







🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
LLaMA 4 发布以来已经面临了大量的批评,但LLaMA 4 是继 Mistral 之后的一个新进展,展示了基于 MoE(Mixture-of-Experts,混合专家)模型的优势。
在本博客中,我们从零开始构建 LLaMA 4 的 MoE 架构,以了解它是如何实际构建的。
更多LLM图解内容可以查看
详解如何复现DeepSeek R1:从零开始利用Python构建
详解如何从零用 Python复现类似 GPT-4o 的多模态模型
复现BPE
以下是我们在GPU 上训练的 220 万参数的 LLaMA MoE 在一个微小的英语数据集上训练 3000 个epoch后的输出结果:
输入:Alice
输出:Alice 'without pictures or conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain wo ...
不要复制代码,你可以直接 GitHub 仓库clone:
LLaMA 4 MoE 架构概述
首先,让我们以一个中级技术人员的身份来理解 LLaMA 4 架构,然后通过一个例子 “the cat sat” 来看看它是如何通过架构处理的,以便更清晰地理解。
想象一下,你有一个非常艰巨的任务。与其雇佣一个对什么都懂一点的人,不如雇佣一个团队,每个成员都是某个特定领域的专家(比如电工、水管工、油漆工)。你还会雇佣一个经理,他查看当前的任务,并将其分配给最适合的专家。
AI 模型中的 MoE 就有点像这样。与其让一个巨大的神经网络试图学习一切,MoE 层有:
- 一组“专家”:这些是较小的、专门化的神经网络(通常是简单的前馈网络或 MLP)。每个专家可能擅长处理某些类型的信息或模式。
- 一个“路由器”(经理):这是另一个小型网络。它的任务是查看输入数据(比如一个词或词的一部分),并决定哪个专家最适合处理它。
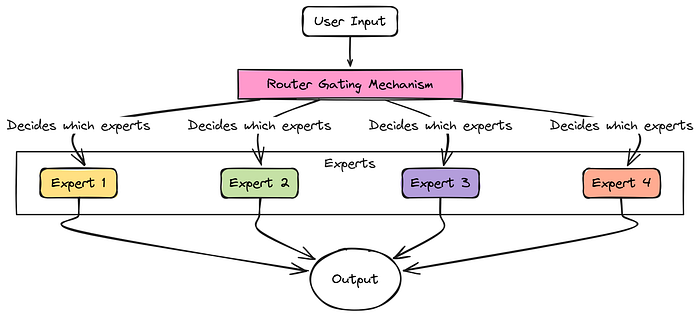
LLaMA 4 概述
假设我们的模型正在处理句子:“The cat sat。”
- 分词:首先,我们将句子分解成片段(分词):“The” “cat” “sat”
- 路由器接收分词:MoE 层接收到分词
cat(表示为一组数字,即嵌入向量)。路由器查看这个cat向量。 - 路由器选择:假设我们有 4 个专家(
E1、E2、E3、E4)。路由器决定哪些专家最适合处理cat。 - **假设它认为
E2(可能擅长处理名词?)和E4(可能擅长处理动物概念?)是最合适的选择。它会给这些选择分配分数或“权重”(例如,E2为 70%,E4为 30%)。
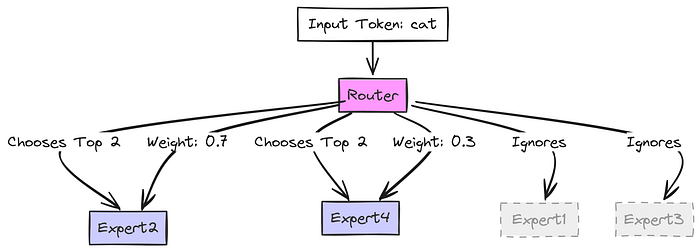
cat 向量只发送给 Expert 2 和 Expert 4。Experts 1 和 3 不处理这个分词,节省了计算量!E2 处理 cat 并生成其结果(Output_E2)。E4 处理 cat 并生成其结果(Output_E4)。
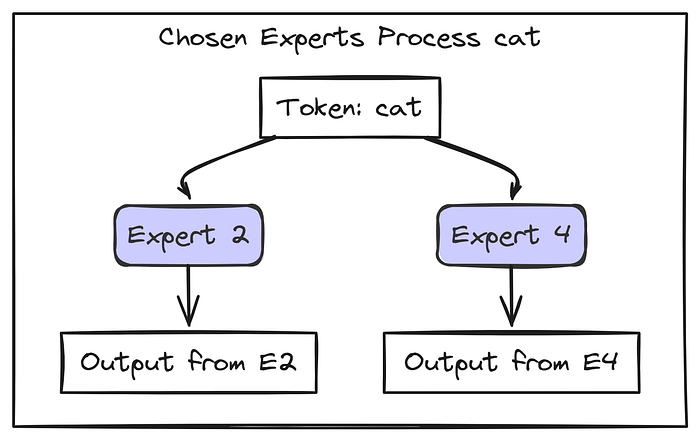
现在,我们使用路由器权重将选定专家的结果组合起来:Final_Output = (0.7 * Output_E2) + (0.3 * Output_E4)。
这个 Final_Output 就是 MoE 层传递给 cat 的结果。这个过程会针对序列中的每个分词重复进行!不同的分词可能会被路由到不同的专家。
所以,当我们的模型处理像 "The cat sat." 这样的文本时,整个流程如下所示:
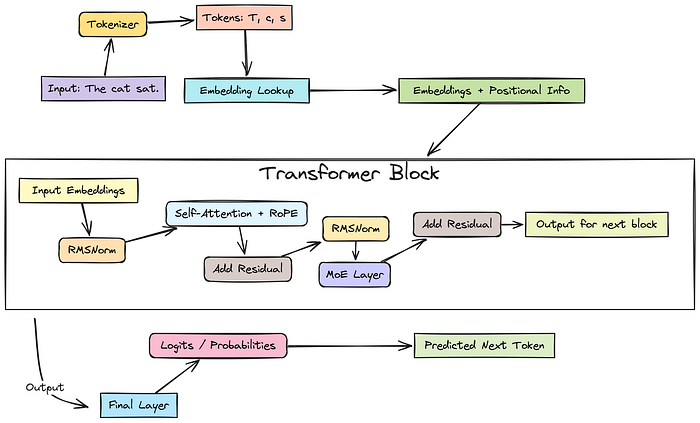
LLaMA 4 详细架构
输入文本进入分词器。分词器将分词 ID 转换为有意义的数字向量(嵌入向量),并添加位置信息(稍后在注意力中使用 RoPE)。
这些向量通过多个Transformer 块。每个块包含:
- 自注意力(分词相互查看,由 RoPE 增强)。
- MoE 层(路由器将分词发送到特定的专家)。
- 归一化(RMSNorm)和残差连接有助于学习。
最后一个块的输出进入最终层。这一层为词汇表中每个可能的下一个分词生成分数(logits)。
我们将分数转换为概率,并预测下一个分词。
现在我们对 MoE 在整个架构中的作用有了初步的了解,接下来让我们深入代码,逐步构建这些组件!我们先从搭建编码环境开始。
搭建舞台
在开始编写模型代码之前,我们需要导入我们将要使用的模块,所以让我们先从这里开始。
# 导入必要的库
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import math
import os
import collections # 用于扩展的 BPE 类似处理
import re # 用于初始分割
# --- 设备配置 ---
# 理论:设置设备(如果有 GPU 则为 'cuda',否则为 CPU),以便在可用硬件上高效处理张量操作。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备:{device}")
print("库已导入,设备已配置。")
### 输出 ###
PyTorch 版本:2.6.0+cu124
使用设备:cuda
库已导入,设备已配置。
输出确认我们已成功导入库。我将使用 Colab T4 GPU 来训练模型。如果你想在更便宜的 GPU 上训练,可以减少训练周期数。
定义训练语料库
我们需要一些文本数据来训练我们的语言模型。像 LLaMA 4 这样的真实模型是在数万亿个单词上训练的!
