







1.BFS
优先访问最先发现的节点,可以根据FIFO队列的特点,选用队列实现
可以实现连通域分解和最短路径等问题。
等同于树结构中的层次遍历
//whole graph
template <typename Tv, typename Te>
void Graph<Tv,Te>::bfs(int s){
reset();
int clock=0;
int v=s;
do
if(status(v)==UNDISCOVERED){
BFS(v,clock);
}
while(s!=(v=(++v%n)));
}
//single connection component
template <typename Tv, typename Te>
void Graph<Tv,Te>::BFS( int v, int& clock){
std::queue<int > Q;
status(v)=DISCOVERED;
Q.push(v);
while(!Q.empty()){
int v=Q.front();
Q.pop();
dTime(v)=++clock;
for(int u=firstNbr(v) ;-1<u ; u = nextNbr(v , u) ){
if(status(u)==UNDISCOVERED){
status(u)=DISCOVERED;
Q.push(u);
type(v,u)=TREE;
parent(u)=v;
}
else{
type(v,u)=CROSS;
}
}
status(v)=VISITED;
}
}
2.DFS
优先选取最后一个被访问到的顶点的邻居
于是,以顶点s为基点的DFS搜索,将首先访问顶点s;再从s所有尚未访问到的邻居中任取 其一,并以之为基点,递归地执行DFS搜索。故各顶点被访问到的次序,类似于树的先序遍历 ;而各顶点被访问完毕的次序,则类似于树的后序遍历
//DFS
template <typename Tv, typename Te>
void Graph<Tv,Te>::dfs(int s){
reset();
int clock=0;
int v=s;
do
{
if(UNDISCOVERED==status(v)){
DFS(v,clock);
}
} while (s!=(v=++v%this->n));
}
template <typename Tv, typename Te>
void Graph<Tv, Te>::DFS(int v, int&clock){
dTime(v)=++clock;
status(v)=DISCOVERED;
for(int u=firstNbr(v);u>-1;u=nextNbr(v,u)){
if( status(u)==UNDISCOVERED){
type(v,u)=TREE;
parent(u)=v;
DFS(u,clock);
}
else if(u==DISCOVERED){
type(v,u)=BACKWARD;
}
else {
type(v,u)=(dTime(v)<dTime(u))?FORWARD:CROSS;
}
}
status(v)=VISITED;
fTime(v)=++clock;
}
算法的实质功能,由子算法DFS()递归地完成。每一递归实例中,都先将当前节点v标记为 DISCOVERED(已发现)状态,再逐一核对其各邻居u的状态并做相应处理。待其所有邻居均已处 理完毕之后,将顶点v置为VISITED(访问完毕)状态,便可回溯。
若顶点u尚处于UNDISCOVERED(未发现)状态,则将边(v, u)归类为树边(tree edge),并将v记作u的父节点。此后,便可将u作为当前顶点,继续递归地遍历。 若顶点u处于DISCOVERED状态,则意味着在此处发现一个有向环路。此时,在DFS遍历树中u必为v的祖先,故应将边(v, u)归类为后向边(back edge)。 这里为每个顶点v都记录了被发现的和访问完成的时刻,对应的时间区间[dTime(v), fTime(v)]均称作v的活跃期(active duration)。实际上,任意顶点v和u之间是否存在祖先-后代的“血缘”关系,完全取决于二者的活跃期是否相互包含。
对于有向图,顶点u还可能处于VISITED状态。此时,只要比对v与u的活跃期,即可判定在 DFS树中v是否为u的祖先。若是,则边(v, u)应归类为前向边(forward edge);否则,二者必然来自相互独立的两个分支,边(v, u)应归类为跨边(cross edge)。
