







引言
强化学习是机器学习中的一个特殊领域,与传统的监督学习或无监督学习方法大相径庭。
我们的最终目标是开发出一个所谓的智能体,它将在环境中执行最优动作。起初,智能体的表现通常很差,但随着时间推移,它会通过与环境互动,采用试错的方法来调整策略。
强化学习的美妙之处在于,相同的算法可以用来让智能体适应完全不同的、未知的且复杂的条件。
强化学习有着广泛的应用场景,尤其是在经典方法无法解决问题的情况下:
- 游戏。现有方法可以设计出最优的游戏策略,并超越人类表现。最著名的例子包括国际象棋和围棋。
- 机器人技术。先进的算法可以被集成到机器人中,帮助它们移动、搬运物体或完成家庭常规任务。
- 自动驾驶。强化学习方法可以用于自动驾驶汽车、控制直升机或无人机。

一些强化学习的应用场景
关于这篇文章
尽管强化学习是一个非常令人兴奋且独特的领域,但它仍然是机器学习中最复杂的主题之一。另外,从一开始就理解所有基本术语和概念至关重要。
出于这些原因,本文仅介绍一些关键的理论概念和思想,这些将有助于读者进一步深入强化学习。
此外,本文基于著名书籍"Reinforcement Learning"的第三章,该书由_Richard S. Sutton 和 Andrew G. Barto_撰写,我强烈推荐给所有想要深入了解的人。
除此之外,这本书还包含了一些实践练习。它们的解决方案可以在这个仓库中找到。
强化学习框架
首先,让我们了解强化学习框架,它包含几个重要的术语:
- 智能体代表一个对象,其目标是学习一种策略来优化某个过程;
- 环境充当智能体所在的"世界",由一组不同的状态组成;
- 在每个时间戳,智能体可以在环境中执行一个动作,这将把环境状态改变为新的状态。此外,智能体会收到反馈,表明所选动作的好坏。这种反馈称为奖励,以数值形式表示。
- 通过使用来自不同状态和动作的反馈,智能体逐渐学习最优策略,以最大化总奖励随时间的变化。
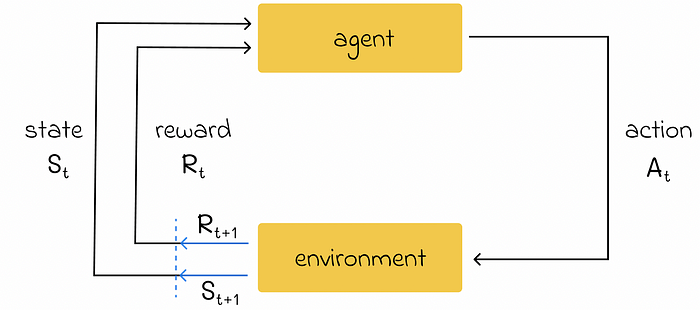
强化学习框架。图片由作者改编。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
在许多情况下,给定当前状态和智能体在该状态下的动作,状态变化可能会导致不同的奖励(而不仅仅是一个奖励),每个奖励都有其对应的概率。
下面的公式考虑了这一事实,通过对所有可能的下一个状态及其对应的奖励求和。
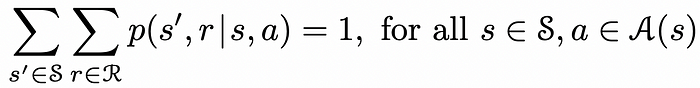
对于给定的状态和动作,转移到任何其他状态 s’ 及其对应奖励的概率之和等于 1。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
为了让事情更清楚,我们将使用符号_'_来表示变量在其下一步的状态。例如,如果 s 表示智能体的当前状态,那么 s’ 将指代智能体的下一个状态。
奖励类型
为了正式定义长期的总奖励,我们需要引入"累积奖励"(也称为"回报")这一术语,它可以有多种形式。
简单表述
让我们用 Rᵢ 表示智能体在时间戳 i 收到的奖励,那么累积奖励可以定义为从下一个时间戳到最后一个时间戳 T 之间收到的奖励之和:
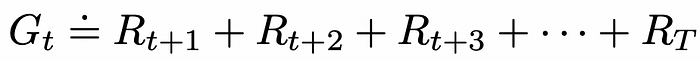
累积奖励。图片取自书籍 Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
折扣累积奖励
大多数时候,会使用折扣累积奖励。它表示与之前相同的奖励系统,只是现在总和中的每个单独奖励都乘以了一个指数衰减的折扣系数。
G t = ∑ k = 0 ∞ γ k R t + k + 1 G_t = \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} Gt=k=0∑∞γkRt+k+1