在我们的小例子中,只是为了看看代码是如何工作的,我们将使用刘易斯·卡罗尔的《爱丽丝梦游仙境》中的一个小段落。这个小尺寸让我们可以轻松跟踪发生了什么。
# 定义原始文本语料库用于训练
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
print(f"训练语料库已定义(长度:{len(corpus_raw)} 个字符)。")
### 输出 ###
训练语料库已定义(长度:593 个字符)。
这仅仅定义了一个包含我们示例文本的 corpus_raw 字符串变量,并打印出其总长度(593 个字符,包括空格、换行符和标点符号)。
字符级分词
计算机不懂字母,它只懂数字。分词是将文本转换为模型可以处理的数字(分词)的过程。我们将使用最简单的方法:字符级分词。
- 找出
corpus_raw中的所有唯一字符。 - 为每个唯一字符分配一个唯一的整数 ID。
- 创建映射(字典),将字符转换为 ID(
char_to_int)和将 ID 转换回字符(int_to_char)。唯一字符的总数就是我们的vocab_size。
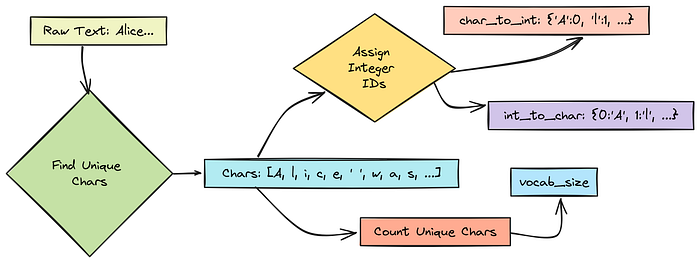
分词过程
# 找出原始语料库中的所有唯一字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)
# 创建字符到整数的映射(编码)
char_to_int = { ch:i for i,ch in enumerate(chars) }
# 创建整数到字符的映射(解码)
int_to_char = { i:ch for i,ch in enumerate(chars) }
print(f"创建了大小为:{vocab_size} 的字符词汇表")
print(f"词汇表:{''.join(chars)}")
# 可选:打印映射示例
# print(f"Char-to-Int 映射示例:{{k: char_to_int[k] for k in list(char_to_int)[:5]}}")
# print(f"Int-to-Char 映射示例:{{k: int_to_char[k] for k in list(int_to_char)[:5]}}")
### 输出 ###
创建了大小为:36 的字符词汇表
词汇表:
'(),-.:?ARSWabcdefghiklmnoprstuvwy
代码找到了 36 个唯一字符(包括换行符 \n、空格、标点符号、大写字母和小写字母)。
这个 vocab_size 对于后续设置模型层非常重要。它还创建了 char_to_int 和 int_to_char 字典用于转换,并打印了词汇表中所有字符的完整列表。
编码语料库
现在我们使用刚才创建的 char_to_int 映射,将整个 corpus_raw 字符串转换为对应的整数 ID 序列。
这个数值表示就是模型实际训练的内容。我们将这个序列存储为一个 PyTorch 张量,以便提高效率。
# 将整个语料库编码为整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]
# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long, device=device)
print(f"将语料库编码为张量,形状为:{full_data_sequence.shape}")
# 可选:显示前 50 个编码的 ID
# print(f"前 50 个编码的分词 ID:{full_data_sequence[:50].tolist()}")
### 输出 ###
将语料库编码为张量,形状为:torch.Size([593])
我们 593 个字符的文本已成功转换为一个长度为 593 的单个 PyTorch 张量(本质上是一个数字列表)。张量中的每个数字代表原始文本中的一个字符。它也被放置在我们之前指定的设备上(例如 'cuda')。
定义超参数
接下来,我们需要定义超参数设置,这些是在训练之前选择的。它们定义了模型的架构(有多大、有多少层等)以及它是如何学习的。对于我们的 LLaMA 4 类型模型,关键超参数包括:
d_model:模型中使用的主维度(嵌入维度和隐藏状态的大小)。n_layers:堆叠在一起的 Transformer 块的数量。层数越多,模型通常越强大(但速度越慢)。n_heads:多头注意力机制中并行注意力计算的数量。d_model必须能被n_heads整除。block_size:模型在训练期间查看的最大输入序列长度(也称为上下文长度)。rms_norm_eps:在RMSNorm中用于数值稳定的微小值。rope_theta:控制RoPE中使用的频率的参数。
MoE 参数:
num_local_experts:每个 MoE 层中的“专家” MLP 数量。num_experts_per_tok:路由器将每个分词发送到的专家数量(Top-K 路由)。intermediate_size_expert/shared:专家/共享 MLP 中的隐藏维度。
我们使用的值比真实的 LLaMA 4 小得多,以便在典型硬件上快速运行。
# --- 模型架构超参数 ---
# vocab_size 已经由数据确定
d_model = 128 # 嵌入维度(大幅降低)
n_layers = 4 # Transformer 块的数量(降低)
n_heads = 4 # 注意力头的数量
block_size = 64 # 最大上下文长度(序列长度)
rms_norm_eps = 1e-5 # RMSNorm 稳定性的微小值
rope_theta = 10000.0 # RoPE 的 theta 参数(从 Llama 4 的 500k 降低)
# --- MoE 特定超参数 ---
num_local_experts = 4 # 每个 MoE 层中的专家数量(从 16 降低)
num_experts_per_tok = 2 # 每个分词路由到的专家数量(Top-K,从 4 降低?)