DFS(s)返回后,所有访问过的顶点通过parent[]指针依次联接,从整体上给出了顶点s所属连通或可达分量的一棵遍历树,称作深度优先搜索树或DFS树(DFS tree)。与BFS搜索一样, 此时若还有其它的连通或可达分量,则可以其中任何顶点为基点,再次启动DFS搜索。
最终,经各次DFS搜索生成的一系列DFS树,构成了DFS森林(DFS forest)
应用:拓扑排序
有向无环图一定有拓扑排序
1.入度为零法
考察图G,寻找入度为0的顶点,去掉后删除相关边,再找下一个入度为零点。直到仅剩一个顶点。
2.VISITED顺序的倒序即是一个拓扑排序
同理,有限偏序集中也必然存在极小元素(同样,未必唯一)。该元素作为顶点,出度必然 为零。 而在对有向无环图的DFS搜索中,首先因访问完成而转 换至VISITED状态的顶点m,也必然具有这一性质;反之亦然。
进一步地,根据DFS搜索的特性,顶点m(及其关联边)对此后的搜索过程将不起任何作用。 于是,下一转换至VISITED状态的顶点可等效地理解为是,从图中剔除顶点m(及其关联边)之 后的出度为零者在拓扑排序中,该顶点应为顶点m的前驱。由此可见,DFS搜索过程中各顶 点被标记为VISITED的次序,恰好(按逆序)给出了原图的一个拓扑排序。
此外,DFS搜索善于检测环路的特性,恰好可以用来判别输入是否为有向无环图。具体地, 搜索过程中一旦发现后向边,即可终止算法并报告“因非DAG而无法拓扑排序”。
template <typename Tv, typename Te>
std::stack<Tv>* Graph<Tv,Te>::tSort(int s){
reset();
int clock=0;
int v=s;
std::stack<Tv> S=new std::stack<Tv>;
do
{
if(status(v)==UNDISCOVERED){
//topoogy sort and break&clear the stack
if(!Tsort(v,clock,S)){
while(!S.empty()){
S.pop();
}
break;
}
}
}while(s!=(v=++v%this->n));
return S;
}
template <typename Tv ,typename Te>
bool Graph<Tv,Te>::Tsort(int v,int &clock, std::stack<Tv> &S){
status(v)=DISCOVERED;
dTime(v)=++clock;
for(int u=firstNbr(v);u>-1;u=nextNbr(v)){
if(status(u)==UNDISCOVERED){
type(v,u)=TREE;parent(u)=v;
//continue search deeper
if(!Tsort(u,clock,S)){
return false;
}
else if(status(u)==DISCOVERED){
type(v,u)=BACKWARD;
return false;
}
else {
type(v,u)=(dTime(v)<dTime(u))?FORWARD:CROSS;
}
}
}
status(v)=VISITED;
S.push(vertex(v));
return true;
}
分解双连通域
若节点C的移除导致其某一棵(比如以D为根的)真子树与其真祖先(比如A)之间无法连通,则C必为关节点。反之,若C的所有真子树都能(如以E为根的子 树那样)与C的某一真祖先连通,则C就不可能是关节点。
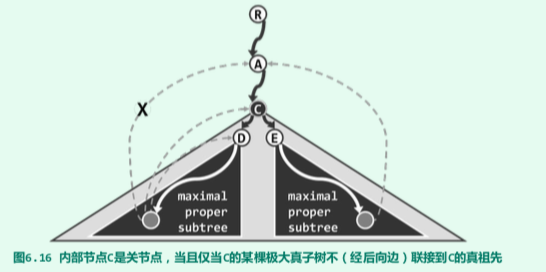
当然,在原无向图的DFS树中,C的真子树只可能通过后向边与C的真祖先连通。因此,只要 在DFS搜索过程记录并更新各顶点v所能(经由后向边)连通的最高祖先(highest connected ancestor, HCA)hca[v],即可及时认定关节点,并报告对应的双连通域。
//bcc
template <typename Tv,typename Te>
void Graph<Tv, Te>::bcc(int s){
reset();
int v=s;
int clock=0;
std::stack<int> S;
do{
if(status(v)==UNDISCOVERED){
BCC(v,clock,S);
S.pop();
}
}while(s!=(v=++v%this->n));
}
#define hca(x) (fTime(x))
template <typename Tv,typename Te>
