









NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis
(2016 CVPR)
Amir Shahroudy, Jun Liu, Tian-Tsong Ng, Gang Wang
Notes
Github:https://github.com/shahroudy/NTURGB-D
数据集链接:
- https://rose1.ntu.edu.sg/dataset/actionRecognition/
- https://drive.google.com/open?id=1CUZnBtYwifVXS21yVg62T-vrPVayso5H
- https://drive.google.com/open?id=1tEbuaEqMxAV7dNc4fqu1O4M7mC6CJ50w
Contribution
1、introduce a large-scale dataset for RGB+D human action recognition
2、propose a new recurrent neural network structure to model the long-term temporal correlation ofthe features for each body part
Limitations in Previous 3D Action Recognition Benchmarks
1、the small number of subjects and very narrow range of performers’ ages, which makes the intra-class variation of the actions very limited.
2、only a very small number of classes are available.
3、the highly restricted camera views. For most of the datasets, all the samples are captured from a front view with a fixed camera viewpoint.
4、the highly limited number of video samples prevents us from applying the most advanced data-driven learning methods to this problem.
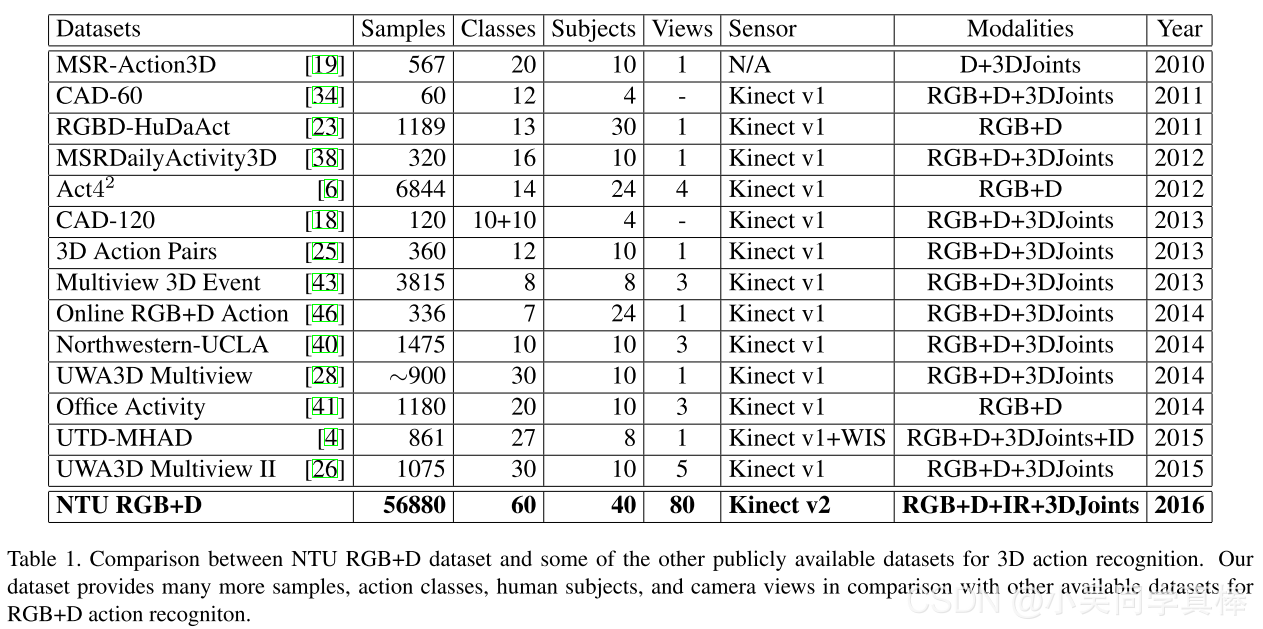
Details of NTU RGB+D
1、the number of RGB+D video samples:56, 880
2、40 different human subjects
3、60 action classes in total:
- 40 daily actions (drinking, eating, reading, etc.),
- 9 health-related actions (sneezing, staggering, falling down, etc.), and
- 11 mutual actions (punching, kicking, hugging, etc.).