intermediate_size_expert = d_model * 2 # 专家 MLP 中的隐藏维度(按比例缩小)
intermediate_size_shared = d_model * 2 # 共享 MLP 中的隐藏维度(按比例缩小)
# --- 注意力超参数 ---
# d_k(每个头的维度)将从 d_model 和 n_heads 推导而来
# --- 训练超参数 ---
learning_rate = 5e-4 # 学习率
batch_size = 16 # 并行处理的序列数量
epochs = 3000 # 训练迭代次数(根据需要调整)
eval_interval = 300 # 打印损失的频率
# --- 推导超参数 ---
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
d_k = d_model // n_heads # 每个头的键/查询/值维度
expert_dim = intermediate_size_expert # 为清晰起见的别名
shared_expert_dim = intermediate_size_shared # 为清晰起见的别名
让我们看看我们刚刚定义的所有参数值。
--- 超参数定义 ---
词汇表大小 (vocab_size): 36
嵌入维度 (d_model): 128
层数 (n_layers): 4
注意力头数量 (n_heads): 4
每个头的维度 (d_k): 32
最大序列长度 (block_size): 64
RMSNorm 稳定性值 (rms_norm_eps): 1e-05
RoPE theta 参数 (rope_theta): 10000.0
--- MoE 特定 ---
每个 MoE 层的本地专家数量 (num_local_experts): 4
每个分词的专家数量 (num_experts_per_tok): 2
专家中间层大小 (expert_dim): 256
共享 MLP 中间层大小 (shared_expert_dim): 256
--- 训练特定 ---
学习率:0.0005
批量大小:16
训练周期数:3000
这个输出清晰地列出了我们刚刚为模型和训练过程设置的所有配置值。我们可以看到模型维度(如 d_model=128)、MoE 中的专家数量(4)、每个分词使用的专家数量(2)、上下文窗口(block_size=64)以及训练参数(learning_rate=0.0005、batch_size=16、epochs=3000)。
训练数据准备
像我们这样的语言模型是通过预测给定之前分词的下一个分词来学习的。为了准备数据,我们在 full_data_sequence 上滑动一个长度为 block_size 的窗口。
- 输入 (
x) 是一个长度为block_size的分词块。 - 目标 (
y) 是相同块向右移动一个位置。 - 因此,对于输入
x中的每个分词,模型的目标是预测目标y中相同位置的分词。
我们从语料库中提取所有可能的重叠块。
# 创建列表以保存所有可能的输入(x)和目标(y)序列
all_x = []
all_y = []
# 遍历编码后的语料库张量以提取重叠序列
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):
# 提取输入序列块
x_chunk = full_data_sequence[i : i + block_size]
# 提取目标序列块(向右移动一个位置)
y_chunk = full_data_sequence[i + 1 : i + block_size + 1]
all_x.append(x_chunk)
all_y.append(y_chunk)
# 将列表中的张量堆叠成单个大张量
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)
num_sequences_available = train_x.shape[0]
print(f"创建了 {num_sequences_available} 个重叠的输入/目标序列对。")
print(f"train_x 的形状:{train_x.shape}") # 应为 (num_sequences, block_size)
print(f"train_y 的形状:{train_y.shape}") # 应为 (num_sequences, block_size)
# 可选:验证设备
# print(f"train_x 所在设备:{train_x.device}") # 可能仍在 CPU 上,稍后在批量处理中移动
### 输出 ###
创建了 529 个重叠的输入/目标序列对。
train_x 的形状:torch.Size([529, 64])
train_y 的形状:torch.Size([529, 64])
从我们 593 个字符的文本中,我们能够提取出 529 个长度为 64(block_size)的重叠序列。
输出确认了这一点,显示 train_x(输入)和 train_y(目标)现在是形状为 [529, 64] 的张量。
注意,这些张量可能仍然在 CPU 上;我们将在训练过程中将每个批量移动到 GPU(device)。
批量策略(随机抽样)
一次性在整个数据集上进行训练通常会占用过多的内存。相反,我们使用 mini-batch 进行训练。
一个常见的策略,也是我们这里为了简单起见所采用的,是 随机抽样。在每个训练步骤中,我们将随机选择 batch_size 个索引(从 0 到 num_sequences_available - 1),并从 train_x 和 train_y 中抓取对应的输入/目标对。
这些选定的批量随后将被移动到 device(GPU 或 CPU)上,供模型进行处理。
# 检查我们是否有足够的序列用于所需的批量大小
if num_sequences_available < batch_size:
print(f"警告:序列数量 ({num_sequences_available}) 小于批量大小 ({batch_size})。正在调整批量大小。")
batch_size = num_sequences_available
print(f"数据已准备好用于训练。将随机抽取大小为 {batch_size} 的批量。")
print("批量将在训练循环中移动到设备上。")
# 示例:如何在循环中选择一个批量
# indices = torch.randint(0, num_sequences_available, (batch_size,))
# xb = train_x[indices].to(device)
# yb = train_y[indices].to(device)
### 输出 ###
数据已准备好用于训练。将随机抽取大小为 16 的批量。
批量将在训练循环中移动到设备上。
这确认了我们的计划。我们有足够的序列(529 个)用于我们选择的批量大小(16 个)。它提醒我们,在每个训练步骤中,我们将随机抓取 16 个输入/目标序列对,并将它们发送到 GPU 或 CPU,以便进行该步骤的计算。
模型组件初始化
这是模型的第一层。它将整数分词 ID(如 train_x 中的)转换为大小为 d_model 的密集向量。可以将其视为一个查找表,其中每个分词 ID 都有自己的唯一向量表示。
这些向量捕捉了分词的一些初始“含义”,模型将在训练过程中学习并完善这些表示。
输入形状:(Batch, SequenceLength) → 输出形状:(Batch, SequenceLength, d_model)。
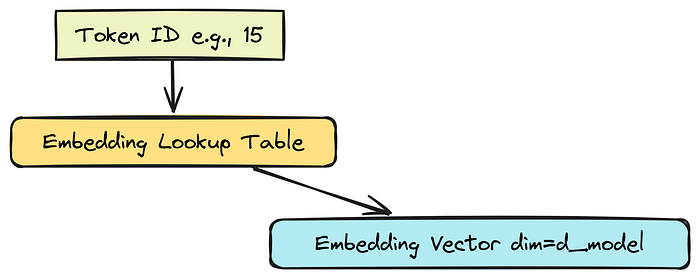
嵌入层初始化
# 初始化分词嵌入表
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
print(f"初始化分词嵌入层:")
print(f" 输入词汇表大小:{vocab_size}")
print(f" 输出嵌入维度 (d_model):{d_model}")
print(f" 权重形状:{token_embedding_table.weight.shape}")
print(f" 设备:{token_embedding_table.weight.device}")
### 输出 ###
初始化分词嵌入层:
输入词汇表大小:36
输出嵌入维度 (d_model):128
权重形状:torch.Size([36, 128])
设备:cuda:0
我们创建了 nn.Embedding 层。输出显示它已正确配置:它知道我们的 vocab_size 是 36,并将输出大小为 d_model(128)的向量。