折扣累积奖励。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
公式中的 γ(有时也表示为 α)参数称为折扣率,其值介于 0 和 1 之间。引入折扣奖励确保了智能体优先选择那些能产生更多短期奖励的动作。最终,折扣累积奖励可以用递归形式表示:
G t = R t + 1 + γ G t + 1 G_t = R_{t+1} + \gamma G_{t+1} Gt=Rt+1+γGt+1
折扣累积奖励的递归方程。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
任务类型
片段式任务
在某些情况下,智能体与环境之间的互动可能包括一组独立的片段。在这种情况下,每个片段都是独立开始的,其起始状态是从状态分布中采样的。
例如,想象一下我们希望智能体学习游戏的最佳策略。为此,我们将运行一组独立的游戏,其中在每局游戏中,机器人可以获胜或失败。每局游戏中获得的奖励将逐渐影响机器人在后续游戏中使用的策略。
这些片段也被称为试验。
连续任务
同时,并非所有类型的任务都是片段式的:有些任务可能是连续的,这意味着它们没有终止状态。在这种情况下,定义累积回报并不总是可能的,因为时间戳的数量是无限的。
策略与价值函数
策略
策略 π 是所有可能状态 s ∈ S 到执行该状态下任何可能动作的概率 p 的映射。
如果智能体遵循策略 π,那么智能体在状态 s 执行动作 a 的概率 p(a | s) 等于 p(a | s) = π(s)。
根据定义,任何策略都可以表示为大小为 |S| x |A| 的表格形式。
让我们看一下迷宫游戏的示例。智能体最初位于 A1 单元格。在每一步中,智能体必须水平或垂直(不能对角线)移动到相邻单元格。当智能体到达位于 C1 的终止状态时游戏结束。单元格 A3 包含一个智能体可以收集的大奖励。单元格 B1 和 C3 是迷宫墙,无法到达。
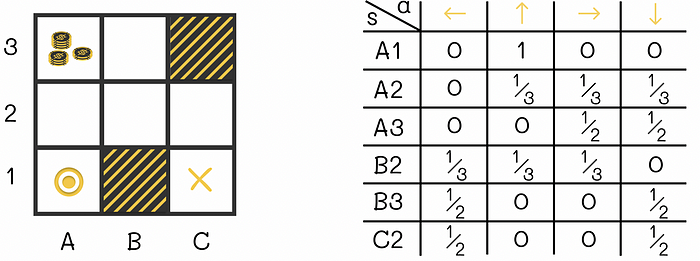
迷宫示例,有 7 个可能状态(B1 和 C3 是迷宫墙)。游戏开始时智能体在 A1,结束时到达 C1。单元格 A3 包含一个大奖励。
可以使用的最简单策略之一是随机的:在每个状态下,智能体以相等的概率随机移动到任何允许的单元格。该策略对应的策略如图所示。
所示的迷宫也是片段式任务的一个例子。在达到终止状态并获得一定奖励后,可以初始化一个新的独立游戏。
除了策略之外,在强化学习中常用到价值函数的概念,它描述了对于智能体来说处于给定状态或在当前状态下采取特定动作的好坏程度(以预期奖励为标准)。
状态价值函数
状态价值函数 v(s)(或简称为V函数)是从每个环境状态到智能体如果初始放置在该状态下并遵循特定策略 π 所获得的累积预期奖励的映射。
V函数可以表示为大小为 |S| 的一维表格。
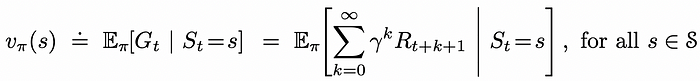
V函数在输入状态 s 的情况下输出预期奖励,前提是智能体遵循策略 π。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
为了更好地理解 V 函数的定义,让我们回到前面的例子。我们可以看到,位于 A3(即 A2、A3 和 B3)附近的单元格的 V 值比位于更远位置(如 A1、B2 和 C2)的单元格更高。这是有道理的,因为在靠近 A3 的大奖励的位置,智能体有更高的机会收集它。
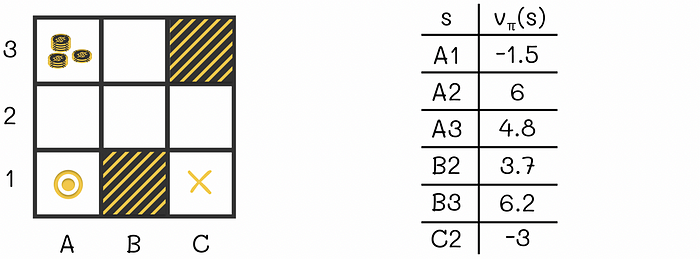
V函数示例。每个游戏状态对应智能体如果初始放置在该状态下将收到的累积奖励。
终止状态的 V 值等于 0。
动作价值函数
动作价值函数与状态价值函数的概念相似,不过它们还考虑了智能体在给定策略下可以采取的可能动作。