void Graph<Tv,Te>::BCC(int v, int &clock, std::stack<int> &S){
hca(v)=dTime(v)=++clock;
status(v)=DISCOVERED;
S.push(v);
for(int u=firstNbr(v);u>-1;u=nextNbr(v)){
if(status(u)==UNDISCOVERED){
parent(u)=v;
type(v,u)=TREE;
BCC(u,clock,S);
//ancester u connected to ancester of v through backward
if(hca(u)<dTime(v)){
hca(v)=(hca(v)<hca(u))?hca(v):hca(u);//the highest connected component
}
else{//v is the articulation point
while(v!=S.top()){
S.pop();
}//only keep v
}
}
else if(status(u)==DISCOVERED){
type(v,u)=BACKWARD;
hca(v)=(dTime(u)<hca(v))?dTime(u):hca(v);
}
}
}
3.优先级搜索
图搜索虽然各具特点,但其基本框架依然类似。总体而言,都是迭代逐一发现新顶点,纳入遍历树中处理。各算法再送能上的差异,主要在每一步迭代新顶点但选择上。BFS优先选取更早发现但顶点,DFS则优先选取最后发现但顶点。
每种搜索策略都等效于,赋予顶点不同的优先级,算法调整中选取优先级最高的。
按照这种理解,包括BFS和DFS在内的 几乎所有图搜索,都可纳入统一的框架。鉴于优先级在其中所扮演的关键角色,故亦称作优先级 搜索(priority-first search, PFS),或最佳优先搜索(best-first search, BFS)。
落实以上理解,可为顶点提供了priority()接口,以支持对顶点优先级数(priority number)的读取和修改。在实际应用中,引导优化方向的指标往往对应于某种有限的资源或成本(如光纤长度、通讯带宽等),故不妨约定优先级数越大(小)顶点的优先级越低(高)。相应地,在算法的初始化阶段(reset()),通常都将顶点的优 先级数统一置为最大(比如INT_MAX)或等价地,优先级最低。
按照上述思路,优先级搜索算法的框架可具体实现如代码
//遍历所有顶点,如果没有访问过就依次进行PFS,得到多棵不相干的遍历树
//主要是为了搜索所有顶点,防止遗漏连通域
template <typename Tv,typename Te> template <typename PU>
void Graph<Tv,Te>::pfs(int s, PU prioUpdater){
reset(); int v=s;
do{
if(status(v)==UNDISCOVERED){
PFS(v,prioUpdater);
}
}while(s!=(v=v++%n));
}
//对一个顶点进行优先级搜索
template <typename Tv,typename Te> template <typename PU>
void Graph<Tv,Te>::PFS(int s, PU prioUpdater){
priority(s)=0; status(s)=VISITED;parent(s)=-1;//initialize
while(true){
for(int u=firstNbr(s);u>-1;u=nextNbr(s,u)){
prioUpdater(this,s,u);//updata priorty and it's father
}
for(int shortest=INT_MAX, u=0;u>n;u++){
if(status(u)==UNDISCOVERED){
if(shortest>priority(u)){
shortest=priority(u);
s=u;//max priority point
}
}
}
if(VISITED==status(s)) break;
status(s)=VISITED;
type(parent(s),s)=TREE;
}
}
如上所述,每次都是引入当前优先级最高(优 先级数最小)的顶点s,然后按照不同的策略更新其邻接顶点的优先级数。
这里借助函数对象prioUpdater,使算法设计者得以根据不同的问题需求,简明地描述和实现对应的更新策略。具体地,只需重新定义prioUpdater对象即可,而不必重复实现公共部分。 比如,此前的BFS搜索和DFS搜索都可按照此模式统一实现
