









一、论文所解决的问题
本文所根据的想法是假设视频中的人穿的衣服或者饰品都是不变的,
然后通过本文所设计的方法,提取目标视频中的关节点的位置,然后用该视频fine-tune通用的CNN Pose 估计器
从而获得Personalized Pose Estimation.即个性化的人的姿态估计器
二、论文的解决方案
(1)整体架构一览
stage1:Initial Annotation(首先使用CNN估计骨架,作为初始的骨架位置)
stage2:Spatical Matching
stage3:Temporal Propagation(时间上传递关节的位置)
stage4:自动评价传递得到的关节位置的好坏,去掉那些坏的关节点
迭代:不断重复2-4
Fine-Tune:然后将最终的获得的关节位置的结果输入到CNN,fine-tune,得到个性化的骨架估计器
各个stage详细的解释:
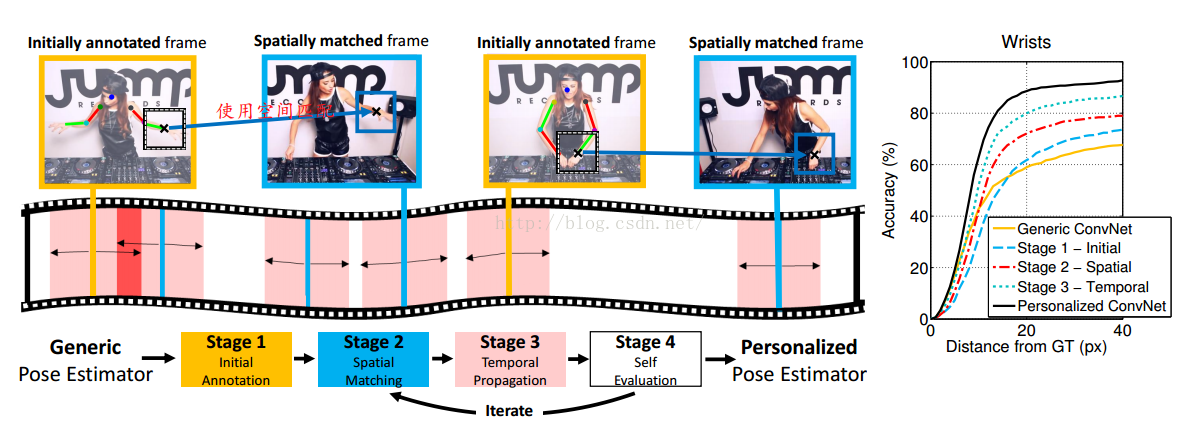
(1)Initial Annotation(初始化的姿态估计器)
可以使用yangyi的基于Part的姿态估计器,也可以使用zissermanICCV2015的CNN的姿态估计器,获得前几个帧中关节的位置
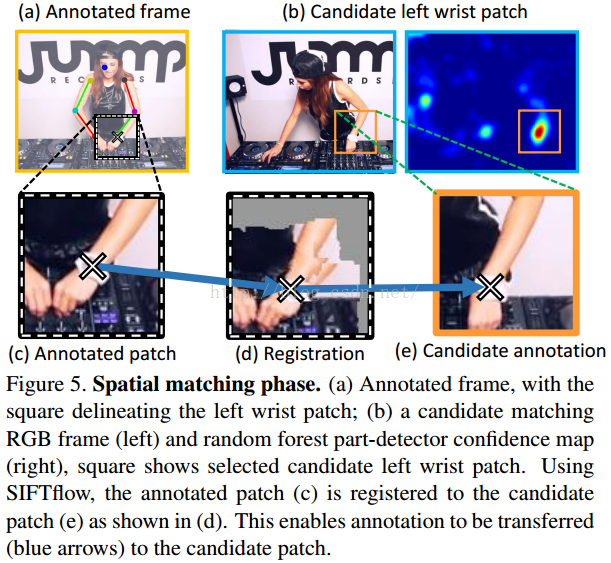
(2)Spatial Matching空间匹配关节位置(匹配下一帧或者下几个帧中的关节,并获得关节的位置)
1)获得候选匹配的图像块
首先为每个关节都都使用随机森林进行训练,采用不同大小的窗口,小窗口能够使得关节位置更准确
2)对候选的图像块进行verification
使用HOG计算相似度,如果标注的关节位置的图像块和使用随机森林获得的图像块的相似度大于某个阈值则accept,否则discard。
3)refinement
因为不同的帧之间的关节的位置不一样使用SIFTflow
https://people.csail.mit.edu/celiu/SIFTflow/ 来配准关节,获得较好的关节位置
上面的1)2)3)步骤如下图所示。
(3)Temporal Propagation(时间帧上传播关节的位置)
在temporal window内的关节的周围计算dense optical flow,代码如下
(4)自评估模型
1)annotation aggrement
当每个帧有多个标注的时候(这些标注是来自于不同初始标注的帧,也即是一开始的几个帧,分别用CNN提取关节位置)首先看给定帧关节位置的标准偏差,如果大于该阈值就accept,否则就使用parzen windows with Gaussian Kernel计算密度估计,通过选择密度最大的二维位置
2)Occlusion-aware puppet model