动作价值函数 q(s, a)(或简称为Q函数)是从每个环境状态 s ∈ S 和每个可能的智能体动作 a ∈ A 到智能体如果初始放置在该状态并采取该动作后遵循特定策略 π 将收到的预期奖励的映射。
Q函数可以表示为大小为 |S| x |A| 的表格。
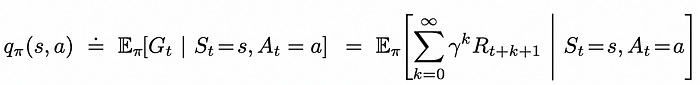
Q函数定义。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
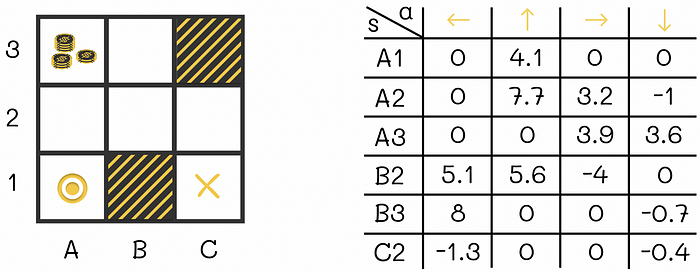
Q函数示例。对于每对(状态,动作),Q函数输出相应的预期奖励。
状态函数和动作函数之间的区别仅在于,动作价值函数需要额外的信息,即智能体在当前状态要采取的动作。状态函数只考虑当前状态,不考虑智能体的下一个动作。
V 函数和 Q 函数都是从智能体的经验中学习的。
关于 V 值和 Q 值的一个微妙之处
为什么 *q(s, a) ≠ v(s’)***,** *即* ***为什么智能体处于状态 s 并采取动作 a 导致下一个状态 s’ 的预期奖励不等于智能体处于状态 s’ 的预期奖励?***
这个问题乍一看似乎很合理。确实,让我们以上面例子中的智能体为例,它最初在单元格 B2,然后假设它过渡到 B3。从 Q 表中可以看到预期奖励 q(B2, “up”) = 5.6。同时,V 表显示预期奖励 v(B3) = 6.2。虽然 5.6 相对接近 6.2,但这两个值仍然不相等。所以最终的问题是为什么 q(B2, “up”) ≠ v(B3)?
这个问题的答案在于这样一个事实:尽管在当前状态 s 选择一个动作确定性地导致下一个状态 s’,但 Q 函数会考虑从该转换中获得的奖励,而 V 函数不会。换句话说,如果当前时间步是 t,那么预期奖励 q(s, a) 将考虑从步骤 t 开始的折扣总和:Rₜ + αRₜ₊₁ … 。对应于 v(s’) 的预期奖励在它的总和中不会有 Rₜ 项:Rₜ₊₁ + αRₜ₊₂ + … 。
值得一提的是,有时候在某些状态下采取的动作 a 可以导致多个可能的下一个状态。上面的简单迷宫示例没有展示这个概念。但我们可以为智能体的动作添加以下条件:当智能体选择一个方向在迷宫中移动时,有 20% 的概率新单元格的灯光会关闭,因此智能体会向该方向的 90° 方向移动。
引入的概念展示了相同动作和状态如何导致不同状态。因此,从相同动作和状态收到的奖励可能会有所不同。这是导致 q(s, a) 和 v(s’) 不等的另一个因素。
贝尔曼方程
贝尔曼方程是强化学习中的基础方程之一!简单来说,它递归地建立了当前和下一个时间戳的状态/动作函数值。
V 函数
通过使用期望值的定义,我们可以重写状态价值函数的表达式,使其使用下一步的 V 函数:
v ( s ) = E [ R t + 1 + γ v ( s ′ ) ] v(s) = \mathbb{E}[R_{t+1} + \gamma v(s')] v(s)=E[Rt+1+γv(s′)]
V 函数的贝尔曼方程。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
这个等式表达的意思很简单,当前状态 s 的 v 值等于从转换到该状态获得的奖励的期望值加上下一个状态 s’ 的折扣 v 值。
在他们的书中,Richard S. Sutton 和 Andrew G. Barto 使用了所谓的"备份图",这有助于更好地理解状态函数的流程,并捕捉贝尔曼方程中发生的概率乘法的逻辑。V 函数使用的备份图如下所示。
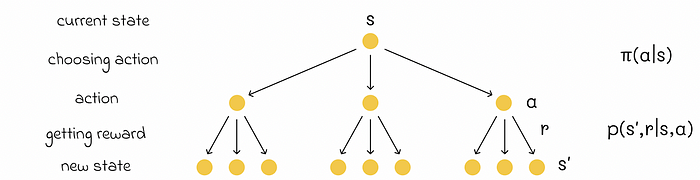
V 函数的备份图。图片由作者改编。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
贝尔曼方程在计算、近似和计算 V 函数方面起着重要作用。