4、Hardware:Microsoft Kinect v2
5、Data Modality:
- RGB videos【1920 × 1080】,
- depth sequences【512 × 424】,
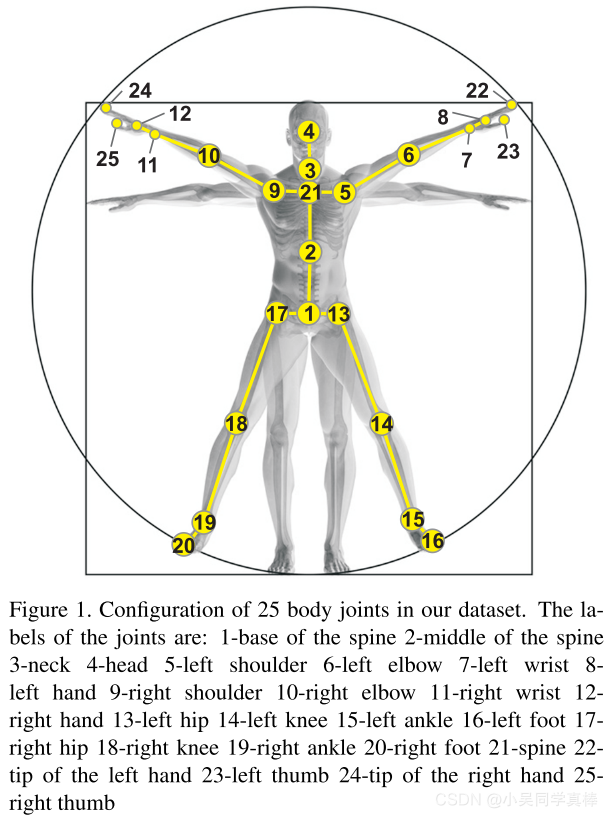
- skeleton data (3D locations of 25 major body joints), and
- infrared frames【512 × 424】
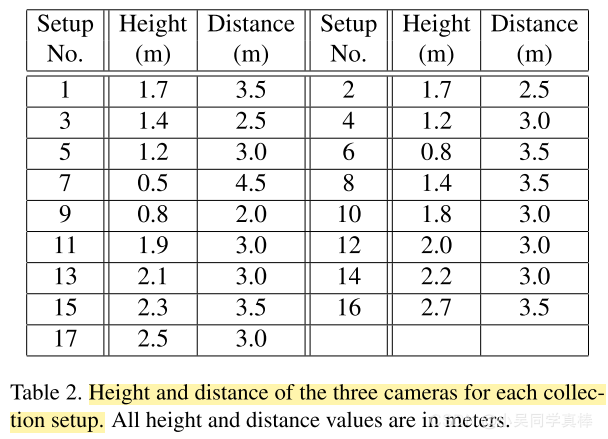
6、80(17 * 5)distinct camera viewpoints:
- used three cameras at the same time to capture three different horizontal views from the same action.
- For each setup, the three cameras were located at the same height but from three different horizontal angles: −45◦, 0◦, +45◦.
- Each subject was asked to perform each action twice, once towards the left camera and once towards the right camera.
- In this way, we capture two front views, one left side view, one right side view, one left side 45 degrees view, and one right side 45 degrees view. The three cameras are assigned consistent camera numbers. Camera 1 always observes the 45 degrees views, while camera 2 and 3 observe front and side views.
7、The age range of the subjects in our dataset is from 10 to 35 years
8、limited to indoor scenes, but we provide the ambiance inconstancy by capturing in various background conditions
9、cross-subject and cross-view evaluations metrics

Benchmark Evaluations
1、cross-subject
- split the 40 subjects into training and testing groups. Each group consists of 20 subjects.
- For this evaluation, the training and testing sets have 40, 320 and 16, 560 samples, respectively.
- The IDs of training subjects in this evaluation are: 1, 2, 4, 5, 8, 9, 13, 14, 15, 16, 17, 18, 19, 25, 27, 28, 31, 34, 35, 38;
- remaining subjects are reserved for testing.
