







一、背景

对于MCB来说,
W
q
W_q
Wq和
W
v
W_v
Wv是固定参数,仅仅
W
o
W_o
Wo是可学习参数。很多参数是固定的,依赖于高维输出特征来保证稳健的性能,这可能会由于巨大的内存使用量而限制其适用性。
对于MLB来说,虽然 W q 、 W v 、 W o W_q、W_v、W_o Wq、Wv、Wo都是可学习的参数,而 T c T_c Tc是固定参数,相较于MUTAN需要学习的参数多,收敛慢。
本文提出MUTAN——基于多模态张量Tucker分解,能够有效的在视觉和文本的双线性交互(Bilinear models)的模型中进行参数化。
二、模型结构

2.1 Tucker分解
3-way张量T的Tucker分解表示是因子矩阵
W
v
,
W
q
,
W
o
W_v,W_q,W_o
Wv,Wq,Wo和核心张量
T
c
T_c
Tc之间的张量积。
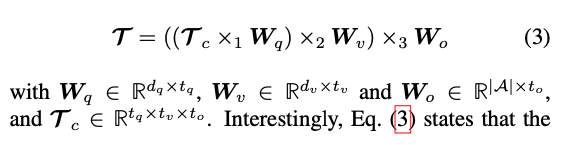
2.2 多模态Tucker融合
经过张量T的Tucker分解方程参数化张量T的权重时,y的输出可以这样表示:
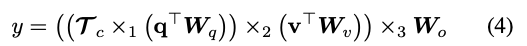
这完全等同于将q和v的投影的完整双线性交互编码为一个潜在对表示z,并使用该潜在代码预测答案,如下:

2.3 解释
W
q
,
W
v
W_q,W_v
Wq,Wv :将问题和图像矢量投影到
t
q
和
t
v
t_q和t_v
tq和tv各个维的空间中,
t
q
或
t
v
t_q或t_v
tq或tv维度越高,模型越复杂。
T
c
T_c
Tc:用于模拟
q
~
\tilde{q}
q~ 和
v
~
\tilde{v}
v~ 之间的相互作用。它从所有相关
q
~
[
i
]
\tilde{q}[i]
q~[i] 和
v
~
[
j
]
\tilde{v}[j]
v~[j]中学习到一个大小为
t
o
t_o
to的向量z的投影。
T
c
T_c
Tc控制着模态间交互的复杂性。
W
o
W_o
Wo:为A中的每个类别的嵌入z对该对进行评分
参考资料
MUTAN:Multimodal Tucker Fusion For Visual Question Answering















 2805
2805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