Weight 的形状确认了查找表的大小:36 行(每个字符一行)和 128 列(嵌入维度)。它也被放置在我们的 GPU(cuda:0)上。
旋转位置嵌入(RoPE)预计算
Transformer 本身并不理解词序。位置编码会添加这种信息。
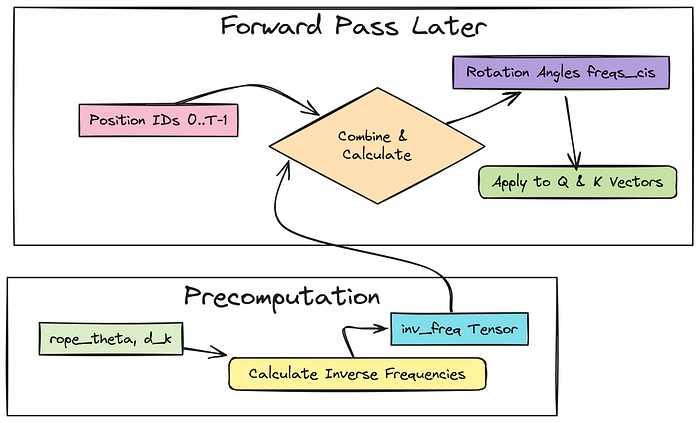
RoPE 机制
RoPE 是像 LLaMA 这样的模型中使用的一种巧妙方法。与其添加单独的位置向量,它会根据位置旋转 Query(Q)和 Key(K)向量的一部分。
旋转量取决于位置和从 rope_theta 超参数导出的预计算频率。在这里,我们预计算逆频率(inv_freq),它们是常量。
实际的旋转(使用复数 freqs_cis)将在前向传播期间动态计算,具体取决于每个序列长度。
# 预计算 RoPE 的逆频率
# 公式:1.0 / (rope_theta ** (torch.arange(0, d_k, 2) / d_k))
rope_freq_indices = torch.arange(0, d_k, 2, dtype=torch.float, device=device)
inv_freq = 1.0 / (rope_theta ** (rope_freq_indices / d_k))
print("预计算的 RoPE 逆频率 (inv_freq):")
print(f" 形状:{inv_freq.shape}") # 应为 (d_k / 2,)
print(f" 值(前 5 个):{inv_freq[:5].tolist()}")
print(f" 设备:{inv_freq.device}")
# 'freqs_cis'(复数)将在前向传播中使用这些 inv_freq 和 position_ids 计算
### 输出 ###
预计算的 RoPE 逆频率 (inv_freq):
形状:torch.Size([16])
值(前 5 个):[1.0, 0.5623413324356079, 0.3162277638912201, 0.17782793939113617, 0.10000000149011612]
设备:cuda:0
这个代码块计算并存储了 inv_freq 张量。由于我们的每个头的维度(d_k)是 32,RoPE 在成对工作,因此形状为 (16,)(即 d_k / 2)。
这些值代表旋转的基础频率。我们稍后将在前向传播中使用这个 inv_freq 张量,根据每个分词的位置计算实际的旋转角度(freqs_cis)。
RMSNorm 层初始化
归一化层有助于稳定训练。LLaMA 使用 RMSNorm(Root Mean Square Normalization),它比标准层归一化更简单、更快。
它通过对输入向量的均方根值进行归一化,然后使用可学习的参数 gamma(权重)进行缩放。我们通常没有像 LayerNorm 那样的可学习偏差(beta)。
我们需要在每个层的注意力块之前和 MoE/FFN 块之前,以及最终输出层之前各有一个 RMSNorm。
由于我们在这里是内联完成的,我们只需要初始化可学习的 gamma 权重(nn.Parameter);实际的 RMS 计算将在前向传播中进行。
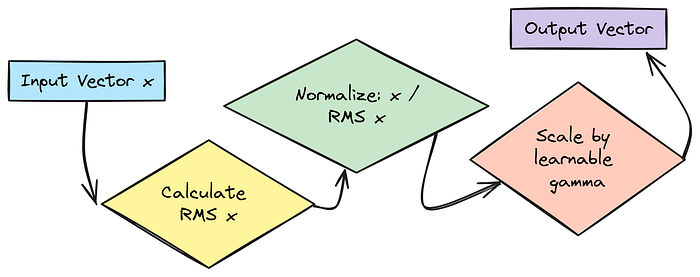
RMSNorm 层初始化
# 列表,用于存储每个 Transformer 块的 RMSNorm 层权重
rmsnorm_weights_input = [] # 注意力之前的 RMSNorm
rmsnorm_weights_post_attn = [] # MoE/FFN(注意力之后)之前的 RMSNorm
print(f"初始化 {n_layers} 层的 RMSNorm 权重...")
for i in range(n_layers):
# 注意力输入的 RMSNorm 权重
# 初始化权重为 torch.ones,类似于 nn.LayerNorm 的默认 gamma
weight_in = nn.Parameter(torch.ones(d_model, device=device))
rmsnorm_weights_input.append(weight_in)
# MoE/FFN 输入的 RMSNorm 权重(注意力之后)
weight_post = nn.Parameter(torch.ones(d_model, device=device))
rmsnorm_weights_post_attn.append(weight_post)
print(f" 初始化第 {i+1} 层的 RMSNorm 权重(输入:{weight_in.shape},注意力之后:{weight_post.shape})")
# 最终输出层之前的 RMSNorm
final_rmsnorm_weight = nn.Parameter(torch.ones(d_model, device=device))
print(f"初始化最终 RMSNorm 权重,形状:{final_rmsnorm_weight.shape}")
print("RMSNorm 权重已初始化(作为 nn.Parameter)。归一化逻辑将在前向传播中内联完成。")
### 输出 ###
初始化 4 层的 RMSNorm 权重...
初始化第 1 层的 RMSNorm 权重(输入:torch.Size([128]),注意力之后:torch.Size([128]))
初始化第 2 层的 RMSNorm 权重(输入:torch.Size([128]),注意力之后:torch.Size([128]))
初始化第 3 层的 RMSNorm 权重(输入:torch.Size([128]),注意力之后:torch.Size([128]))
初始化第 4 层的 RMSNorm 权重(输入:torch.Size([128]),注意力之后:torch.Size([128]))
初始化最终 RMSNorm 权重,形状:torch.Size([128])
RMSNorm 权重已初始化(作为 nn.Parameter)。归一化逻辑将在前向传播中内联完成。
在这里,我们为所有需要的 RMSNorm 操作创建了可学习的 gamma 权重。对于我们的 n_layers(4 层),我们需要每个层有一个权重用于注意力之前(rmsnorm_weights_input)和一个用于 MoE 块之前(rmsnorm_weights_post_attn)。
我们还需要一个最终权重(final_rmsnorm_weight),用于最后一层之后。每个权重都是一个大小为 d_model(128)的 Parameter 张量,初始化为 1。实际的 RMSNorm 计算将在前向传播中使用这些权重。
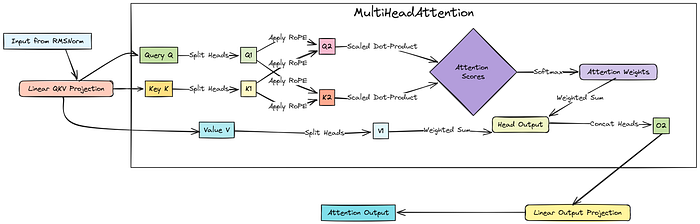
注意力层初始化(MHA)
Transformer 的核心是自注意力机制。我们使用的是多头注意力(MHA)。
对于每一层,我们需要线性投影层,将输入向量转换为 Query(Q)、Key(K)和 Value(V)空间。
- QKV 投影:这是一个单一的大型线性层,它将输入(大小为
d_model)投影到组合的 QKV 空间(大小为3 * d_model)。 - 输出投影:在使用多个头计算注意力后,另一个线性层将组合结果投影回原始的
d_model维度。
我们将为每个 Transformer 块初始化这些 nn.Linear 层。通常,这些投影中的偏差是关闭的。
多头注意力
# 列表,用于存储每个 Transformer 块的注意力层
mha_qkv_linears = [] # QKV 投影的组合线性层
mha_output_linears = [] # MHA 的输出线性层
print(f"初始化 {n_layers} 层的注意力(MHA)线性层...")
for i in range(n_layers):
# QKV 投影层
# 大型 Transformer 的 QKV 投影通常关闭偏差
qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device)
mha_qkv_linears.append(qkv_linear)
# 输出投影层
# 这里的偏差通常也是关闭的,但也可以打开
output_linear = nn.Linear(d_model, d_model, bias=False).to(device)
mha_output_linears.append(output_linear)
print(f" 初始化第 {i+1} 层的 MHA 线性层(QKV:{qkv_linear.weight.shape},输出:{output_linear.weight.shape})")
print("注意力(MHA)线性层已初始化。")
### 输出 ###
初始化 4 层的注意力(MHA)线性层...