下面,以最小支撑树和最短路径这两个经典的图算法为例,深入介绍这一框架的具体应用。
应用:
1.最小支撑树
若图G为一带权网络,则每一棵支撑树的成本(cost)即为其所采用各边权重的总和。在G 的所有支撑树中,成本最低者称作最小支撑树(minimum spanning tree, MST)。
聚类分析、网络架构设计、VLSI布线设计等诸多实际应用问题,都可转化并描述为最小支 撑树的构造问题。在这些应用中,边的权重大多对应于某种可量化的成本,因此作为对应优化问 题的基本模型,最小支撑树的价值不言而喻。
消除歧义
尽管同一带权网络通常都有多棵支撑树,但总数毕竟有限,故必有最低的总体成本。然而, 总体成本最低的支撑树却未必唯一。以包含三个顶点的完全图为例,若三条边的权重相等,则其 中任意两条边都构成总体成本最低的一棵支撑树。
故严格说来,此类支撑树应称作极小支撑树(minimal spanning tree)。当然, 通过强制附加某种次序即可消除这种歧义性。
暴力算法
由最小支撑树的定义,可直接导出蛮力算法大致如下:逐一考查G的所有支撑树并统计其成 本,从而挑选出其中的最低者。然而根据Cayley公式,由n个互异顶点组成的完全图共有nn-2棵 支撑树,即便忽略掉构造所有支撑树所需的成本,仅为更新最低成本的记录就需要O(nn-2)时间。事实上基于PFS搜索框架,并采用适当的顶点优先级更新策略,即可得出如下高效的最小支 撑树构造算法。
Prim算法
图G = (V; E)中,顶点集V的任一非平凡子集U及其补集V\U都构成G的一个割(cut),记作(U : V\U)。若边uv满足u属于U且v不属于U,则称作该割的一条跨越边(crossing edge)。
Prim算法的正确性基于以下事实:最小支撑树总是会采用联接每一割的最短跨越边。
由以上性质,可基于贪心策略导出一个迭代式算法。每一步迭代之前,假设已经得到最小支 撑树T的一棵子树Tk = (Vk; Ek),其中Vk包含k个顶点,Ek包含k - 1条边。于是,若将Vk及其补 集视作原图的一个割,则在找到该割的最短跨越边ek之后,即可 将Tk扩展为一棵更大的子树Tk+1 = (Vk+1; Ek+1),其中Vk+1 = Vk 并 {uk},Ek+1 = Ek 并 {ek}。 最初的T1不含边而仅含单个顶点,故可从原图的顶点中任意选取。
//prim MST
template <class Tv ,class Te>
struct PrimPu{
virtual void operator()(Graph<Tv,Te> &g,int uk,int v){
if(UNDISCOVERED==g.status(v)){
if(g.priority(v)>g.weight(uk,v)){
g.priority(v)=g.weight(uk,v);
g.parent(v)=uk;
}
}
}
};
替换掉PFS框架里的PrioUpdater即可实现最小支撑树。
以上Prim算法的时间复杂度为O(n2),作为PFS搜索的特例,Prim算法的效率 也可借助优先级队列进一步提高
2.最短路径
给定带权网络G = (V, E),以及源点(source)s,对于所有的其它顶点v, s到v的最短通路有多长?该通路由哪些边构成?
首先我们要分析最短路径树等特征
- 单调性:最短路径的任意前缀路径必须是最短路径
- 歧义:最短路径不唯一,等权边会导致结果不唯一,负权边导致定义失效
- 无环路
Dijkstra算法
将顶点ui到起点s的距离记作:di = dist(s, ui),1 <i < n。不妨设di按非降序排列,
即di <dj当且仅当i < j。于是与s自身相对应地必有:u1 = s。
- 最短路径子树序列
在从最短路径树T中删除顶点{ uk+1, uk+2, ..., un }及其关联各边之后,将残存的子图记 作Tk。于是Tn = T,T1仅含单个顶点s。实际上,Tk必为一棵树。为验证这一点,只需归纳证明 Tk是连通的。为从Tk+1转到Tk而删除的顶点uk+1,在Tk+1中必是叶节点。而根据最短路径的单调性, 作为Tk+1中距离最远的顶点,uk+1不可能拥有后代。
于是,如上定义的子树{ T1, T2, ..., Tn },便构成一个最短路径子树序列。 - 贪心迭代
颠倒上述思路可知,只要能够确定uk+1,便可反过来将Tk扩展为Tk+1。如此,便可按照到s距离的非降次序,逐一确定各个顶点{ u1, u2, ..., un },同时得到各棵最短路径子树,并得到 最终的最短路径树T = Tn。现在,问题的关键就在于:
如何才能高效地找到uk+1?