Q 函数
类似于 V 函数,我们可以推导出 Q 函数的贝尔曼方程。
q ( s , a ) = E [ R t + 1 + γ q ( s ′ , a ′ ) ] q(s, a) = \mathbb{E}[R_{t+1} + \gamma q(s', a')] q(s,a)=E[Rt+1+γq(s′,a′)]
Q 函数的贝尔曼方程。来源:Reinforcement Learning. Exercise Solutions | GitHub 仓库 (@LyWangPX).
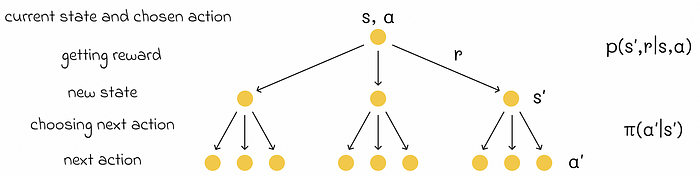
Q 函数的备份图。图片由作者改编。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
最优策略
让我们定义不同策略之间的比较操作。
如果策略 π₁ 的预期奖励大于或等于策略 π₂ 的预期奖励(对所有状态 s ∈ S 而言),则称策略 π₁ 优于或等于策略 π₂。
如果一个策略 π⁎ 优于或等于任何其他策略,则称它为最优。
每个最优策略也都有与之关联的最优 V⁎ 函数和 Q⁎ 函数。
贝尔曼最优方程
我们可以为最优策略重写贝尔曼方程。实际上,它们看起来与我们之前看到的普通贝尔曼方程非常相似,只是策略项 π(a|s) 被删除,并添加了 max 函数以从当前状态 s 选择最佳动作 a 来确定性地获得最大奖励。
v ∗ ( s ) = max a ∑ s ′ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ v ∗ ( s ′ ) ] v_*(s) = \max_a \sum_{s'} p(s' | s, a) [r(s, a, s') + \gamma v_*(s')] v∗(s)=amaxs′∑p(s′∣s,a)[r(s,a,s′)+γv∗(s′)]
V 函数的贝尔曼最优方程。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
q ∗ ( s , a ) = ∑ s ′ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ max a ′ q ∗ ( s ′ , a ′ ) ] q_*(s, a) = \sum_{s'} p(s' | s, a) [r(s, a, s') + \gamma \max_{a'} q_*(s', a')] q∗(s,a)=s′∑p(s′∣s,a)[r(s,a,s′)+γa′maxq∗(s′,a′)]
Q 函数的贝尔曼最优方程。来源:Reinforcement Learning. An Introduction. Second Edition | Richard S. Sutton and Andrew G. Barto
这些方程可以针对每个状态进行数学求解。如果找到了最优 V⁎ 函数或 Q⁎ 函数,也可以轻松计算出最优策略 π⁎,它将始终贪婪地选择最大化预期奖励的动作。
不幸的是,在实践中,数学求解贝尔曼方程非常困难,因为在大多数问题中,状态数量通常非常庞大。因此,使用强化学习方法可以近似计算最优策略,这样需要更少的计算和内存。
结论
在本文中,我们讨论了智能体如何通过试错的方式从经验中学习。引入的强化学习框架的简单性很好地概括了许多问题,同时提供了使用策略和价值函数概念的灵活方式。与此同时,最终的算法目标是计算最大化预期奖励的最优 V* 函数和 Q* 函数。
现有的大多数算法都试图近似最优策略函数。虽然在现实世界的问题中,由于内存和计算限制,几乎不可能得到最佳解决方案,但近似方法在大多数情况下都能很好地工作。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