初始化第 1 层的 MHA 线性层(QKV:torch.Size([384, 128]),输出:torch.Size([128, 128]))
初始化第 2 层的 MHA 线性层(QKV:torch.Size([384, 128]),输出:torch.Size([128, 128]))
初始化第 3 层的 MHA 线性层(QKV:torch.Size([384, 128]),输出:torch.Size([128, 128]))
初始化第 4 层的 MHA 线性层(QKV:torch.Size([384, 128]),输出:torch.Size([128, 128]))
注意力(MHA)线性层已初始化。
这为我们的 4 个 Transformer 块中的每一个都设置了注意力所需的线性层。对于每一层,我们有:
qkv_linear:一个将d_model(128)映射到3 * d_model(384)的层。其权重形状为[384, 128]。output_linear:一个将d_model(128)映射回d_model(128)的层。其权重形状为[128, 128]。
这些层被存储在列表(mha_qkv_linears 和 mha_output_linears)中,以便在前向传播中访问正确的层。
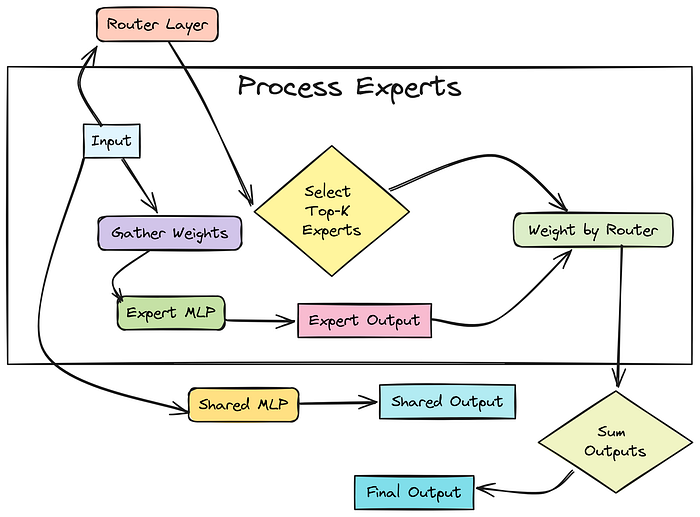
混合专家(MoE)层初始化
这是特殊的部分。在注意力块之后,我们没有使用一个大型的前馈网络(FFN),而是使用了一个 MoE 层。对于每一层,这涉及:
MoE 层
- 路由器:一个简单的线性层,它将分词的隐藏状态(大小为
d_model)作为输入,并输出每个可用“专家”的分数(logit)。 - 专家:一组(
num_local_experts)独立的小型 MLP。每个专家通常是一个“门控 MLP”,类似于 LLaMA 中的标准 FFN:它有并行的“门”和“上”投影,然后是一个激活函数(SiLU/Swish),乘法(门控)和一个“下”投影。 - 我们初始化所有专家的权重。我们将直接将这些专家权重存储为
nn.Parameter张量,而不是将它们存储为nn.Linear层的列表。 - 共享专家:一个标准的门控 MLP(就像其中一个专家一样),所有分词都会通过它。它的输出将添加到选定专家的组合输出中。
路由器决定每个分词应该路由到的 num_experts_per_tok 个专家(Top-K 路由)。然后将选定专家的输出组合起来,按路由器的置信度分数加权。
# 列表,用于存储每个层的 MoE 组件
moe_routers = [] # 路由器线性层
moe_expert_gate_up_proj = [] # 专家门控/上投影权重
moe_expert_down_proj = [] # 专家下投影权重
shared_expert_gate_proj = [] # 共享专家门控投影
shared_expert_up_proj = [] # 共享专家上投影
shared_expert_down_proj = [] # 共享专家下投影
print(f"初始化 {n_layers} 层的 MoE 和共享 MLP 组件...")
print(f" 每层的专家数量:{num_local_experts}")
print(f" 专家维度:{expert_dim}")
print(f" 共享 MLP 维度:{shared_expert_dim}")
for i in range(n_layers):
# 1. 路由器
router_linear = nn.Linear(d_model, num_local_experts, bias=False).to(device)
moe_routers.append(router_linear)
# 2. 专家(权重作为参数)
# 门控/上投影权重:(num_experts, d_model, 2 * expert_dim)
# 注意:将门控和上投影合并到一个权重矩阵中
gate_up_w = nn.Parameter(torch.empty(num_local_experts, d_model, 2 * expert_dim, device=device))
nn.init.normal_(gate_up_w, mean=0.0, std=0.02) # 示例初始化
moe_expert_gate_up_proj.append(gate_up_w)
# 下投影权重:(num_experts, expert_dim, d_model)
down_w = nn.Parameter(torch.empty(num_local_experts, expert_dim, d_model, device=device))
nn.init.normal_(down_w, mean=0.0, std=0.02) # 示例初始化
moe_expert_down_proj.append(down_w)
# 3. 共享专家(标准 MLP 层)
shared_gate = nn.Linear(d_model, shared_expert_dim, bias=False).to(device)
shared_up = nn.Linear(d_model, shared_expert_dim, bias=False).to(device)
shared_down = nn.Linear(shared_expert_dim, d_model, bias=False).to(device)
shared_expert_gate_proj.append(shared_gate)
shared_expert_up_proj.append(shared_up)
shared_expert_down_proj.append(shared_down)
print(f" 初始化第 {i+1} 层的 MoE 组件:")
print(f" 路由器权重:{router_linear.weight.shape}")
print(f" 专家门控/上投影权重:{gate_up_w.shape}")
print(f" 专家下投影权重:{down_w.shape}")
print(f" 共享门控权重:{shared_gate.weight.shape}")
print(f" 共享上投影权重:{shared_up.weight.shape}")
print(f" 共享下投影权重:{shared_down.weight.shape}")
print("MoE 和共享 MLP 组件已初始化。")
# 激活函数(内联使用)
activation_fn = nn.SiLU()
这个输出显示了我们在 4 个层中每一个初始化的 MoE 组件。对于每一层,我们创建了:
初始化 4 层的 MoE 和共享 MLP 组件...
每层的专家数量:4
专家维度:256
共享 MLP 维度:256
初始化第 1 层的 MoE 组件:
路由器权重:torch.Size([4, 128])
专家门控/上投影权重:torch.Size([4, 128, 512]) # num_experts, d_model, 2*expert_dim
专家下投影权重:torch.Size([4, 256, 128]) # num_experts, expert_dim, d_model
共享门控权重:torch.Size([256, 128])
共享上投影权重:torch.Size([256, 128])
共享下投影权重:torch.Size([128, 256])
... (第 2、3、4 层的类似输出) ...