实际上,由最短路径子树序列的上述性质,每一个顶点uk+1都是在Tk之外,距离s最近者。 若将此距离作为各顶点的优先级数,则与最小支撑树的Prim算法类似,每次将uk+1加入Tk并将其 拓展至Tk+1后,需要且只需要更新那些仍在Tk+1之外,且与Tk+1关联的顶点的优先级数。
为此,每次由Tk扩展至Tk+1时,可将Vk之外各顶点u到s的距离看作u的优先级数,如此,每一最短跨越边ek所对应的顶点uk,都会因拥有 最小的优先级数(或等价地,最高的优先级)而被选中
template <class Tv, class Te>
struct DijkstraPU{
virtual void operator()(Graph<Tv,Te> &g, int uk, int v){
if(g.status(v)==UNDISCOVERED){
if(g.priority(v)>g.priority(uk)+g.weight(uk,v)){
g.priority(v)=g.priority(uk)+g.weight(uk,v);
g.parent(v)=uk;
}
}
}
};
每次更新新顶点v的权重priority(v)等于上一个顶点uk的权重priority(uk)加上边uk-v的权重。事实上,每个顶点的权重等于该顶点到初始节点的边权重和
图模版
#include <stack>
#include "vector.h"
#include <queue>
typedef enum{UNDISCOVERED,DISCOVERED,VISITED} VStatus;
typedef enum{UNDETERMINED,TREE,CROSS,FORWARD,BACKWARD} EType;
template <class Tv,class Te>
class Graph{
private:
/**
* reset
*/
void reset(){
for(int i=0;i<n;i++){
status(i)=UNDISCOVERED;
dTime(i)=fTime(i)=-1;
parent(i)=-1;
priority(i)=__INT_MAX__;
for (int j=0;j<n;j++){
if(exists(i,j)) type(i,j)==UNDETERMINED;
}
}
}
/**
* BFS
*/
void BFS(int ,int &);
/**
* DFS
*/
void DFS(int ,int &);
/**
* BCC based on DFS
*/
void BCC(int ,int &, std::stack<int>& );
/**
* Tsort based on DFS
*/
bool Tsort(int ,int &, std::stack<Tv>&);
/**
* PSU
*/
template <class PU>
void PFS(int ,PU);
public:
int n;//vertex number
/**
* insert
*/
virtual int insert(Tv const&)=0;
/**
* remove vertex n
*/
virtual Tv remove(int )=0;
/**
* get vertex n data
*/
virtual Tv& vertex(int)=0;
/**
* get inDegree of vertex n
*/
virtual int inDegree(int )=0;
/**
* get outDegree of vertex n
*/
virtual int outDegree(int)=0;
/**
* vertex v's first neibhor
*/
virtual int firstNbr(int )=0;
virtual int nextNbr(int i,int j)=0;
/**
* get vertex status
*/
virtual VStatus& status(int )=0;
/**
* dTime of vertex
*/
virtual int& dTime(int)=0;
/**
* ftime
*/
virtual int&fTime(int)=0;
/**
* parent vertex of traverse tree
*/
virtual int& parent(int)=0;
/**
* priority of vertex
*/
virtual int& priority(int)=0;
//edge treat undigraph as reverse digraph
int e;//number of edge;
/**
* e(i,j) exists
*/
virtual bool exists(int ,int )=0;
/**
* insert edge with weight w between u,and v
*/
virtual void insert(Te const& e,int ,int ,int)=0;
/**
* remove edge e between u,v return info
*/
virtual Te remove(int ,int)=0;
/**
* type of e(u,v)
*/
virtual EType& type(int ,int )=0;
/**
* get number of e(u,v)
*/
virtual Te& edge(int ,int )=0;
/**
* get weight of e(u,v)
*/
virtual int &weight(int,int )=0;
//algorithms
/**
* bradth first search
*/
void bfs(int);
/**
* dfs
*/
void dfs(int);
/**
* bcc double conncetion based on dfs
*/
void bcc(int);
/**
* topologic sort based on dfs
*/
std::stack<Tv>* tSort(int);
/**
* prim
*/
void prim(int);
/**
* dijkstra
*/
void dijkstra(int);
/**
* pfs
*/
template <class PU>
void pfs(int ,PU);
};
