块的摘要。
- 自动标记:使用 LLMs 提取关键因素并生成语义标签,以缩小查询和语料库之间的领域差距。
- 多粒度检索:在多层异构图上执行多粒度检索,以提高检索精度。

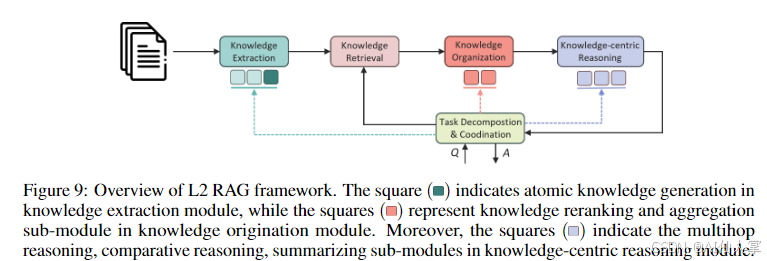
可链接推理问题 RAG 系统(L2 级别)
- 知识原子化:将文档分块中的知识原子化,生成相关问题作为知识索引。
- 知识感知任务分解:根据知识库内容选择最有效的分解策略,动态管理任务分解。
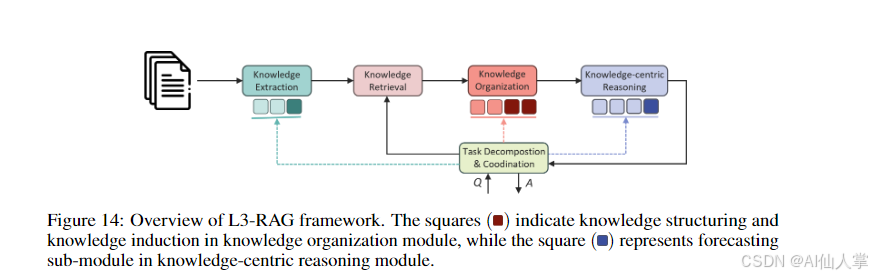
预测性问题 RAG 系统(L3 级别)
- 知识结构化和归纳:增强知识组织模块,以支持预测性任务。
- 预测推理:引入预测子模块,基于组织的知识进行预测。
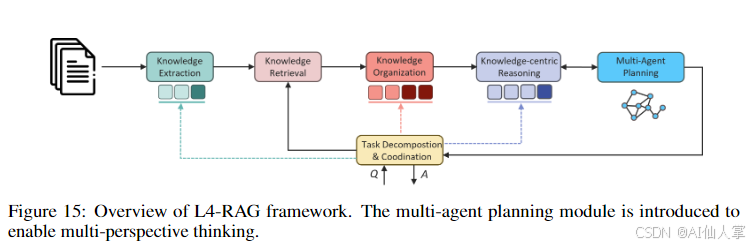
创造性问题 RAG 系统(L4 级别)
- 多智能体规划:引入多智能体系统,从不同角度进行推理,生成创新解决方案。
关键问题及回答
问题1:PIKE-RAG框架如何在知识提取和表示方面进行改进?
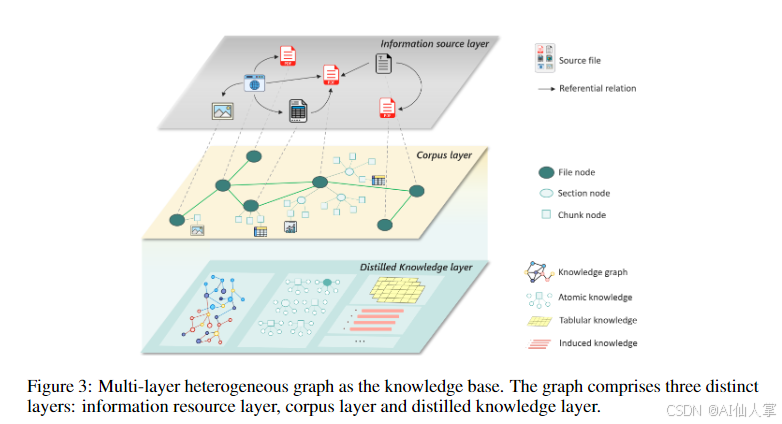
PIKE-RAG框架通过文件解析模块将领域特定的文档转换为机器可读格式,并生成图结构以表示信息资源层、语料库层和蒸馏知识层。信息资源层捕捉多样化的信息源,语料库层组织解析后的信息成段落和块,并保留文档的原始层次结构,蒸馏知识层则将语料库进一步蒸馏成结构化知识(如知识图谱、原子知识和表格知识)。这种多层异构图的表示方法不仅增强了知识的组织和集成,还为下游任务提供了语义理解和基于推理的检索能力。
问题2:PIKE-RAG框架中的任务分解和协调模块是如何工作的?