MoE 和共享 MLP 组件已初始化。
- 路由器权重:一个线性层,将
d_model(128)映射到专家数量(4)。形状为[4, 128]。 - 专家门控/上投影权重:一个单一的参数张量,包含所有 4 个专家的组合门控和上投影权重。形状为
[num_experts, d_model, 2 * expert_dim] = [4, 128, 512]。 - 专家下投影权重:一个参数张量,包含所有 4 个专家的下投影权重。形状为
[num_experts, expert_dim, d_model] = [4, 256, 128]。 - 共享门控/上/下投影权重:标准线性层,用于共享专家 MLP,形状对应于
d_model(128)和shared_expert_dim(256)。
这些组件被存储在列表中,以便在前向传播中执行复杂的 MoE 逻辑。我们还定义了 SiLU 激活函数。
最终输出层初始化
经过所有 Transformer 层之后,最终的隐藏状态(经过最后一次 RMSNorm 之后)需要转换为下一个分词的预测。
这个最终的线性层将每个位置的 d_model 大小的向量投影到大小为 vocab_size 的向量。
输出向量中的每个元素代表词汇表中一个可能的下一个字符的原始分数(logit)。

输出层
# 最终线性层(语言建模头)
output_linear_layer = nn.Linear(d_model, vocab_size, bias=False).to(device)
print(f"初始化最终输出线性层:")
print(f" 输入维度 (d_model):{d_model}")
print(f" 输出维度 (vocab_size):{vocab_size}")
print(f" 权重形状:{output_linear_layer.weight.shape}")
print(f" 设备:{output_linear_layer.weight.device}")
### 输出 ###
初始化最终输出线性层:
输入维度 (d_model):128
输出维度 (vocab_size):36
权重形状:torch.Size([36, 128])
设备:cuda:0
我们初始化了最终的 nn.Linear 层。它将 d_model(128)作为输入维度,并输出 vocab_size(36)个 logits。权重形状 [36, 128] 确认了这种映射。
因果掩码预计算
在像这样的仅解码器 Transformer 中,当预测位置 t 的分词时,模型只能关注位置 0 到 t(包括它自己)的分词,而不能关注未来的分词(t+1、t+2 等)。
因果掩码强制执行这一点。它是一个在注意力计算中使用的矩阵。我们创建一个下三角矩阵(大小为 block_size x block_size),模型可以关注的位置值为(比如 1),不能关注的位置值为(比如 0)。
这个掩码在注意力的 softmax 步骤之前应用,有效地将未来位置的分数设置为负无穷大。我们为最大序列长度(block_size)预计算这个掩码。
# 创建因果自注意力的下三角掩码
# 值为 1 的位置表示可以关注,值为 0 的位置表示被掩码。
# 形状:(1, 1, block_size, block_size),以便与 (B, n_heads, T, T) 广播
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device))
causal_mask = causal_mask.view(1, 1, block_size, block_size)
print("预计算的因果注意力掩码:")
print(f" 形状:{causal_mask.shape}")
print(f" 是否需要梯度:{causal_mask.requires_grad}")
# 可选:可视化较小 block_size 的掩码
# if block_size <= 8:
# print(causal_mask[0, 0].cpu().numpy())
### 输出 ###
预计算的因果注意力掩码:
形状:torch.Size([1, 1, 64, 64])
是否需要梯度:False
这创建了因果掩码。它是一个张量,其下三角(包括对角线)填充了 1,其余部分填充了 0。
形状 [1, 1, 64, 64] 是为了方便与注意力分数张量(形状为 [Batch, n_heads, SeqLen, SeqLen])在前向传播中进行广播。它不需要梯度,因为它是一个固定的值。
训练设置
优化器是根据反向传播(学习)期间计算的梯度更新模型权重的算法。我们需要先收集模型中所有需要训练的参数(即 requires_grad=True 的参数)。
这包括嵌入表的权重、所有线性层(QKV、output、MoE 路由器、共享专家)的权重,以及我们为 RMSNorm 权重和 MoE 专家权重创建的 nn.Parameter 张量。
# 收集所有需要梯度的模型参数
all_model_parameters = list(token_embedding_table.parameters())
# 添加 RMSNorm 权重
all_model_parameters.extend(rmsnorm_weights_input)
all_model_parameters.extend(rmsnorm_weights_post_attn)
all_model_parameters.append(final_rmsnorm_weight)
# 添加注意力线性层权重
for i in range(n_layers):
all_model_parameters.extend(list(mha_qkv_linears[i].parameters()))
all_model_parameters.extend(list(mha_output_linears[i].parameters()))
# 添加 MoE 路由器线性层权重
for i in range(n_layers):
all_model_parameters.extend(list(moe_routers[i].parameters()))
# 添加 MoE 专家权重(已经是 nn.Parameters)
all_model_parameters.extend(moe_expert_gate_up_proj)
all_model_parameters.extend(moe_expert_down_proj)
# 添加共享专家线性层权重
for i in range(n_layers):
all_model_parameters.extend(list(shared_expert_gate_proj[i].parameters()))
all_model_parameters.extend(list(shared_expert_up_proj[i].parameters()))
all_model_parameters.extend(list(shared_expert_down_proj[i].parameters()))
# 添加最终输出线性层权重
all_model_parameters.extend(list(output_linear_layer.parameters()))
# 计算总参数组数量和可训练参数总数
num_param_groups = len(all_model_parameters)
total_params = sum(p.numel() for p in all_model_parameters if p.requires_grad)
# 定义 AdamW 优化器
optimizer = optim.AdamW(all_model_parameters, lr=learning_rate)
print("优化器设置:")
print(f" 优化器:{type(optimizer).__name__}")
print(f" 学习率:{learning_rate}")
print(f" 管理 {num_param_groups} 个参数组/张量。")
print(f" 总可训练参数:{total_params:,}")
#### 输出 ####
优化器设置:
优化器:AdamW
学习率:0.0005
管理 43 个参数组/张量。
总可训练参数:2,240,640
代码成功收集了模型的所有可训练部分(43 个不同的权重/偏差张量或参数对象),并创建了使用我们指定的学习率的 AdamW 优化器。
它还计算了模型中的总可训练参数数量,大约为 224 万个——与真实模型相比,这非常小。
定义损失函数
我们需要一种方法来衡量模型的预测与实际目标分词之间的“错误”程度。由于预测下一个分词是一个分类问题(从词汇表中选择正确的字符),标准的损失函数是 交叉熵损失。
它接受模型的输出 logits 和真实的分词 ID,并计算一个代表误差的分数。
# 定义损失函数
criterion = nn.CrossEntropyLoss()
我们初始化了 nn.CrossEntropyLoss 函数。这个 criterion 对象将在训练循环中用于计算每个批量的损失值。
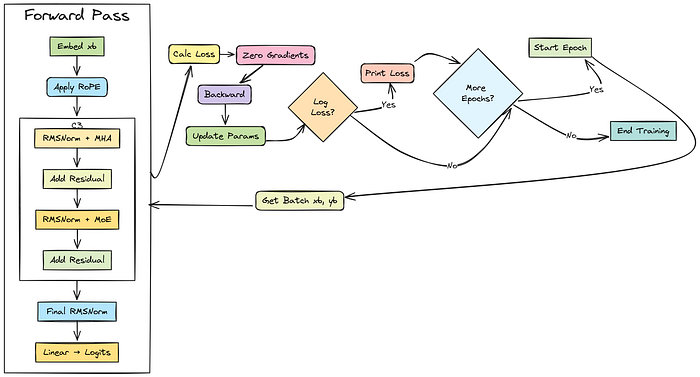
训练模型
我们将通过迭代地向模型输入批量数据,计算损失,并使用优化器更新参数来进行训练。
所有之前初始化的组件将在前向传播中协同工作。
对于设定的训练周期数,我们重复以下步骤:
训练循环
print(f"\n--- 开始训练循环,共 {epochs} 个周期 ---")
losses = []
for epoch in range(epochs):
# 随机抽取批量数据
xb, yb = train_x[torch.randint(0, num_sequences_available, (batch_size,))].to(device), \
train_y[torch.randint(0, num_sequences_available, (batch_size,))].to(device)
# 分词嵌入
token_embed = token_embedding_table(xb)
position_ids = torch.arange(xb.shape[1], device=device).unsqueeze(0)
freqs_cis = torch.polar(torch.ones_like(position_ids),
(inv_freq.unsqueeze(0).unsqueeze(-1).expand(xb.shape[0], -1, 1).float() @
position_ids.unsqueeze(1).expand(xb.shape[0], -1).float()).transpose(1, 2))
x = token_embed
for i in range(n_layers):