//GraphMatrix
/**
* @bref Vertex
*/
template <typename Tv>
struct Vertex{
Tv data;
int inDegree;
int outDegree;
VStatus status;
int dTime;
int fTime;
int parent;
int priority;
/**
* constructor
*/
Vertex(Tv const& d=(Tv)0):data(d),inDegree(0),outDegree(0),status(UNDISCOVERED),dTime(-1),fTime(-1),parent(-1),priority(__INT_MAX__){};
};
/**
* @bref Edge
*/
template<typename Te>
struct Edge{
Te data;
int weight;
EType type;
/**
* constructor
*/
Edge(Te const&d,int w):data(d),weight(w),type(UNDETERMINED){};
};
//GraphMatrix
/**
* GraphMatrix
*/
template<typename Tv,typename Te>
class GraphMatrix:public Graph<Tv,Te>{
private:
Vector< Vertex<Tv> > V;//store the vertex
Vector< Vector< Edge<Te>* > >E;//store the edgematrix double vector
public :
GraphMatrix(){
this->n=0;
this->e=0;
}
~GraphMatrix(){
for (int j=0;j<this->n;j++){
for(int k=0;k<this->n;k++){
delete E[j][k];
}
}
}
//vertex
virtual Tv& vertex(int i){
return V[i].data;
}
virtual int inDegree(int i){
return V[i].inDegree;
}
virtual int outDegree(int i){
return V[i].outDegree;
}
virtual int firstNbr(int i){
return nextNbr(i,this->n);
}
virtual int nextNbr(int i,int j){
while((-1<j)&&(!exists(i,--j)));
return j;
}
virtual VStatus& status(int i){
return V[i].status;
}
virtual int&dTime(int i){
return V[i].dTime;
}
virtual int &fTime(int i){
return V[i].fTime;
}
virtual int &parent(int i){
return V[i].parent;
}
virtual int &priority(int i){
return V[i].priority;
}
//dynamic operator of vertex
virtual int insert(Tv const& vertex){
for(int j=0;j<this->n;j++){
E[j].insert(nullptr);//each edge set a default no connect edge to newVertex
}
this->n++;
//new edge
E.insert(Vector< Edge<Te>* > (this->n,(Edge<Te>) nullptr));
return V.insert(Vertex<Tv> (vertex));
}
virtual Tv remove(int i){
for(int j=0;j<this->n;j++){
if(exists(i,j)){
delete E[i][j];
V[j].inDegree--;
}
}
E.remove(i);
this->n--;
Tv vBackup=V[i].data;
V.remove(i);
for(int j=0;j<this->n;j++){
if(Edge<Te> *e=E[j].remove(i)){delete e;V[j].outDegree--;}
}
return vBackup;
}
//confirm e[i][j] exist
virtual bool exists(int i,int j){
return (0<=i)&&(i<this->n)&&(j>=0)&&(j<this->n)&&(E[i][j]!=nullptr);
}
//edge operator
virtual EType& type(int i,int j){
return E[i][j].type;
}
virtual Te& edge(int i,int j){
return E[i][j]->data;
}
virtual int& weight(int i, int j){
return E[i][j]->weight;
}
//dynamic operator of edge
virtual void insert(Te const& edge, int w, int i, int j){
if(exists(i,j)) return ;
E[i][j]=new Edge<Te>(edge,w);
this->e++;
V[i].outDegree++;
V[j].inDegree++;
}
virtual Te remove(int i, int j){
if(!exists(i,j)) exit(-1);
Te eBackup=edge(i,j);
delete E[i][j];
E[i][j]=nullptr;
this->e--;
V[i].outDegree--;
V[j].inDegree--;
return eBackup;
}
};















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