PIKE-RAG框架引入任务分解和协调模块,将复杂问题分解为多个子问题,通过迭代机制逐步收集相关信息和进行推理。具体步骤为:
- 将原始问题输入任务分解模块,生成初步分解方案,概述检索步骤、推理步骤和其他必要操作;
- 知识检索模块根据分解方案检索相关信息;
- 知识组织模块对检索到的知识进行处理和组织;
- 知识中心推理模块利用组织好的知识进行推理,生成中间答案;
- 任务分解模块根据更新的相关信息和中间答案重新生成分解方案,重复上述过程直至达到满意答案。这种迭代机制确保逐步收集相关信息和进行推理,提高答案的准确性和全面性。
对比传统RAG
| 维度 | 传统RAG | PIKE-RAG |
|---|---|---|
| 知识粒度 | 粗粒度文档分块 | 细粒度原子知识单元 |
| 推理能力 | 单路径检索生成 | 多智能体协同规划与验证 |
| 系统扩展性 | 静态知识库 | 支持动态任务分解与知识库自我进化 |
| 工业场景适用性 | 适用于简单QA | 支持复杂预测与创造性问题解决 |
代码走读
def answer(self, qa: BaseQaData, question_idx: int) -> Dict:
"""
对给定qa中的问题进行逐步分解,并最终给出答案。
在给出问题的答案之前,会有一个分解 - 检索 - 选择的循环来收集有用的原子信息。在每个循环中,有三个步骤:
- 步骤1:提议。根据我们已有的原子信息对问题进行分解。步骤1的输出将是一个可能对回答最终问题有用的子问题列表;
- 步骤2:检索。使用步骤1中得到的子问题列表和我们要回答的最终问题,从向量存储中检索相关的原子信息(包括原子和源块)。步骤2的输出将是一个原子信息候选列表;
- 步骤3:选择。根据要回答的最终问题和我们已有的原子信息,从给定的候选列表中选择最有用的原子信息。步骤3的输出将是所选的原子信息(如果有的话)。
循环结束后的最后一步是让大语言模型(LLM)根据所有选择的原子信息回答原始问题。
参数:
qa (BaseQaData): 包含问题和相关信息的对象
question_idx (int): 问题的索引
返回:
Dict: 包含回答信息和分解信息的字典
"""
# 存储分解过程中的信息
decomposition_infos: dict = {}
# 存储选择的原子信息
chosen_atom_infos: List[AtomRetrievalInfo] = []
# 当选择的原子信息数量小于最大问题数量时,继续循环
while len(chosen_atom_infos) < self._max_num_question:
# 生成子问题的ID
sub_question_id: str = f"Sub{len(chosen_atom_infos) + 1}"
# 初始化该子问题ID的分解信息
decomposition_infos[sub_question_id] = {}
# 步骤1: 让LLM客户端根据当前上下文提供分解提议
# decompose: 是否需要分解,thinking: 思考过程,proposals: 提议的子问题列表
decompose, thinking, proposals = self._propose_question_decomposition(qa.question, chosen_atom_infos)
# 存储分解提议信息
decomposition_infos[sub_question_id]["proposal"] = {
"to_decompose": decompose,
"thinking": thinking,
"proposal_list": proposals,
}
# 如果不需要分解,跳出循环
if not decompose:
break
# 步骤2: 检索与子问题提议相关的原子信息
atom_info_candidates = self._retrieve_atom_info_candidates(
atom_queries=proposals,
query=qa.question,
chosen_atom_infos=chosen_atom_infos,
retrieve_id=sub_question_id,
)
# 存储检索到的信息
decomposition_infos[sub_question_id]["retrieval"] = [
{
"relevant_proposal": info.atom_query,
"sub-question": info.atom,
"relevant_context_title": info.source_chunk_title,
"relevant_context": info.source_chunk,
}
for info in atom_info_candidates
]
# 如果没有检索到原子信息候选,跳出循环
if len(atom_info_candidates) == 0:
break
# 步骤3: 让LLM客户端根据当前上下文从候选列表中选择后续子问题
# selected: 是否选择,thinking: 思考过程,chosen_info: 选择的信息
selected, thinking, chosen_info = self._select_atom_question(
qa.question,
atom_info_candidates,
chosen_atom_infos,
)
# 存储选择信息
decomposition_infos[sub_question_id]["selection"] = {
"selected": selected,
"thinking": thinking,
}
# 如果选择了信息
if selected:
# 将选择的信息添加到已选择的原子信息列表中
chosen_atom_infos.append(chosen_info)
# 存储选择的具体信息
decomposition_infos[sub_question_id]["selection"]["chosen_info"] = {
"question": chosen_info.atom,
"source_chunk_title": chosen_info.source_chunk_title,
"source_chunk": chosen_info.source_chunk,
}
else:
# TODO: 重新提议?
break
# 最后一步: 让LLM客户端根据循环中选择的所有原子信息回答原始问题
output = self._answer_original_question(qa.question, chosen_atom_infos)
# 将分解信息添加到输出中
output["decomposition_infos"] = decomposition_infos
return output
```



















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