# RMSNorm 和注意力
x_norm = (x.float() * torch.rsqrt(x.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * rmsnorm_weights_input[i]
qkv = mha_qkv_linears[i](x_norm).view(xb.shape[0], xb.shape[1], n_heads, 3 * d_k).chunk(3, dim=-1)
q, k, v = qkv[0], qkv[1], qkv[2]
q_rope, k_rope = q.float().reshape(xb.shape[0], xb.shape[1], n_heads, -1, 2), k.float().reshape(xb.shape[0], xb.shape[1], n_heads, -1, 2)
q, k = torch.view_as_real(torch.view_as_complex(q_rope) * freqs_cis.unsqueeze(2)).flatten(3), \
torch.view_as_real(torch.view_as_complex(k_rope) * freqs_cis.unsqueeze(2)).flatten(3)
attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)
attn_scores = attn_scores.masked_fill(causal_mask[:,:,:xb.shape[1],:xb.shape[1]] == 0, float('-inf'))
attention_weights = F.softmax(attn_scores, dim=-1)
attn_output = attention_weights @ v
x = x + mha_output_linears[i](attn_output.permute(0, 2, 1, 3).contiguous().view(xb.shape[0], xb.shape[1], d_model))
# MoE 块
x_norm = (x.float() * torch.rsqrt(x.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * rmsnorm_weights_post_attn[i]
router_logits = moe_routers[i](x_norm)
routing_weights, selected_experts = torch.sigmoid(torch.topk(router_logits, num_experts_per_tok, dim=-1)[0]), \
torch.topk(router_logits, num_experts_per_tok, dim=-1)[1]
x_flat = x_norm.view(-1, d_model)
selected_experts_flat = selected_experts.view(-1)
routing_weights_flat = routing_weights.view(-1)
token_idx = torch.arange(xb.shape[0] * xb.shape[1], device=device).repeat_interleave(num_experts_per_tok)
expert_inputs = x_flat[token_idx]
gate_up_states = torch.bmm(expert_inputs.unsqueeze(1), moe_expert_gate_up_proj[i][selected_experts_flat])
activated_states = activation_fn(gate_up_states.chunk(2, dim=-1)[0]) * gate_up_states.chunk(2, dim=-1)[1]
expert_outputs_weighted = torch.bmm(activated_states, moe_expert_down_proj[i][selected_experts_flat]).squeeze(1) * \
routing_weights_flat.unsqueeze(-1)
combined_expert_outputs = torch.zeros_like(x_flat)
combined_expert_outputs.scatter_add_(0, token_idx.unsqueeze(-1).expand(-1, d_model), expert_outputs_weighted)
shared_output = shared_expert_down_proj[i](
activation_fn(shared_expert_gate_proj[i](x_norm)) * shared_expert_up_proj[i](x_norm))
x = x + combined_expert_outputs.view(xb.shape[0], xb.shape[1], d_model) + shared_output
# 最终 RMSNorm 和输出
logits = output_linear_layer((x.float() * torch.rsqrt(x.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * final_rmsnorm_weight)
loss = criterion(logits.view(-1, logits.shape[-1]), yb.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
if epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个周期,损失:{loss.item():.4f}")
print("--- 训练循环完成 ---")
try:
import matplotlib.pyplot as plt
plt.plot(losses)
plt.title("训练损失随周期变化")
plt.xlabel("周期")
plt.ylabel("损失")
plt.show()
except ImportError:
print("未找到 Matplotlib,跳过损失图绘制。")
当我们开始训练时,它将开始打印训练损失。
--- 开始训练循环,共 3000 个周期 ---
第 1/3000 个周期,损失:3.8124
第 301/3000 个周期,损失:0.0734
第 601/3000 个周期,损失:0.0595
第 901/3000 个周期,损失:0.0609
第 1201/3000 个周期,损失:0.0707
第 1501/3000 个周期,损失:0.0664
第 1801/3000 个周期,损失:0.0559
第 2101/3000 个周期,损失:0.0610
第 2401/3000 个周期,损失:0.0680
第 2701/3000 个周期,损失:0.0641
第 3000/3000 个周期,损失:0.0553
--- 训练循环完成 ---
训练损失图
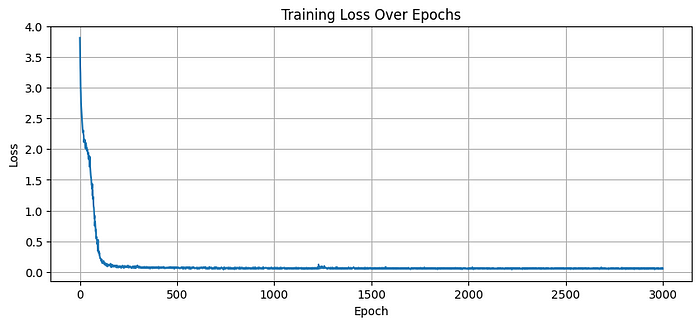
输出显示了训练进度。损失从大约 3.8 开始,并在 3000 个周期内显著下降,最终稳定在 0.05-0.07 之间。
这种急剧下降正是我们希望看到的!这意味着模型正在学习“爱丽丝梦游仙境”文本中的模式,并且在预测下一个字符方面变得越来越好。
图直观地确认了这种损失下降趋势。MoE 层、RMSNorm 和 RoPE 都协同工作。
文本生成
现在模型已经训练完成,让我们看看它能写出什么!我们从一个简短的提示(种子文本)开始。我们将这个提示转换为分词 ID。
我们还指定要生成的新分词(字符)数量。将模型组件设置为“评估模式”(使用 .eval())很重要。
如果使用了 Dropout 或 BatchNorm,这将关闭它们,确保输出一致。我们还使用 torch.no_grad(),因为我们不再训练,所以不需要 PyTorch 跟踪梯度,这会使生成过程更快并使用更少的内存。
print("\n--- 第 7 步:文本生成 ---")
# --- 生成参数 ---
seed_chars = "Alice " # 起始文本提示
num_tokens_to_generate = 200 # 要生成的新字符数量
print(f"种子文本:'{seed_chars}'")
print(f"生成 {num_tokens_to_generate} 个新分词...")
# --- 准备初始上下文 ---
# 将种子字符转换为分词 ID
seed_ids = [char_to_int[ch] for ch in seed_chars if ch in char_to_int]
# 创建初始上下文张量(添加批量维度)
generated_sequence = torch.tensor([seed_ids], dtype=torch.long, device=device)
print(f"初始上下文形状:{generated_sequence.shape}")
# --- 将模型组件设置为评估模式 ---
# (如果使用了 Dropout 或 BatchNorm,这是很重要的,无论如何都是好习惯)
token_embedding_table.eval()
for i in range(n_layers):
# RMSNorm 没有 eval 模式,只使用权重
mha_qkv_linears[i].eval()
mha_output_linears[i].eval()
moe_routers[i].eval()
# 专家权重(Parameters)没有 eval()
shared_expert_gate_proj[i].eval()
shared_expert_up_proj[i].eval()
shared_expert_down_proj[i].eval()
output_linear_layer.eval()
# 最终 RMSNorm 权重没有 eval()
print("已将模型组件设置为评估模式(适用时)。")
### 输出 ###
--- 第 7 步:文本生成 ---
种子文本:'Alice '
生成 200 个新分词...
初始上下文形状:torch.Size([1, 6])
已将模型组件设置为评估模式(适用时)。
这设置了生成过程。我们的起始提示是 "Alice "。我们计划生成 200 个更多字符。初始提示被转换为一个形状为 [1, 6] 的分词 ID 张量(批量中有 1 个序列,长度为 6 个分词)。相关的模型层已切换到评估模式。
生成循环
我们将一次生成一个字符,在一个循环中:
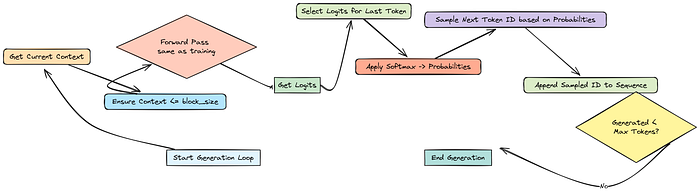
生成循环
print("开始生成循环...")
