







一、亮点
在融合文本和视觉两种模态的时候,通常使用concatenation的方法或者element-wise 乘积or求和,但是我们认为这些方法不如两个向量之间的外积那样具有表现力。与元素积相比,外积计算的是两个向量的所有元素之间的乘法交互。然而由于外积的高维性,通常是不可行的,所以本文提出用多么太紧凑双线性池化(MCB)来高效地表达多模态特征。
并且本文的还有一个亮点在于,对于VQA任务,使用两次MCB——一次用于预测对于空间特征的attention,另一次用于融合文本特征和视觉特征。
通过将图像和文本的表示随机投影到更高维空间(使用Count Sketch),然后在快速傅立叶变换(FFT)空间中使用元素乘积有效地卷积两个向量,可以近似多模态紧凑双线性池化。

二、模型结构
2.1 MCB(Multimodal Compact Bilinear Pooling)
Count Sketch 映射方法:
映射前向量为a (n维)
映射后向量为y (d维)
这里有两个参数数组:
s
∈
{
−
1
,
1
}
n
s∈{\{-1, 1\}}^n
s∈{−1,1}n
h
∈
{
1
,
.
.
.
,
d
}
n
h∈{\{1,...,d\}}^n
h∈{1,...,d}n
s表示第n个元素加的权
h表示第n个元素加到映射后的那个位置
则有:y[h[I]] += a[I] * s[i]
两向量作外积之后的映射等于两向量分别作映射后的卷积,且两个向量的卷积可以使用FFT 快速傅里叶变换代替,即:
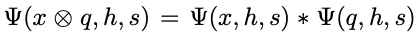
x
′
∗
q
′
=
F
F
T
−
1
(
F
F
T
(
x
′
)
⊙
F
F
T
(
q
′
)
)
x' * q' = FFT^{-1}(FFT(x')⊙FFT(q'))
x′∗q′=FFT−1(FFT(x′)⊙FFT(q′))
整个算法流程为:

2.2 VQA框架

这里需要注意的是,使用了两次MCB——一次用于预测对于空间特征的attention,另一次用于融合文本特征和视觉特征。
同时,对于需要预测的答案,我们也使用一个MCB。

参考资料
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding——EMNLP2016















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









