








Attention的学习
简介:
其实attention机制是对于当前状态的生成,对前面的状态的一个关注程度。通过当前的隐藏状态,去和之前的hidden进行比对,也相当于计算相似度。(其实代码实现的话,就是一个两个矩阵拼接进行一个Linear,最中终Encoder中会得出hidden个score,每个score对应每个hidden的值,再进行一个点积也相当于加权求和,得出batch个attention的向量,然后通过attention、decoder_input,hidden_state进行拼接再经过一个Linear得出预测值)
参考:https://wmathor.com/index.php/archives/1451/
这个博主b站视频:https://www.bilibili.com/video/BV1op4y1U7ag/
1.Encoder部分
-
encoder部分和传统的seq2seq其实是一样的
-
经过encoder 会获得两个东西
- encoder_output : 是encoder中循环神经网络的最后一层全部的hidden_state
- hidden : 是encoder中循环神经网络每层的最后一个hidden
在这里插入图片描述
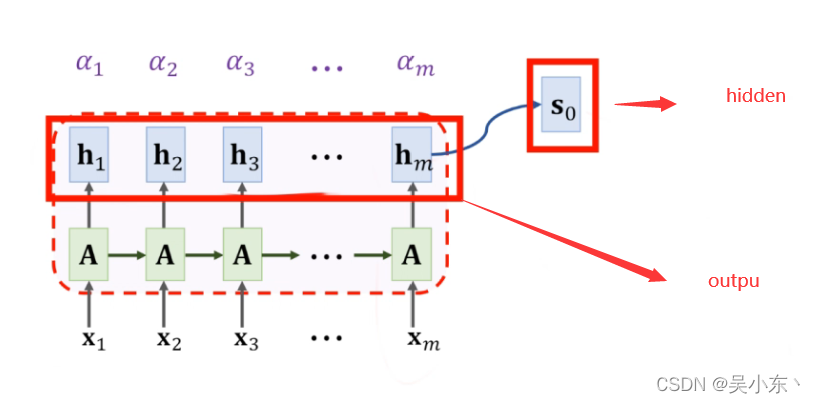
2.Attention部分
Attention分为两部分 :
-
计算权重 得出 score
-
加权求和 得出 Attention_vector
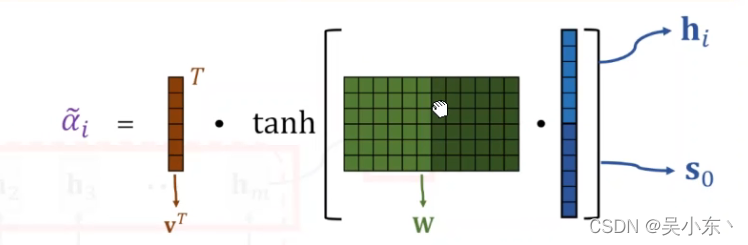
-
计算权重:
公式:
W e i g h t : a i = a l i g n ( h i , s 0 ) Weight : a_i = align(h_i,s_0) Weight:ai=align(hi,s0)具体编码的时候(伪代码):
energy=tanh(linear(torch.cat(hi,s0),hidden_num)) a_i = linear(energy,1)这里会得到seq_len个a ,就是分数,我会经过一个softmax
s o f t m a x ( a 1 − s e q l e n ) softmax(a_{1-seq_len}) softmax(a1−seqlen) -
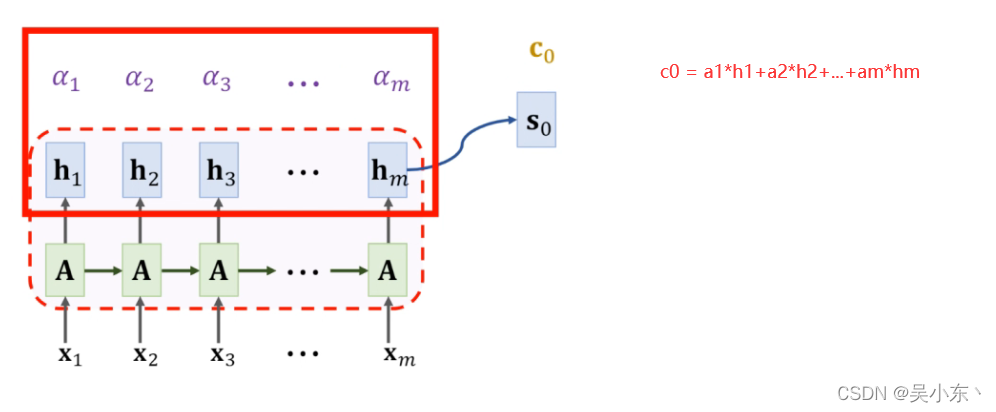
加权求和:
公式:
A t t e n t i o n − v e c t o r : c 0 = a 1 h 1 + . . . + a m h m Attention-vector:c_0 = a_1h_1+...+a_mh_m Attention−vector:c0=a1h1+...+amhm
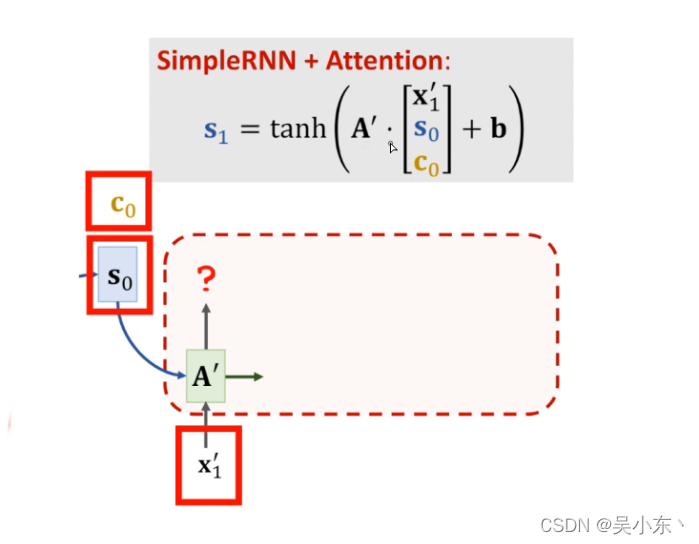
3.Decoder部分
经过前两步操作,我现在拥有的是 :
-
S t − 1 ( 上 一 个 h i d d e n ) S_{t-1} (上一个hidden) St−1(上一个hidden)
-
A t t e n t i o n − v e c Attention-vec Attention−vec
-
d e c o d e r − i n p u t decoder-input decoder−input
步骤:
-
把 Attention_vec , decoder_input 进行cat拼接,得到input
-
,把input , s(t-1) ** 传入rnn网络中,得出output** 其实就是新的 s(t)
-
最后进行预测,就是一个Linear,这个Linear是 output 和 Attention_vec 和 decoder_input 进行拼接经过Linear变成word_size_dim大小进行预测
下面给出伪代码:
input = torch.cat(c , encoder_input)
encoder_output = rnn(input,s)
pre = Linear(encoder_output,Attention_vec,encoder_input)
4.需要注意的地方
- 在Encoder阶段得到的最后一个hidden要经过一个tanh非线性变换作为Decoder的初始阶段。
- 最后做预测的时候并不用做一个softmax,因为在loss选择交叉熵的时候里面会给你做softmax














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









