









Video Pose Distillation for Few-Shot, Fine-Grained Sports Action Recognition
(2021 ICCV)
James Hong, Matthew Fisher, Micha¨el Gharbi, Kayvon Fatahalian
Notes
写在前面(中文版自己总结)
之前的 AR(Action Recognition) 有两种做法:
(1)end-to-end:就是普通的 AR,输入 RGB frames,输出动作的类别。
(2)pose based:基于骨架点做的 AR
其中,end-to-end 学习到的 representation 容易 bias 到 some visual patterns,eg:basketball,rather than the action itself;
pose based 的问题就是他需要有个前提:pose label should be accurate 这就要求 pose estimation algorithm 非常 robust,或者 requires expensive human annotation work
这篇文章的做法就是利用 end-to-end 的思想,希望输入是 RGB frames,输出是动作类别。
但巧妙的是,它用一个 student encoder + decoder 去 match teacher(a pose estimator pretrained on a generic dataset)的 output feature,让 student encoder 去 focus 在一些利于进行 pose estimation 的 action representation,从而约束网络尽量少 bias 到 action-irrelated visual patterns 上。
此外,当 teacher 的 confidence 不高的时候,还可以利用一些 visual patterns 进行 AR。
但是。。。弱弱问一句,文章里提到的 weakly-supervised 是不是有点不合适?
Contributions
1. A weakly-supervised method, VPD, to adapt pose features to new video domains, which significantly improves performance on downstream tasks like action recognition, retrieval, and detection in scenarios where 2D pose estimation is unreliable.
2. State-of-the-art accuracy in few-shot, fine-grained action understanding tasks using VPD features, for a variety of sports. On action recognition, VPD features perform well with as few as 8 examples per class and remain competitive or state-of-the-art even as the training data is increased.
3. A new dataset (figure skating) and extensions to three datasets of real-world sports video, to include tracking of the performers, in order to facilitate future research on fine-grained sports action understanding.
Method
Our strategy is to distill inaccurate pose estimates from an existing, off-the-shelf pose detector — the teacher —, trained on generic pose datasets, into a — student — network that is specialized to generate robust pose descriptors for videos in a specific target sport domain. The student takes RGB pixels and optical flow, cropped around the athlete, as input. It produces a descriptor, from which we regress the athlete’s pose as emitted by the teacher. We run this distillation process over a large, uncut and unlabeled corpus of target domain videos, using the sparse set of high-confidence teacher outputs as weak supervision for the student. Since the teacher is already trained, VPD requires no new pose annotations in the target video domain. Likewise, no downstream application-specific labels (e.g., action labels for recognition) are needed to learn pose features.
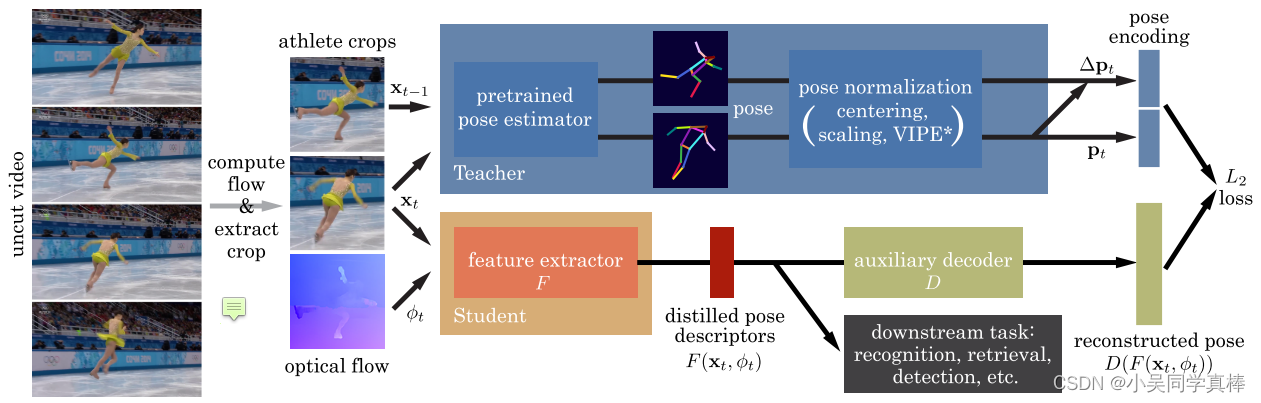
Teacher Network. (1) The first uses an off-the-shelf pose estimator [45] to estimate 2D joint positions from xt, the RGB pixels of the t-th frame. We refer to this as 2D-VPD since the teacher generates 2D joint positions. (2) Our second teacher variant further processes the 2D joint positions into a view-invariant pose descriptor, emitted as pt. Our implementation uses VIPE⋆ to generate this descriptor. VIPE⋆ is a reimplementation of concepts from Pr-VIPE [44] that is extended to train on additional synthetic 3D pose data [32, 38, 63] for better generalization. We refer to this variation as VI-VPD since the teacher generates a view-invariant pose representation.
Student Feature Extractor. we design a student feature extractor that encodes information about both the athlete’s current pose pt and the rate of change in pose ∆pt := pt − pt−1. The student is a neural network F that consumes a color video frame xt ∈ R3hw, cropped around the athlete, along with its optical flow ϕt ∈ R2hw, from the previous frame. h and w are the crop’s spatial dimensions, and t denotes the frame index.
The student produces a descriptor F (xt, ϕt) ∈ Rd, with the same dimension d as the teacher’s output. We implement F as a standard ResNet-34 [18] with 5 input channels, and we resize the input crops to 128×128.
During distillation, the features emitted by F are passed through an auxiliary decoder D, which predicts both the current pose pt and the temporal derivative ∆pt. Exploiting the temporal aspect of video, ∆pt provides an additional supervision signal that forces our descriptor to capture motion in addition to the current pose. D is implemented as a fully-connected network, and we train the combined student pathway D ◦ F using the following objective:
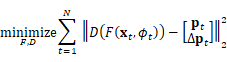
Since only F is needed to produce descriptors during inference, we discard D at the end of training.
Data selection. we exclude frames with low pose confidence scores (specifically, mean estimated joint score) from the teacher’s weak-supervision set. By default, the threshold is 0.5, although 0.7 is used for tennis.

















 8651
8651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