2、Cross-View Evaluation
- we pick all the samples of camera 1 for testing and samples of cameras 2 and 3 for training.
- In other words, the training set consists of front and two side views of the actions,
- while testing set includes left and right 45 degree views of the action performances.
- For this evaluation, the training and testing sets have 37, 920 and 18, 960 samples, respectively.
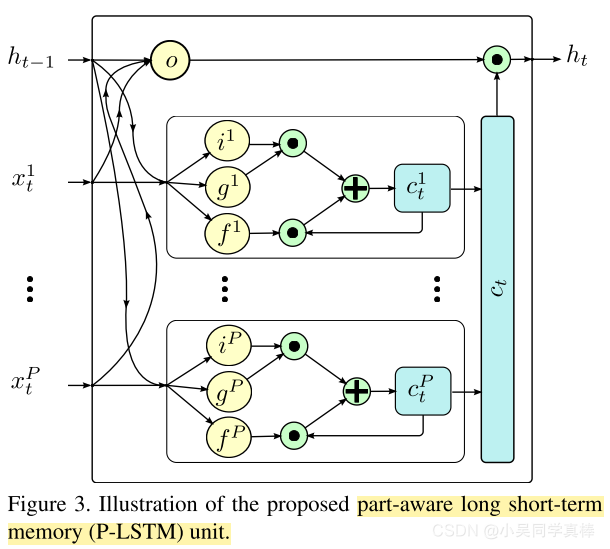
Part-Aware LSTM Network
In our model, we group the body joints into five part groups: torso, two hands, and two legs.
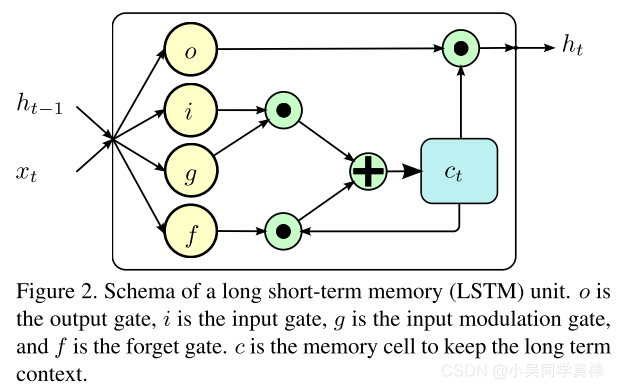
1、Traditional RNN and LSTM
2、Proposed P-LSTM
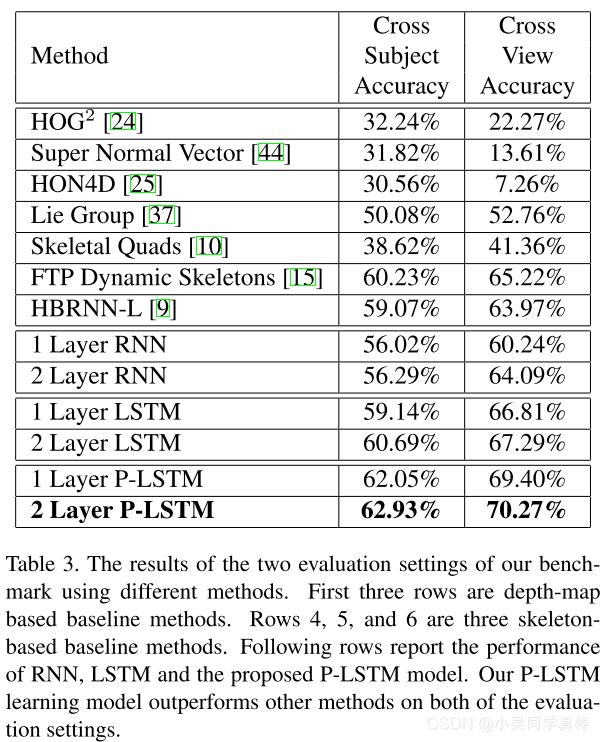
Experimantal Results

















 2533
2533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