with torch.no_grad():
for _ in range(num_tokens_to_generate):
current_context = generated_sequence[:, -block_size:]
B_gen, T_gen = current_context.shape
# 分词嵌入和 RoPE 频率
token_embed_gen = token_embedding_table(current_context)
freqs_gen = torch.polar(torch.ones_like(position_ids_gen),
(inv_freq.unsqueeze(0).unsqueeze(-1).expand(B_gen, -1, 1) @ position_ids_gen.float()).transpose(1, 2))
x_gen = token_embed_gen
for i in range(n_layers):
# RMSNorm 和注意力
x_norm_gen = (x_gen.float() * torch.rsqrt(x_gen.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * rmsnorm_weights_input[i]
qkv_gen = mha_qkv_linears[i](x_norm_gen).view(B_gen, T_gen, n_heads, 3 * d_k).chunk(3, dim=-1)
q_rotated_gen = torch.view_as_real(torch.view_as_complex(qkv_gen[0].reshape(B_gen, T_gen, n_heads, -1, 2)) * freqs_gen.unsqueeze(2))
k_rotated_gen = torch.view_as_real(torch.view_as_complex(qkv_gen[1].reshape(B_gen, T_gen, n_heads, -1, 2)) * freqs_gen.unsqueeze(2))
attn_output_gen = (F.softmax((q_rotated_gen.permute(0, 2, 1, 3) @ k_rotated_gen.permute(0, 2, 1, 3).transpose(-2, -1)) * (d_k ** -0.5), dim=-1) @ qkv_gen[2].permute(0, 2, 1, 3)).view(B_gen, T_gen, d_model)
x_gen = x_gen + mha_output_linears[i](attn_output_gen)
# MoE 块
x_norm_gen = (x_gen.float() * torch.rsqrt(x_gen.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * rmsnorm_weights_post_attn[i]
routing_weights_gen = torch.sigmoid(torch.topk(moe_routers[i](x_norm_gen), num_experts_per_tok, dim=-1)[0])
expert_outputs_gen = torch.bmm(activation_fn(torch.chunk(torch.bmm(x_norm_gen.view(-1, d_model), moe_expert_gate_up_proj[i][torch.topk(moe_routers[i](x_norm_gen), num_experts_per_tok, dim=-1)[1]]).squeeze(1), 2)[0]) * routing_weights_gen, moe_expert_down_proj[i][torch.topk(moe_routers[i](x_norm_gen), num_experts_per_tok, dim=-1)[1]]).squeeze(1)
# 组合专家输出
x_gen = x_gen + expert_outputs_gen.view(B_gen, T_gen, d_model) + shared_expert_down_proj[i](activation_fn(shared_expert_gate_proj[i](x_norm_gen)) * shared_expert_up_proj[i](x_norm_gen))
# 最终 RMSNorm 和输出
logits_gen = output_linear_layer((x_gen.float() * torch.rsqrt(x_gen.float().pow(2).mean(-1, keepdim=True) + rms_norm_eps)) * final_rmsnorm_weight)
next_token = torch.multinomial(F.softmax(logits_gen[:, -1, :], dim=-1), num_samples=1)
generated_sequence = torch.cat((generated_sequence, next_token), dim=1)
print("...生成循环完成。")
生成循环已按指定的步数(200 次)运行。在循环内部(它本身不打印任何内容),模型根据到目前为止生成的序列反复预测并追加下一个字符。
解码生成序列
generated_sequence 张量现在包含了原始种子分词 ID 加上新生成的 200 个分词 ID。要查看实际文本,我们需要将这些数字转换回字符,使用我们之前创建的 int_to_char 映射。
我们将分词 ID 列表取出来,查找每个 ID 对应的字符,并将它们连接成一个字符串。
# 获取第一个(也是唯一一个)批量项的生成序列
final_generated_ids = generated_sequence[0].tolist()
# 将 ID 列表解码回字符串
decoded_text = ''.join([int_to_char.get(id_val, '[UNK]') for id_val in final_generated_ids])
print("\n--- 最终生成的文本 ---")
print(decoded_text)
### 输出 ###
--- 最终生成的文本 ---
Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain wo ...
最终结果出来了!从 "Alice " 开始,我们的训练模型生成了接下来的 200 个字符。查看输出,我们可以看到它确实学习了训练文本的风格和内容。
它继续了句子结构,使用了适当的标点符号,并生成了直接来自原始语料库的单词和短语(“without pictures or conversation?”、“So she was considering…”)。
这表明即使是我们的小模型,带有 MoE 层,也成功地根据训练数据中的模式预测了下一个字符。
它没有生成极具创意的新文本(因为训练数据很小且重复),但它展示了核心的生成能力。
保存模型状态(可选)
经过一番训练后,我们通常希望保存模型的状态。这涉及收集所有必要的信息。
# 创建一个目录来存储模型(如果它不存在的话)
save_dir = 'saved_models'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, 'llama4_moe_model.pt')
# 手动创建一个状态字典,收集所有组件
model_state = {
# 配置
'config': {
'vocab_size': vocab_size,
'd_model': d_model,
'n_layers': n_layers,
'n_heads': n_heads,
'block_size': block_size,
'rms_norm_eps': rms_norm_eps,
'rope_theta': rope_theta,
'num_local_experts': num_local_experts,
'num_experts_per_tok': num_experts_per_tok,
'intermediate_size_expert': intermediate_size_expert,
'intermediate_size_shared': intermediate_size_shared
},
# 分词器
'tokenizer': {
'char_to_int': char_to_int,
'int_to_char': int_to_char
},
# 模型参数(模块的状态字典,参数的张量)
'token_embedding_table': token_embedding_table.state_dict(),
'rmsnorm_weights_input': rmsnorm_weights_input, # 参数列表
'rmsnorm_weights_post_attn': rmsnorm_weights_post_attn, # 参数列表
'final_rmsnorm_weight': final_rmsnorm_weight, # 参数
'mha_qkv_linears': [l.state_dict() for l in mha_qkv_linears],
'mha_output_linears': [l.state_dict() for l in mha_output_linears],
'moe_routers': [r.state_dict() for r in moe_routers],
'moe_expert_gate_up_proj': moe_expert_gate_up_proj, # 参数列表
'moe_expert_down_proj': moe_expert_down_proj, # 参数列表
'shared_expert_gate_proj': [l.state_dict() for l in shared_expert_gate_proj],
'shared_expert_up_proj': [l.state_dict() for l in shared_expert_up_proj],
'shared_expert_down_proj': [l.state_dict() for l in shared_expert_down_proj],
'output_linear_layer': output_linear_layer.state_dict(),
# 注意:RoPE inv_freq 不保存,因为它可以从配置中导出
}
# 保存状态字典
torch.save(model_state, save_path)
print(f"模型状态已成功保存到 '{save_path}'")
我们训练模型的所有必要部分(配置、分词器和所有可学习的权重)都被打包到一个字典中,并保存到文件 saved_models/llama4_moe_model.pt 中。
我们可以编写单独的代码来加载这个文件,并使用模型进行生成,而无需重新运行整个训练过程。
结论
所以,我们涵盖了:
- 设置和分词:基本的环境设置和字符级分词。
- 超参数定义:从大型模型中缩小的配置值。
- 数据准备:为下一个分词预测创建输入/目标序列。
- 模型初始化(内联):显式创建和初始化组件,如分词嵌入、RMSNorm 权重、注意力线性层、RoPE 频率基础、MoE 路由器、MoE 专家权重、共享专家 MLP 和最终输出层。
- 训练循环(内联):在循环中实现完整的前向传播,展示:
- 应用 RMSNorm。
- 在 MHA 块中计算和应用 RoPE。
- MoE 前向传播:路由、专家选择(Top-K)、并行专家计算(使用 BMM)、组合专家输出(scatter_add_)以及与共享专家 MLP 的集成。
- 标准 Transformer 操作,如残差连接和注意力。
- 损失计算、反向传播和优化器步骤。
- 文本生成:在评估模式下使用训练好的模型组件进行自回归采样。



















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