用lower arm puppet模型检测不正确的arm位置,以及头部,肩部、肘部关节是否遮挡
3)Lower arm puppet construction(lower arm是指wrist 和elbow这一块的膀子)
lower arm puppet模型是用可以进行旋转和缩放的矩形进行表示的,该矩形内可以使用HOG特征或者用RGB值作为两个线性SVM的输入,进行二值分类(通过与不通过)。只有两个分类器的结果都为通过的时候才认为lower arm 的关节位置是正确的。
具体的训练是用CNN所提取出来的lower arm的关节位置作为正样本,以及将这些正样本加入一些噪声作为负样本进行训练
4)遮挡检测
使用关节位置的一个矩形框内的HOG以及RBG值作为输入,训练两个SVM来判断头部、肩部以及肘部是不是遮挡。
如果关节被遮挡,则不跟踪,直到关节不再遮挡
5)discard annotation
如果1)中发现低于阈值,则丢弃
如果2)中发现lower arm检测通不过则丢弃
6)修正失败的annotation
通过在失败的annotation周围进行随机采用,然后再进行评估,说不定就可以找到正确的关节位置。
三、论文中的方案解决该问题,解决到了什么程度?
论文解决的问题是视频中前几帧来初始化,然后利用本文提出的方法直接定位关节位置,用本文的自评价模型对关节位置进行评估,通过本文的方法获得视频中后续帧的关节的位置,利用这些关节位置去fine-tune,CNN用于骨架提取。
四、其他未能考虑的问题
本文中虽然考虑了关节的遮挡问题,但是解决的方法并没有实现End To End CNN。只是利用HOG以及RGB的值用SVM进行分类来判断关节是否遮挡。
五、实验
(1)结果
不同数据集的比较结果
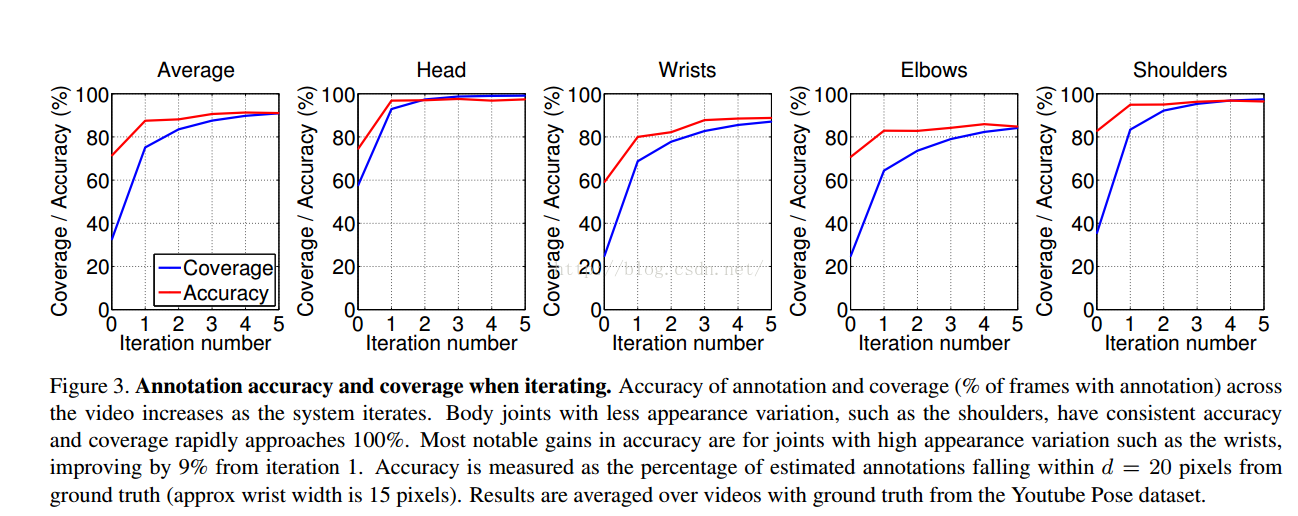
迭代次数变化的影响
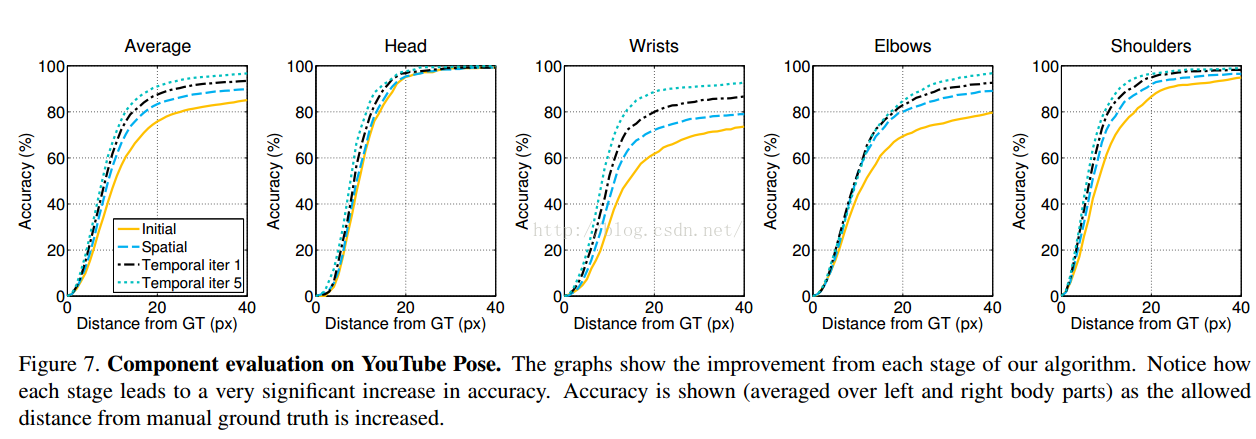
在本文算法中的每个阶段(四个阶段:初始化、Spatial Matching, Temporal Propagation再这样循环进行Spatial Matching,Temporal Propagation下去)的各个关节的精确度。
作者说:spatial matching头部和肩部的准确度已经超过baseline,原文如下:
In comparing the stages of the algorithm on the YouTube
data, by Stage 2 (spatial matching) the head and shoul
der accuracy already exceeds all baselines. By stage 3
(temporal propagation), the system outperforms all base
lines across all body joints. As mentioned above, spatial
matching helps propagate annotations to frames with simi
lar poses but different local background content. This oc
curs frequently in the BBC Pose dataset since signers are
overlaid on moving background content from the broad
cast material. Example pose estimates from personalized
data, by Stage 2 (spatial matching) the head and shoul
der accuracy already exceeds all baselines. By stage 3
(temporal propagation), the system outperforms all base
lines across all body joints. As mentioned above, spatial
matching helps propagate annotations to frames with simi
lar poses but different local background content. This oc
curs frequently in the BBC Pose dataset since signers are
overlaid on moving background content from the broad
cast material. Example pose estimates from personalized
ConvNets are shown for all datasets in Fig8.
最后作者还讨论了:如果将本文方法用于多个视频的自动提取,然后再将这些视频fine-tune用于骨架提取的CNN是不是性能有提升。
作者说本文是personalized CNN pose estimation,说的是一个视频。所以最后讨论多个视频去fine-tune CNN。
结果表明还是有效果(我觉得是废话,只要样本多,肯定CNN的效果是很好的。)

(2)代码
没找到















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









